目录
1、概念
2、核心体系结构
3、Collection接口及实现
3.1 List接口(有序)
3.2 Set接口(去重)
3.3 Queue接口(队列)
4、Map接口及实现
5、迭代器和工具类
5.1 迭代器 (Iterator)
5.2 比较器(Comparator)
5.3 工具类(Collections)
6、集合选择
1、概念
Java集合框架是一个统一的架构,用于表示和操作集合。它包含:
- 接口:代表不同类型的集合,如
List,Set,Map,它们定义了集合的基本操作。 - 实现:这些接口的具体实现类,通常是可复用的数据结构,如
ArrayList,HashSet,HashMap。 - 算法:对集合执行有用操作的方法,如搜索和排序。这些算法被称为多态的,因为同一个方法可以在不同的接口实现上工作。
核心设计思想:通过接口和实现分离,可以只关注接口编程,而无需关心底层具体的数据结构,从而提高了代码的灵活性和可维护性。
2、核心体系结构
Java集合框架主要分为两大派系:Collection 和 Map。
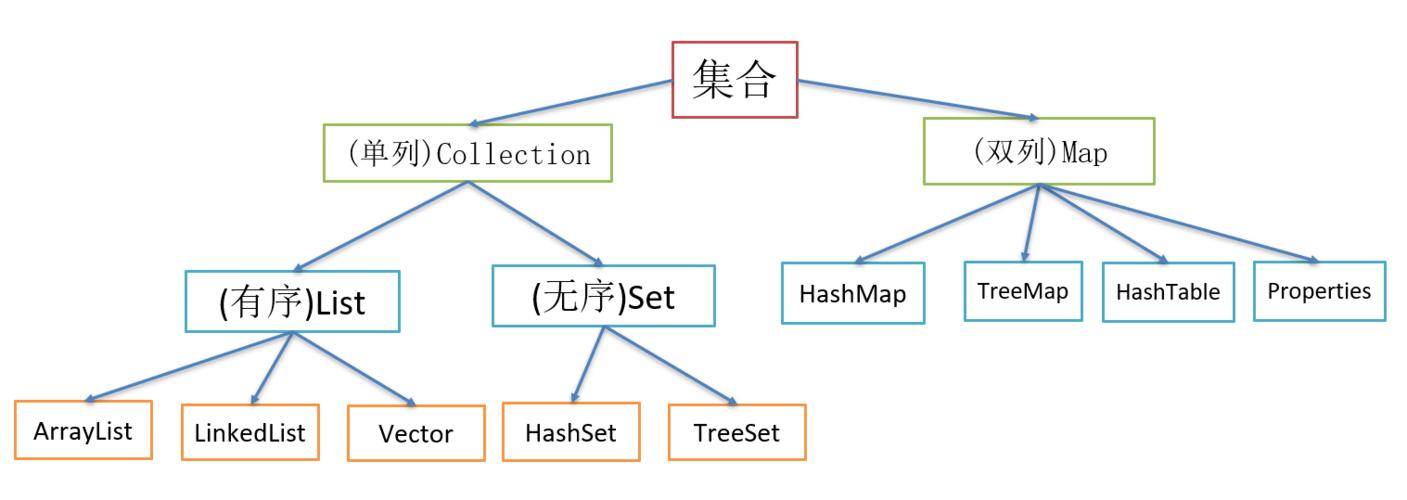
Collection (单列集合):存储一组独立的元素。它有三个主要的子接口
List:有序、可重复 的集合。典型实现:ArrayList,LinkedList,Vector。Set:无序、不可重复 的集合。典型实现:HashSet,LinkedHashSet,TreeSet。Queue:队列,模拟了队列数据结构,通常是“先进先出”(FIFO)。典型实现:LinkedList,PriorityQueue,ArrayDeque。
Map (双列集合):存储键值对 的集合。每个元素都包含一个键和一个值,键不可重复。典型实现:HashMap, LinkedHashMap, TreeMap, Hashtable。
3、Collection接口及实现
3.1 List接口(有序)
| 对比维度 | ArrayList | LinkedList | Vector(不推荐) |
|---|---|---|---|
| 底层原理 | 动态数组 | 双向链表 | 动态数组 |
| 数据存储 | Object[] elementData | 节点 Node<E>(含item, prev, next) | Object[] elementData |
| 主要特点 | 随机访问快(O(1)),尾部操作快;增删慢(需移动元素,O(n)),非线程安全 | 增删快(尤其头尾,O(1)),可作栈、队列、双端队列;随机访问慢(需遍历,O(n)),非线程安全 | 类似ArrayList,但线程安全,多数方法使用synchronized关键字修饰,性能通常低于ArrayList |
| 扩缩容机制 | 默认初始容量10,按约1.5倍(oldCapacity + (oldCapacity >> 1))自动扩容,并将旧数据拷贝过去,可手动ensureCapacity | 无固定初始容量,无需扩容,新增元素时动态创建节点 | 默认初始容量10,可按指定容量增量自动扩容,未指定时默认增长为原来的2倍(oldCapacity * 2) |
| 线程安全实现 | 非线程安全,多线程下可用 Collections.synchronizedList(new ArrayList(...)) 包装 | 非线程安全,多线程下可用 Collections.synchronizedList(new LinkedList(...)) 包装 | 线程安全,通过在方法上使用 synchronized 实现 |
参考:
3.2 Set接口(去重)
| 对比维度 | HashSet | LinkedHashSet | TreeSet |
|---|---|---|---|
| 底层原理 | 基于 HashMap 实现 | 继承自 HashSet,基于 LinkedHashMap 实现 | 基于 TreeMap 实现(红黑树) |
| 数据存储 | HashMap(数组+链表/红黑树) | LinkedHashMap(数组+链表+双向链表) | TreeMap(红黑树) |
| 元素顺序 | 无序 | 插入顺序 或 访问顺序 | 自然顺序 或 Comparator 定制顺序 |
| 主要特点 | 查询最快 O(1),元素唯一性基于 hashCode() 和 equals(),允许 null 元素 | 保持插入顺序,迭代性能好,元素唯一性同 HashSet | 自动排序,支持范围查询,元素唯一性基于 compareTo() 或 compare() |
| 时间复杂度 | 添加、删除、查询平均 O(1) | 添加、删除、查询平均 O(1) | 添加、删除、查询 O(log n) |
| 扩缩容机制 | 同 HashMap,默认初始容量16,负载因子0.75,2倍扩容 | 同 LinkedHashMap,默认初始容量16,负载因子0.75,2倍扩容 | 无固定容量概念,按红黑树节点动态调整 |
| 线程安全实现 | 非线程安全 | 非线程安全 | 非线程安全 |
| null 元素支持 | 允许一个 null | 允许一个 null | 不允许 null(除非自定义 Comparator) |
线程安全:
- 对于非线程安全的 Set,可以通过
Collections.synchronizedSet()进行包装 - 在并发场景下还有其他选择,如
ConcurrentSkipListSet(基于跳表的并发有序 Set)
元素唯一性实现:
- HashSet/LinkedHashSet 依赖
hashCode()和equals()方法 - TreeSet 依赖
compareTo()或compare()方法(返回0视为相等)
参考:
3.3 Queue接口(队列)
| 对比维度 | LinkedList | PriorityQueue | ArrayDeque |
|---|---|---|---|
| 底层原理 | 双向链表 | 二叉堆(最小堆,基于数组) | 循环数组 |
| 数据存储 | Node节点(item, prev, next) | Object[] queue | Object[] elements |
| 元素顺序 | FIFO(队列)或 LIFO(栈) | 按优先级(自然顺序或 Comparator) | FIFO(队列)或 LIFO(栈) |
| 主要特点 | 功能灵活,可作List/Deque/Queue,增删快,查询慢 | 元素按优先级出队,不支持null元素,入队出队O(log n) | 性能优于LinkedList,内存连续,缓存友好,不能存储null |
| 边界特性 | 无界 | 无界 | 无界(但初始容量固定) |
| 线程安全 | 非线程安全 | 非线程安全 | 非线程安全 |
| 扩缩容机制 | 无固定容量,动态创建节点 | 默认初始容量11,按 oldCapacity + (oldCapacity < 64 ? oldCapacity + 2 : oldCapacity >> 1) 扩容 | 最小容量8,按2的幂次扩容(通常翻倍) |
| 时间复杂度 | 入队/出队 O(1),随机访问 O(n) | 入队 O(log n),出队 O(log n),查看队首 O(1) | 入队/出队 O(1) |
| null元素 | 允许 | 不允许 | 不允许 |
| 迭代顺序 | 插入顺序 | 优先级顺序(堆排序) | 插入顺序 |
| 内存占用 | 较高(每个元素需要额外指针) | 较低(数组存储) | 最低(数组存储,无指针开销) |
线程安全:
- 对于非线程安全的 Queue,可以通过
Collections.synchronizedSet()进行包装 - 在并发场景下还有其他选择,如 ConcurrentLinkedDeque(无界,非阻塞,高并发性能好)、LinkedBlockingDeque(可选有界,阻塞操作,吞吐量高)
4、Map接口及实现
| 特性 | HashMap | LinkedHashMap | TreeMap | ConcurrentHashMap |
|---|---|---|---|---|
| 数据结构 | 数组+链表/红黑树 | 继承HashMap,并增加双向链表 | 红黑树 | JDK8+:数组+链表/红黑树 + CAS + synchronized |
| 是否有序 | 不保证顺序 | 插入顺序或访问顺序 | 键的自然顺序或Comparator定制顺序 | 不保证顺序 |
| 键值Null支持 | Key和Value均允许一个null | Key和Value均允许一个null (继承HashMap) | Key和Value均不允许为null | Key和Value均不允许为null |
| 线程安全 | 非安全,需外部同步 | 非安全,需外部同步 | 非安全,需外部同步 | 安全,使用锁分段技术或CAS |
| 扩容机制 | 默认容量16,负载因子0.75;超出阈值(容量*负载因子)时2倍扩容 | 同HashMap | 基于树结构调整,无需传统扩容 | 类似HashMap,但支持并发扩容 |
| 性能特点 | 访问最快,取决于hash函数 | 比HashMap稍慢,因维护链表 | 增删改查 O(log n),因树结构 | 高并发下性能远优于Hashtable |
参考:
5、迭代器和工具类
5.1 迭代器 (Iterator)
所有集合都提供了迭代器,用于遍历集合中的元素。它是一种设计模式,将遍历逻辑与集合本身分离。
1List<String> list = Arrays.asList("A", "B", "C"); 2Iterator<String> iterator = list.iterator(); 3while (iterator.hasNext()) { 4 String element = iterator.next(); 5 System.out.println(element); 6 // 可以在遍历中使用 iterator.remove() 安全地删除元素 7} 8 9// 增强for循环 (foreach) 底层就是使用了迭代器 10for (String s : list) { 11 System.out.println(s); 12}
5.2 比较器(Comparator)
Comparator是Java中的一个函数式接口,位于java.util包中。它用于定义对象的定制排序规则,允许在不修改原始类的情况下,为类对象提供多种不同的比较方式。
返回值规则:
- 负数 (
< 0):当前对象 小于 参数对象 - 零 (
= 0):当前对象 等于 参数对象 - 正数 (
> 0):当前对象 大于 参数对象
1// Comparator使用示例 - 按分数排序 2Comparator<Student> byScore = new Comparator<Student>() { 3 @Override 4 public int compare(Student s1, Student s2) { 5 return Double.compare(s1.getScore(), s2.getScore()); 6 } 7}; 8 9Collections.sort(students, byScore); // 使用Comparator而不是自然排序 10 11// 使用Lambda表达式按分数降序排序 12students.sort((s1, s2) -> Double.compare(s2.getScore(), s1.getScore())); 13 14// 使用Comparator.comparing静态工厂方法,按姓名排序 15students.sort(Comparator.comparing(Student::getName)); 16 17// 多级排序:先按年龄升序,再按分数降序 18Comparator<Student> complexComparator = 19 Comparator.comparing(Student::getAge) // 第一级:年龄升序 20 .thenComparing( 21 Comparator.comparing(Student::getScore).reversed() // 第二级:分数降序 22 ); 23students.sort(complexComparator); 24 25// 处理null值:将null放在最后 26Comparator<Student> nullsLastComparator = Comparator.nullsLast(Comparator.comparing(Student::getName)); 27 28// 自定义逻辑:优秀学生(分数>=90)优先,然后按年龄排序 29Comparator<Student> customComparator = (s1, s2) -> { 30 boolean s1Excellent = s1.getScore() >= 90; 31 boolean s2Excellent = s2.getScore() >= 90; 32 33 if (s1Excellent && !s2Excellent) { 34 return -1; // s1排在s2前面 35 } else if (!s1Excellent && s2Excellent) { 36 return 1; // s1排在s2后面 37 } else { 38 // 都是优秀或都不是优秀,按年龄排序 39 return Integer.compare(s1.getAge(), s2.getAge()); 40 } 41}; 42students.sort(customComparator);
5.3 工具类(Collections)
Collections 类提供了大量静态方法,用于操作或返回集合,非常实用。
- 排序:
Collections.sort(list) - 打乱:
Collections.shuffle(list) - 反转:
Collections.reverse(list) - 查找最大值/最小值:
Collections.max(collection),Collections.min(collection) - 线程安全包装:
Collections.synchronizedList(list),Collections.synchronizedMap(map)(性能不如ConcurrentHashMap等并发集合)
1List<Integer> numbers = new ArrayList<>(Arrays.asList(3, 1, 4, 1, 5, 9)); 2Collections.sort(numbers); // 排序 3System.out.println(numbers); // 输出: [1, 1, 3, 4, 5, 9] 4 5Collections.shuffle(numbers); // 打乱 6System.out.println(numbers); // 输出: [5, 1, 9, 3, 1, 4] (随机) 7 8List<Integer> syncList = Collections.synchronizedList(numbers); // 获取线程安全的List
6、集合选择
| 场景 | 首选接口 | 实现类选择 |
|---|---|---|
| 需要根据索引快速查询 | List | ArrayList |
| 需要频繁在中间插入、删除 | List | LinkedList |
| 需要元素唯一,不关心顺序 | Set | HashSet |
| 需要元素唯一,且保持插入顺序 | Set | LinkedHashSet |
| 需要元素唯一,且需要排序 | Set | TreeSet |
| 存储键值对,需要快速存取 | Map | HashMap |
| 存储键值对,需要按插入/访问顺序 | Map | LinkedHashMap |
| 存储键值对,需要Key排序 | Map | TreeMap |
| 需要队列或栈功能 | Queue/Deque | ArrayDeque, LinkedList |
| 需要多线程环境下的高性能集合 | - | 使用 java.util.concurrent 包下的类,如 ConcurrentHashMap, CopyOnWriteArrayList |
《Java集合框架概述Java:ArrayList的使用Java:LinkedList的使用Java:HashSet的使用Java:TreeSet的使用Java:HashMap的使用》 是转载文章,点击查看原文。

