1. 论文基本信息
- 标题: SeqXGPT: Sentence-Level AI-Generated Text Detection
- 作者: Pengyu Wang, Linyang Li, Ke Ren, Botian Jiang, Dong Zhang, Xipeng Qiu
- 年份: 2023
- 机构: Fudan University, Shanghai Key Laboratory of Intelligent Information Processing
- 领域关键词: AI-generated text detection, sentence-level detection, large language models, log probability, sequence labeling, convolutional neural network
- 论文链接: https://arxiv.org/abs/2310.08903
2. 前言
我们已经习惯了“整篇文章是不是 AI 写的”这种粗粒度检测,但现实里,人们更常做的是用大模型润色、补写某几段,而不是整篇托管给 AI。现有的 DetectGPT、GPTZero 之类方法,都更擅长识别整篇机器写作,对“一句一句地查”几乎无能为力。SeqXGPT 正好把刀磨到了这个细粒度问题上。
论文想解决的核心问题是:如何在句子级别判断一段文本究竟是人写的,还是被某个 LLM 生成或改写过的。而且不仅要区分“人 vs AI”,还要尽可能识别“是哪一个模型写的”(GPT-2、GPT-Neo、GPT-J、LLaMA、GPT-3.5-turbo 等)。
这件事情之所以有历史意义,在我看来主要有三点:
第一,它把 AIGT detection(AI 文本检测)的颗粒度,从“文档级”推到了“句子级 / 单词级”,真正贴近了 AI 辅助写作的日常用法。
第二,它提出了一种很“黑客”的思路——不用语义特征,而是直接把多个白盒 LLM 的 token log 概率当成“波形特征”,再用 CNN + Transformer 做序列标注,效果却远超语义类 RoBERTa 检测器。
第三,在论文的实验里,SeqXGPT 不仅在句子级检测上明显碾压 DetectGPT、Sniffer 等方法,在传统的文档级任务和 out-of-distribution(OOD)数据上也保持了很强的泛化能力。
对我来说,这篇论文值得写一篇长解读,是因为它代表了一个很有代表性的方向:让检测器站到模型之外,从模型“怎么看这句话”的概率分布入手,而不是从文本内容本身入手。这在大模型时代,是一个非常有启发性的范式。
3. 基础概念铺垫
AI-generated text(AIGT) 就是由大语言模型(LLM)生成或重写的文本。现在常见的检测任务通常是这样的输入输出:给你一篇文章,让你判断它是不是模型写的,或者是不是某个特定模型写的。之前的工作大多停留在“整篇文档”的层面。
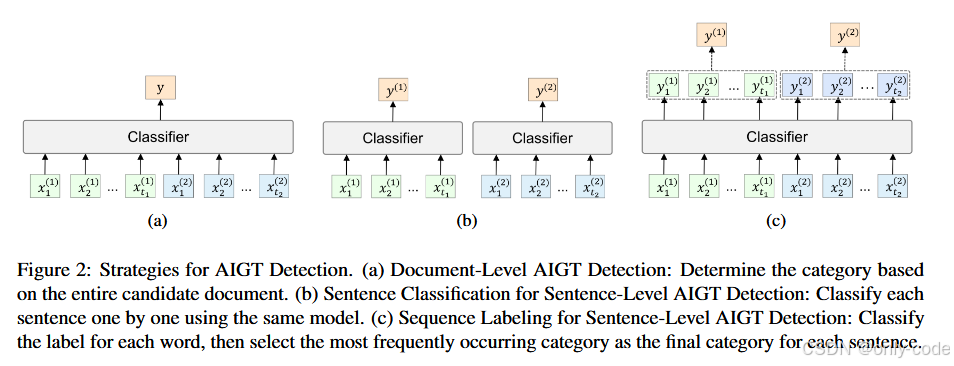
句子级检测则细得多:一篇文章里可能有一部分句子是人写的,一部分是模型生成的,检测器要对每一个句子给出标签。这就意味着:
- 模型要能在很短的文本上工作(有时候甚至只有十几个 token);
- 如果一篇文档里人和 AI 交替出现,检测器还要能在这种“拼接风格”下保持稳定。
论文里还区分了几种检测任务形式:
- Particular-model binary:判断一句话是不是“某个具体模型”(比如 GPT-2)写的 vs 人类写的;
- Mixed-model binary:不管具体是哪个模型,只区分“AI 写的” vs “人写的”;
- Mixed-model multiclass:不仅要判断这句是不是 AI 写的,还要识别是哪一个模型写的。
另一个关键概念是log 概率和困惑度(perplexity)。一句话在一个语言模型下的 log 概率越高,通常代表模型觉得这句话越“自然”,越符合它学到的语言模式。困惑度大致可以理解为“模型对这段话有多困惑”,困惑度低说明模型觉得这段话很顺。之前的检测方法常用的就是这类数值特征。
最后还有一个术语:序列标注(sequence labeling)。和“整句分类”不同,序列标注是对序列中每一个位置打标签,比如经典的命名实体识别会给每个词打 B/I/O 标签(开头、中间、其他)。SeqXGPT 就是先对每个词打标签,再把这些词的标签汇总成句子级别的判断。
4. 历史背景与前置技术
在 SeqXGPT 之前,AI 文本检测主要有两大路线:监督学习型判别器和利用模型内在特征的无监督 / 零样本方法。
监督学习这条线很直观:拿一堆“人写 vs 模型写”的标注数据,直接在 RoBERTa 之类的预训练模型上微调一个分类器。OpenAI 在 GPT-2 输出数据集里就提供过这样的基线,后面还有 Bakhtin 等人的 Real or Fake、Uchendu 等人的 authorship attribution 等工作。问题在于,这类判别器很容易过拟合:在训练模型和训练语料的组合下表现不错,换一批模型、换一个领域,就开始崩。
另一条线是“利用模型本身的信号”,例如:
- GLTR、早期 GPTZero:直接看 token 的 rank、log 概率和困惑度分布;
- DetectGPT:提出了一种非常聪明的做法——对文本做随机扰动,观察原文和扰动版本在模型 log 概率上的“曲率差异”,据此判断是否是模型写的;
- Sniffer:把多个模型的 perplexity 向量当特征,做多模型来源追踪。
这些方法的共同特点是:输入是整篇文档,长度通常至少要上百 token,才能稳定地估计出可靠的统计量。DetectGPT 自己就明确说过,它在短文本上的表现会很差。
与此同时,关于安全和可信度,社区里还有一条平行线:**水印(watermark)**与 对抗攻击 / 有害生成。水印通过在生成时对采样过程做细微偏置,事后再用特定检测器识别;对抗攻击则研究如何“骗过”这些检测器。SeqXGPT 属于另一侧:它假设你可以访问若干白盒 LLM,用它们的概率输出构造新的判别模型,而不是修改生成模型本身。
在这样的背景下,“句子级检测 + 多模型 log 概率作为波形特征”这个组合,就显得既自然又有点大胆。
5. 论文核心贡献
第一,作者把“AI 文本检测”从传统的文档级拓展到了句子级甚至单词级,并且系统地定义了三种任务设定(特定模型二分类、多模型二分类、多模型多分类),围绕这些设定构建了一个新的 benchmark——SeqXGPT-Bench。这个数据集的设计也很贴近现实:一篇文档中既有原始的人类句子,又有由不同 LLM 续写或改写的句子。
第二,论文提出了一个很有意思的模型架构 SeqXGPT:不是再去训练一个“读文本内容”的语义模型,而是把 GPT-2、GPT-Neo、GPT-J、LLaMA 等多个白盒 LLM 在每个 token 上的 log 概率抽出来,对齐到单词,再当成随时间变化的“多通道波形”,交给 CNN + Transformer 做序列标注。模型完全不输入原始词向量,靠的就是这些概率信号。
第三,通过一系列对比实验、OOD 测试和消融实验,作者展示了一个相对稳定的结论:在句子级检测上,传统 perplexity/DetectGPT 在统计上已经无法给出清晰分界线,RoBERTa 这类语义判别器也会严重过拟合,而基于“多模型 log 概率波形 + 序列标注”的 SeqXGPT 在鲁棒性、泛化性上都明显占优,同时还能直接迁移回文档级任务。
6. 方法详解
6.1 整体框架与直觉
先从直觉说起。
一句文本放进不同的 LLM 里,每个模型都会给出一串 token 的条件概率,比如第 i 个 token 的 log 概率是
其中 θ_n 是第 n 个模型的参数。作者的想法是:把这些 log 概率序列当成 4 个“时间序列通道”,类似语音里的多路声波,然后在这些波形上去学模式——人写的句子和模型写的句子,在不同模型眼里的“自然度波形”往往是不同的。
SeqXGPT 的整体流程可以概括成四步:
1. 用多个白盒 LLM(GPT-2-xl、GPT-Neo 2.7B、GPT-J 6B、LLaMA 7B)对整篇文档计算 token 级 log 概率;
2. 把不同模型、不同 token 的 log 概率对齐到统一的 词级序列,得到每个词一个 4 维向量;
3. 把这串“概率波形”送入一个 CNN + Transformer 的特征编码器,得到每个词的上下文表示;
4. 最后用一个线性层做 序列标注,给每个词打上 B-AI / I-AI / B-HUMAN / I-HUMAN 等标签,再把每个句子中出现次数最多的标签合成句子级判断。
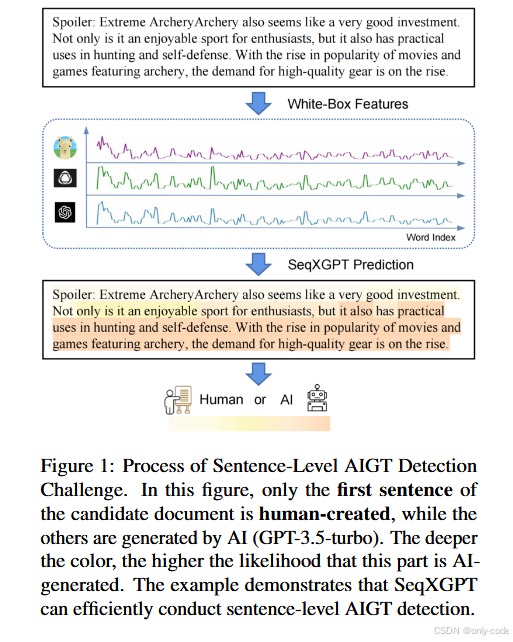
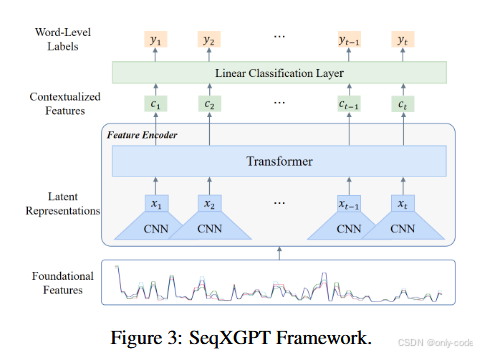
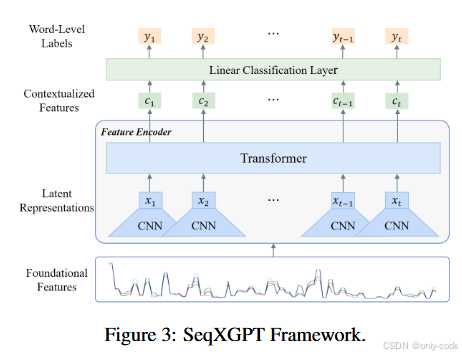
作者在 第 5 页 Figure 3 里画出了完整的框架图,从底部的“Foundational Features(四路波形)”,到中部 CNN/Transformer,再到顶部的 word-level labels,非常直观。
6.2 Perplexity Extraction & Alignment:把 token 概率对齐到词
具体一点说,给定一段原文 S,作者先选定一个模型 θ_n 和它的 tokenizer T_n,把文本编码为 token 序列
然后对每个 token 计算 log 概率
这样就得到一串 token-wise log 概率列表 。
问题在于:不同模型用的 tokenizer 不一样,有的用 byte-level BPE,有的用 SentencePiece,同一句话在不同模型里的 token 切分方式完全不同。直接拼起来会对不上。
作者的解决办法是:
- 先用一个统一的 word-level 分词方式(论文里用了简单的空格分词)得到词序列
- 再把每个模型下的 token 概率 对齐回这些词,也就是把对应到同一个词的子词 token 的 log 概率做合并。具体的对齐逻辑沿用了 Li et al. 2023 提出的算法,论文没有展开细节,只强调这一步可以消除 tokenizer 差异带来的不对齐问题。
对每个模型都做一次这个过程,就能得到 N 路 word-wise log 概率列表
最后,把不同模型的数值在词维度上拼接起来:
整个文档的“基础特征序列”就是
在 SeqXGPT 的设定下,N = 4,所以每个词的特征是一个 4 维向量,随着词的位置变化,这 4 维会画出四条波形。
直觉上,人写的句子和某个模型自己生成的句子,在这个模型眼里的 log 概率分布差异会很大;而在其他模型眼里,又会呈现另一种形态。把这几路信息凑在一起,再交给下游模型,就能学到比较稳健的“机器痕迹”。
6.3 Feature Encoder:CNN 先“卷”出局部模式,Transformer 再补上长程依赖
有了 L 这串基础特征,接下来的任务就是把它变成更抽象、更具判别力的序列表示。因为这里的输入不是传统的词向量,而是“低维、强相关的数值波形”,直接把它扔进一个 Transformer 其实并不好学。
作者的设计是先用 1D 卷积网络 把局部模式提炼出来,再用 Transformer 把长程依赖补上。结构大致是这样:
- 一个 5 层的一维卷积网络
- kernel size 依次为 5, 3, 3, 3, 3
- stride 都是 1
- 输出通道数是 64, 128, 128, 128, 64
- 使用 padding = 'same',所以输出序列长度和输入一致,仅在通道维度上升高
- 接一个 2 层 Transformer 编码器
- 每层 16 个 attention head
- 隐藏维度为 512
- 使用简单的绝对位置编码
卷积模块把 $L$ 映射为 latent 表示
Transformer 再把 Z 变成上下文敏感的表示
这样得到的 就既包含了当前词在各个模型里的概率行为,也包含了整个句子 / 文档范围内的上下文关系。
论文在第 9 页的消融实验里也验证了这个结构的重要性:
- 去掉 Transformer 只靠 CNN,模型在弱模型(GPT-2 等)上的表现还行,但在 GPT-3.5-turbo 这类更“人味”的生成上就明显吃力;
- 只用 Transformer、不用 CNN 基本直接崩盘,模型学到的几乎都是“全部是 human”这样的退化解。
这也从一个侧面说明:CNN 对这种“低维波形特征”特别友好,先把信号卷成更高维、更集中之后,再交给 Transformer 处理上下文,会稳定很多。
6.4 线性分类层与句子级决策
在得到上下文特征 C 之后,作者用了一个非常简洁的头部:
- 对每个词位置 $i$,用线性层 $F(\cdot)$ 把 $c_i$ 映射到若干标签类别:
- 标签采用类似 NER 的 BIO 标注方案,比如 B-AI, I-AI, B-HUMAN, I-HUMAN 等,这样可以在序列上建模“连续的 AI 片段”而不是一个个孤立 token。
训练时就是标准的序列标注训练流程,多分类交叉熵损失,按词位累计。
预测时,SeqXGPT 先得到每个词的标签,然后对每个句子做一次投票:哪个标签在这个句子里出现次数最多,就把这个句子归为对应类别。在多分类场景下(比如区分 GPT-2 / GPT-Neo / GPT-J / LLaMA / GPT-3.5-turbo / Human),标签空间会相应扩展,但决策逻辑一样。
这样的设计有两个细节值得注意:
- 通过 BIO 标签,模型可以对“从某个词开始,后面一串都是 AI 生成”这种模式更敏感;
- 句子级决策是从词级投票聚合而来,因此 模型真正学到的是“每个词的来源模式”,句子只是一个汇总视角。
6.5 与基线方法的对比设定
为了公平比较,作者也把几类经典方法都改造成了句子级版本:
- log p(x) 方法:把每个句子丢进某个语言模型,计算困惑度,画出“AI 句子 vs 人类句子”的困惑度直方图,再手动挑阈值做二分类。
- DetectGPT:同样以句子为单位,对每个句子做若干随机扰动(论文里用了 40 个扰动),计算原句和扰动句的 log 概率 z-score,再画直方图手动选阈值。
- Sniffer:原本是文档级的多模型检测器,作者把它改成“输入单句”的版本;
- RoBERTa 系方法:
- Sent-RoBERTa:把 RoBERTa-base 当成普通的句子分类器;
- Seq-RoBERTa:把 RoBERTa-base 改成序列标注模型(类似 NER),再用“词级投票”得到句子标签。
SeqXGPT 就是在完全不同的信息空间(多模型 log 概率,而非词向量)里,与这些方法正面对比。
7. 实验结果与性能分析
7.1 实验设置简述
作者首先基于 SnifferBench 里的 6000 篇人类文档构建了一个新的句子级数据集 SeqXGPT-Bench。这些文档涵盖了新闻(XSum)、IMDB 评论、网络文本、科学论文(PubMed、Arxiv)、问答资料(SQuAD)等多种体裁。
构造方式是:
- 对每篇人类文档,随机取前 1~3 句作为 prompt;
- 然后用不同的生成模型(GPT-2、GPT-Neo、GPT-J、LLaMA、GPT-3.5-turbo)续写后面的内容;
- 最后得到一篇“前面几句是人写的,后面若干句是某个 LLM 写的”的混合文档。
对每一个生成模型都做一次这样的采样,就能得到 5 份“人类 + 某模型”混合数据,共计 30,000 篇文档。再按 90% / 10% 做训练 / 测试划分。
SeqXGPT 在训练时使用的白盒特征来自 GPT-2-xl、GPT-Neo 2.7B、GPT-J 6B、LLaMA 7B 四个模型;这些模型都在 NVIDIA 4090 上开了推理服务,只用来算 log 概率,不参与文本生成。评估指标使用 Precision、Recall 和 Macro-F1,既看各类的准确率和覆盖率,也看整体平衡表现。
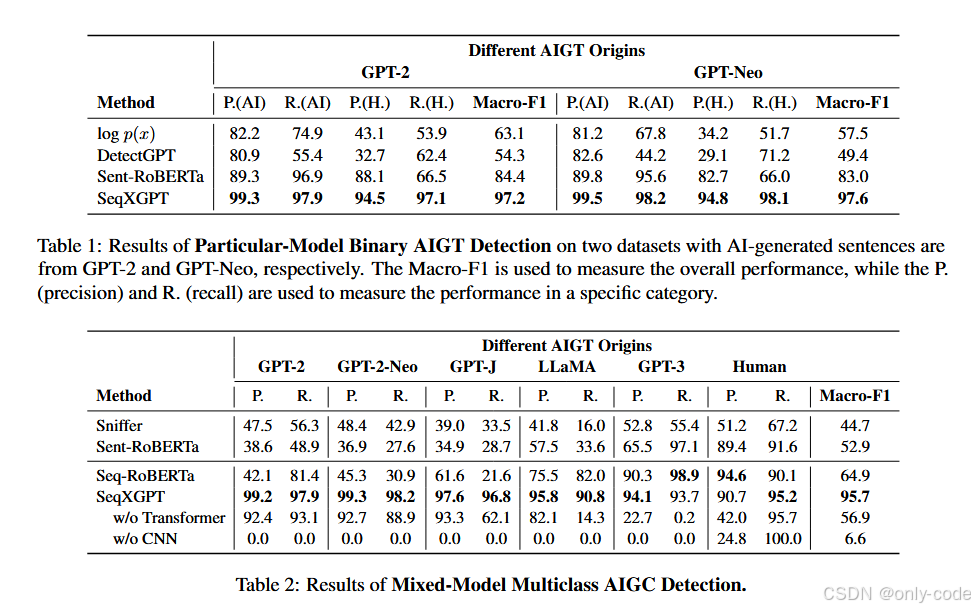
7.2 句子级 Particular-model Binary 检测
在“只针对某一个模型(比如 GPT-2)做二分类”的设定下,作者比较了 log p(x)、DetectGPT、Sent-RoBERTa 和 SeqXGPT。结果非常直观:
- log p(x) 和 DetectGPT 在句子级几乎失效,AI 句子和人类句子的分布峰值高度重叠;
- Sent-RoBERTa 虽然比零样本方法强不少,Macro-F1 在 80 分出头,但仍然明显不稳定;
- SeqXGPT 的 Macro-F1 稳定在 97% 左右,两类的 Precision / Recall 都接近 95%~99%。
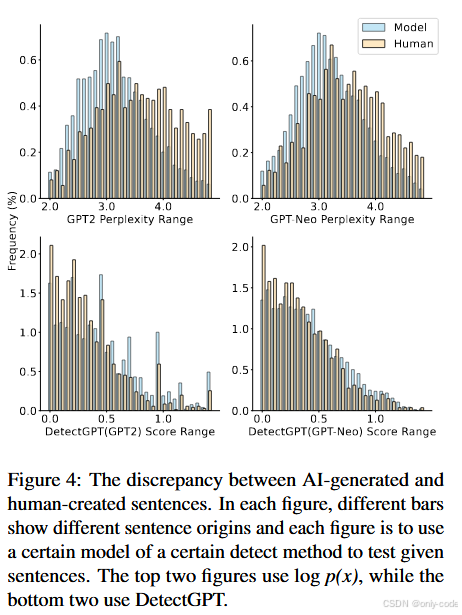
- 上面两张图画的是 GPT-2 / GPT-Neo 下的困惑度分布;
- 下面两张图画的是 DetectGPT 的 z-score 分布;
你会发现,人写和 AI 写的句子在这些数值轴上几乎是“挤在一起”的,很难找到一个好阈值把它们分开。
这说明一个现实:在句子级别上,简单的困惑度或 DetectGPT 风格的统计信号已经不够用了,需要更复杂的模式挖掘。SeqXGPT 通过 CNN + Transformer 在多模型波形上挖到的,就是这样一种更细的模式。
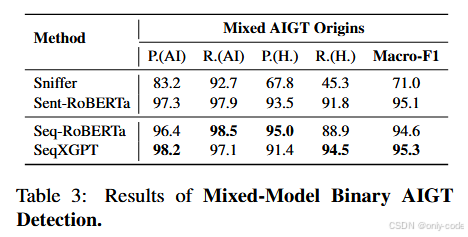
7.3 Mixed-model Binary:只管是不是 AI 写的
在“多个模型混在一起,只区分 AI vs Human”的设定下,作者比较了 Sniffer、Sent-RoBERTa、Seq-RoBERTa 和 SeqXGPT。
- Sniffer 的宏 F1 在 71 左右,主要因为它原本就是为文档级、多模型任务设计的,改成句子级后效果明显下降;
- 两个 RoBERTa 版本表现都不错,Macro-F1 在 94~95 左右,其中 Seq-RoBERTa 略优于 Sent-RoBERTa,说明“序列标注 + 上下文信息”对于句子级检测确实有帮助;
- SeqXGPT 则是四者中最好的,Macro-F1 大约 95.3,特别是在 AI 类别上的 Precision / Recall 都非常高。
这里有一个有趣的细节:RoBERTa 系方法在区分“人写 vs GPT-3.5-turbo”时表现相对更强,因为后者语义上更自然、更接近训练数据中的分布;而对 GPT-2 / GPT-Neo 的句子,它们反而没那么敏感。这和 Li 等人在 Sniffer 里观察到的现象是一致的。
7.4 Mixed-model Multiclass:顺便还要猜“是哪个模型写的”
在最难的多分类设定下(GPT-2 / GPT-Neo / GPT-J / LLaMA / GPT-3.5 / Human 六类),差距被进一步放大:
- Sniffer 的 Macro-F1 只有大约 45;
- Sent-RoBERTa 跌到 53 左右;
- Seq-RoBERTa 即使用了序列标注,也只有 64.9;
- SeqXGPT 直接把 Macro-F1 拉到了 95.7,对每一类的 Precision / Recall 都在 90% 以上。
这里最直观的感受是:多模型 log 概率确实携带了“是哪一个模型写的”这种细致风格信息,而且这些信息靠语义模型是很难挖出来的。
7.5 文档级检测:句子模型反向“打包”成文档模型
作者还专门构建了一个文档级数据集:从 SeqXGPT-Bench 的测试集中抽 200 篇人类文档,用第一句作为 prompt 让不同模型续写整篇文章,再和原始文档混在一起做“整篇文档分类”。
在这个任务上,他们把句子级模型简单地“打包”成文档级:
- 对于句子分类模型,直接看每篇文档里哪种句子标签出现得最多;
- 对于序列标注模型,则先做词级标注,再聚合。
结果是:
- Sniffer 在这个任务上明显更舒服,Macro-F1 大约 67.5;
- RoBERTa 两个版本在某些类别上表现很不稳定;
- SeqXGPT 的 Macro-F1 约为 94.2,在绝大多数模型来源上都接近完美分类,只是在人类文档上略弱一些(主要是因为训练集里人类部分只取了前 1~3 句,样本相对更少)。
这说明一句话:如果句子级检测器设计得好,反向拼成文档级检测器完全是顺手的事情。
7.6 OOD 实验:在 TriviaQA 上的泛化
为了测试泛化能力,作者又用 TriviaQA 的 200 篇 evidence 文档构造了一个 OOD 版本的句子级数据集,生成过程和之前类似,只是底层人类文档换成了另一套来源。
在这个 OOD 测试上:
- Sniffer 和 Sent-RoBERTa 的表现明显崩塌,Macro-F1 分别只有 36 和 35 左右,尤其是在 GPT-3.5-turbo 和 Human 上几乎分不清;
- Seq-RoBERTa 虽然比 Sent-RoBERTa 好不少,但 Macro-F1 也只是 60 左右;
- SeqXGPT 依然保持在 92.8 左右的 Macro-F1,各类 Precision / Recall 只有轻微下降。
作者的结论很直接:基于语义的判别器极易过拟合到训练语料和特定生成模型上,而基于多模型概率的“波形特征”在迁移到新领域、新体裁时更加稳健。
7.7 消融分析:CNN 与 Transformer 分别在做什么
最后的消融实验进一步解释了 SeqXGPT 结构的合理性:
- 只保留 Transformer、去掉 CNN:模型几乎学不会任何有用模式,倾向于把所有句子都判成 Human,Macro-F1 只有个位数;
- 只保留 CNN、去掉 Transformer:在 GPT-2 这类简单模型上的句子还能勉强分开,但面对 GPT-3.5-turbo 的生成就非常吃力。
作者给出的解释是:
- 多个模型的 log 概率波形之间高度相关、维度又很低,Transformer 很难在这种输入上直接学到稳定的注意模式;
- CNN 更适合先从这些“波形”里提取局部统计结构,再交给 Transformer 把不同位置的模式串起来。
这一点在实践上也挺有启发意义:如果输入本身是低维数值序列,而不是高维嵌入向量,先做一层卷积再上 Transformer 往往更稳。
8. 亮点与创新点总结
第一,问题设定本身就很“现实主义”。 绝大多数实际场景都是“部分 AI 写作”:学生只用模型改写引言,作者用模型润色摘要,程序员让模型补齐一部分注释……文档级“是不是 AI 写的”这个问题其实有点理想化,而句子级 / 片段级检测才是未来会越来越常见的需求。SeqXGPT 在任务定义和 benchmark 构造上踩得非常准。
第二,它把“多模型 log 概率波形”当成主角,而不是补充特征。 之前的工作往往在语义向量上做文章,把 perplexity 当成一个附属指标;SeqXGPT 则反过来,只用 log 概率,不用任何语义嵌入,结果还更稳。这给人一种很强烈的信号:从模型的角度看世界,未必需要阅读文本本身。
第三,方法结构简单但风格很鲜明。 只有 CNN + Transformer + 线性层,没有复杂的对比学习、辅助损失,但通过合理的特征设计(多模型概率)和任务设计(序列标注 + BIO 标签),就让模型在多个任务、多个分布上都保持了很漂亮的性能。
第四,它兼具“可扩展性”和“可迁移性”。 只要你能拿到更多白盒模型的 log 概率,就能把特征维度扩展得更高;只要对新的语料做同样的混合构造,模型就可以迁移到新的领域、新的语言风格上。整个方案更像是一个 “围绕 LLM 生态搭建的检测框架”,而不仅仅是一个单一模型。
最后,方法本身很有范式意义。 它把语音里“把波形搞干净再做序列建模”的思路搬到了文本概率空间,让人意识到:文本不一定要通过 embedding 才能交给深度模型,模型内部的统计行为本身就是一种可学习的信号。
9. 局限性与不足
尽管 SeqXGPT 的表现非常亮眼,论文本身也在最后一节里坦诚了一些限制,我个人读完之后还有几点额外的感受。
首先,它强依赖于白盒模型的 log 概率。这意味着:
- 检测器要能访问 GPT-2-xl、GPT-Neo、GPT-J、LLaMA 等模型的内部输出,现实部署时需要足够的算力和模型访问权限;
- 对于完全黑盒、只提供 API 文本输出、不提供 logprob 的商用模型(比如某些闭源服务),这条路就走不通,或者需要做大量近似工作。
其次,论文刻意不使用语义特征,这既是优点也是潜在短板。在大多数场景下,“只看概率波形”已经足够区分 AI 和人类;但在一些更微妙的场景下,比如人类模仿模型风格写作,或者模型刻意模仿某个作者的语言习惯,没有语义信息可能会丢掉一些有用线索。作者也在 Limitations 里提到,引入语义特征是未来的一个方向。
第三,数据构造还是比较理想化的:
- 每篇文档只有两类来源:开头几句是人写的,后面是单一模型续写;
- 真实世界里,文档可能被多次编辑,句子可能被不同工具反复改写,甚至有人类再编辑 AI 结果;
- 在这种更复杂的“多轮混合”场景下,SeqXGPT 的表现如何,目前还没有实验支持。
第四,计算成本和部署复杂度不低。对每篇待检测文档,至少要在四个大模型上跑一遍前向,算出 token 级 log 概率,然后再跑一遍 SeqXGPT 本身。这在研究环境里可以接受,但在大规模线上服务里,成本会是一个很现实的问题。
第五,语言和体裁的广度仍然有限。SeqXGPT-Bench 覆盖了新闻、评论、科学文章、问答等多种英文体裁,外加 TriviaQA 的 OOD 测试,但还没有涉及代码、对话、多语言等场景。考虑到不同语言的 token 化方式差异更大,对齐算法和特征分布也可能会发生明显变化。
最后,模型在“人类文章”上的表现还有提升空间。在文档级任务里,SeqXGPT 对人类文档的 Recall 略低,论文解释为训练阶段人类样本主要来自前 1~3 句,没有覆盖更复杂的长文结构。这也提醒我们:检测器本身也需要足够多样、足够丰富的人类写作样本做支撑,否则容易把“没见过的正常写法”误判成 AI。
10. 全文总结
回头看,SeqXGPT 做的事情其实很明确:在 AI 辅助写作越来越普遍的今天,作者试图把“AI 文本检测”这件事从粗糙的文档级、模型级判断,细化到“每一句话、每一个词到底是谁写的”。
为此,他们构建了一个贴近现实的混合数据集 SeqXGPT-Bench,覆盖多种模型、多种体裁,并提出了一个完全基于多模型 log 概率波形的序列标注框架 SeqXGPT。这个框架通过 CNN + Transformer 把概率信号变成可区分的模式,在句子级、文档级、OOD 等多个任务上都压制了现有方法。
在读完实验和消融之后,我最大的感受是:当我们试图检测大模型写作时,也许不必总是从“文本本身”下手,而是可以退一步,从“模型是怎么评价这段文本的”入手。在这个意义上,SeqXGPT 提供的不是一个终极方案,而是一种很值得记住的视角。
如果只用几句来概括这篇论文带来的观念变化,我会说:
- AI 文本检测应该向更细粒度(句子级、词级)发展;
- 多模型的概率行为,本身就是一种极具判别力的特征;
- 在这种波形特征上,简单的 CNN + Transformer 就足以支撑一个强大的检测器;
- 未来的检测工具,很可能会是“围绕一群 LLM 搭建的外置感应系统”,而 SeqXGPT 已经是这条路上的一个重要样本。
《SeqXGPT:Sentence-Level AI-Generated Text Detection —— 把大模型的“波形”变成测谎仪》 是转载文章,点击查看原文。
