测试学习记录,仅供参考!
Pytest 框架
七、pytest 丰富的插件系统
可以去安装外部的插件,去使用 pytest 来执行插件;这就是为什么选择使用 pytest 框架的原因,因为 pytest 里面有丰富的插件系统,而 unittest 是没有这些插件的;所以 pytest 要比 unittest 测试框架更加灵活;
例如:
当测试用例很多的时候,可以使用并发执行,可以使用多进程/多线程去执行测试用例,提高测试效率;
测试用例失败重跑插件;在执行测试用例时,由于网络波动、硬件设备等不确定的因素,导致执行测试用例失败,但并不是测试结果测试失败的情况下,可以用到重试运行失败用例重跑的插件;
执行测试用例顺序的插件、生成测试报告的插件、数据参数化等等;
第一个、并发执行(多进程/多线程)
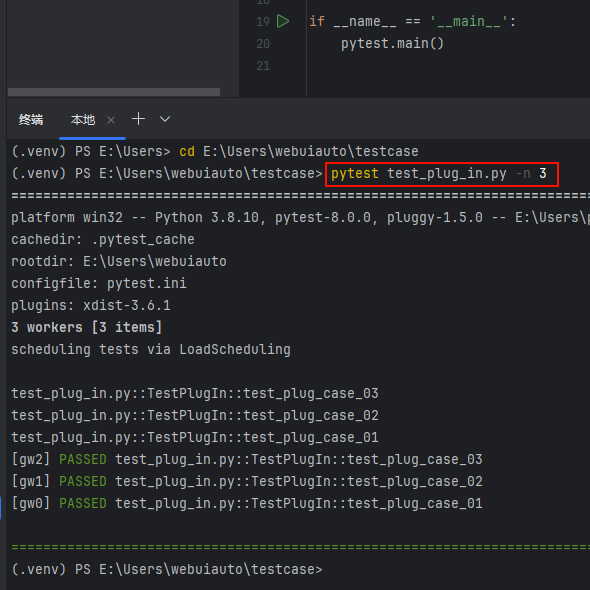
pytest-xdist 提供一个 -n 参数选项设置多进程/线程数量,去设置多少个线程去执行测试用例;使得测试用例可以在多个进程或线程中并发执行,提供测试效率;
安装插件
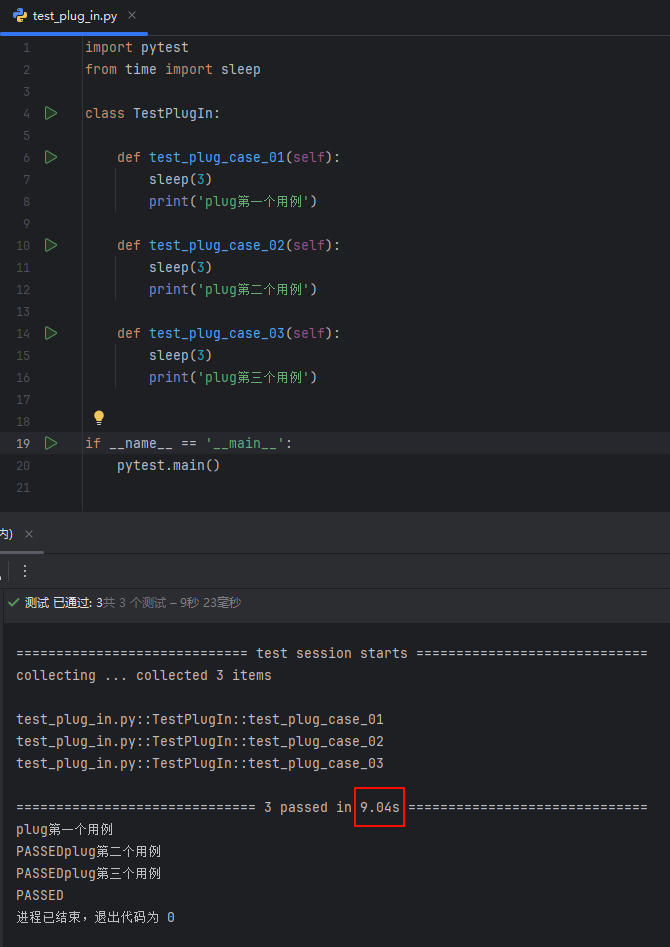
在 main 函数中设置进程数;
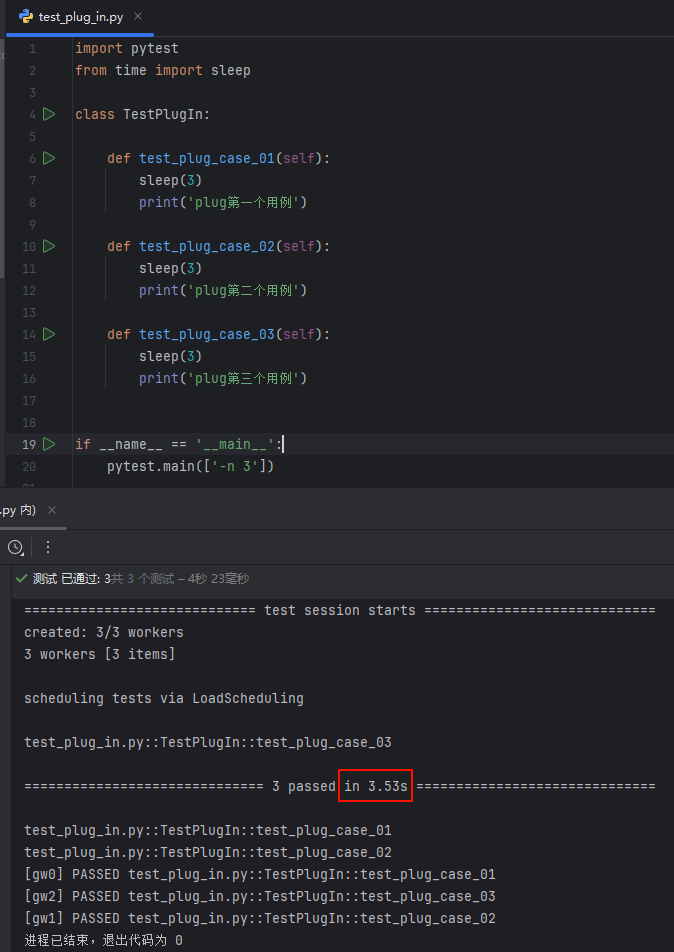
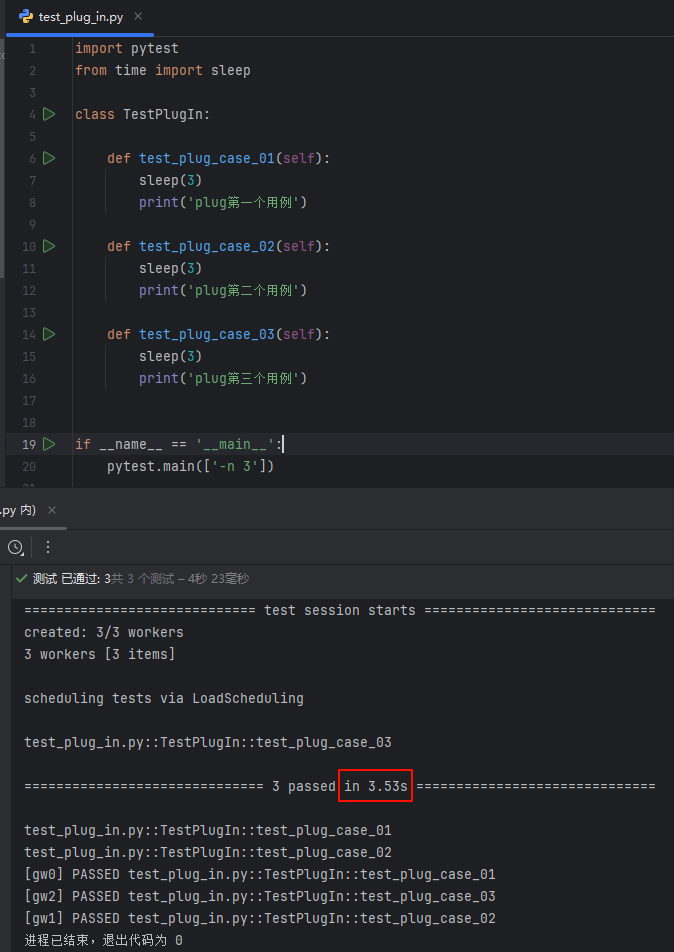
命名行
pytest test_plug_in.py -n 3
配置文件 pytest.ini 中设置,然后再运行 run.py 主方法函数文件;
1[pytest] 2addopts = -vs -n 3 3 4testpaths = ./testcase 5; testpaths = ./other 6 7python_files = test_*.py 8 9python_classes = Test* 10 11python_functions = test_*
第二个、测试用例失败重跑
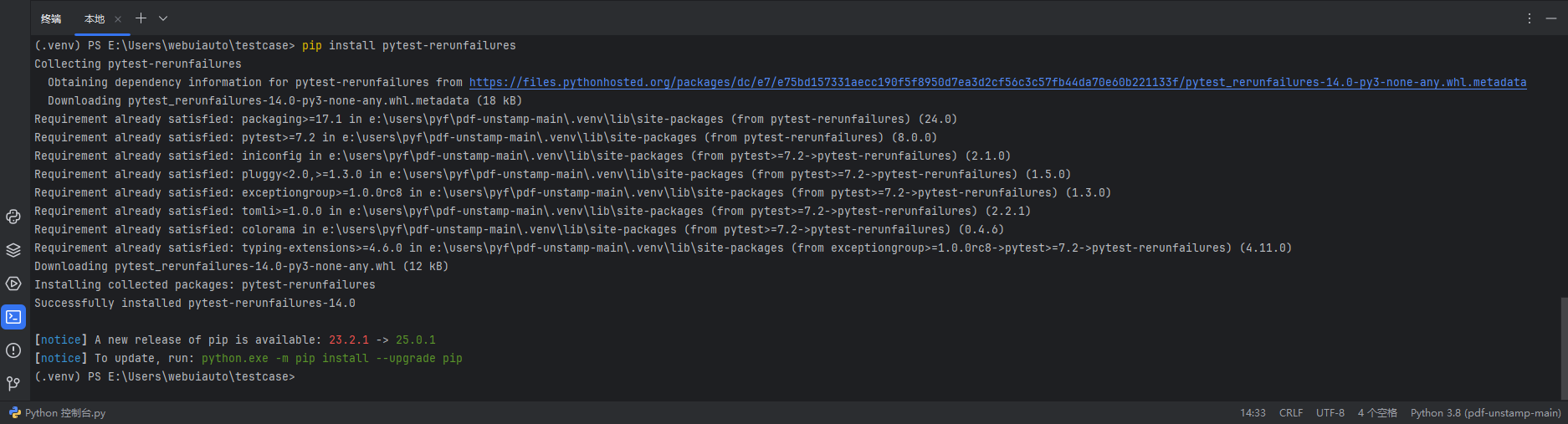
安装插件
pip install pytest-rerunfailures
模拟场景
定义一个 class TestReRunFailed: 测试类 ;
定义一个 def test_rerun_fail_case(self): 方法;
模拟偶发性失败、或是环境因素导致的测试失败;
写一个随机数随机执行,再断言随机选择“随机真值、假值”,然后去执行;
怎么使用失败重跑插件
对单个测试用例设置失败重跑次数
去关注平时跑的测试用例,哪一个用例波动比较大的,可以在那一个测试用例的前面添加 @pytest.mark.flaky() 装饰器,去设置重跑次数,里面需要用到两个参数,第一个 reruns=3 参数是当用例失败时会重跑次数(指定失败时重跑的次数),第二个 reruns_delay=2 参数是指定重试之间的延迟时间;这是对单个测试用例去设置重跑的次数;,根据平时跑的一个结果,去判定哪条测试用例报错比较多,就在那条测试用例加上失败重跑调试;
代码演示:
1import pytest 2 3class TestReRunFailed: 4 5 @pytest.mark.flaky(reruns=3, reruns_delay=2) 6 def test_rerun_fail_case(self): 7 import random 8 assert random.choice([True, False]) 9 10 def test_rerun_fail_case02(self): 11 import random 12 assert random.choice([True, False]) 13 14if __name__ == '__main__': 15 pytest.main() 16 # pytest.main(['--reruns=3'])
对所有测试用例设置失败重跑次数
在 pytest.ini 配置文件中去设置测试用例失败重跑参数,为所有的测试用例默认加上失败重跑的次数;
1[pytest] 2addopts = -vs --reruns 3 3 4testpaths = ./testcase 5 6python_files = test_*.py 7 8python_classes = Test* 9 10python_functions = test_*
第三个、测试用例执行顺序
因为在默认情况下,pytest 会以特定的顺序运行测试用例;可以使用 pytest-ordering 插件去自定义设置测试用例的执行顺序;
通常是按照测试文件中定义的顺序去执行,但是有的时候,测试用例的执行顺序对于特定的场景可能很重要,此时就需要更加精细的去控制测试用例的执行顺序;比如要去删除某一个用户,这种情况首先得先去跑执行新增创建用户的用例,只有新增完成之后,才能有数据去调用删除接口;
安装插件,通过插件去改变测试用例的执行顺序;

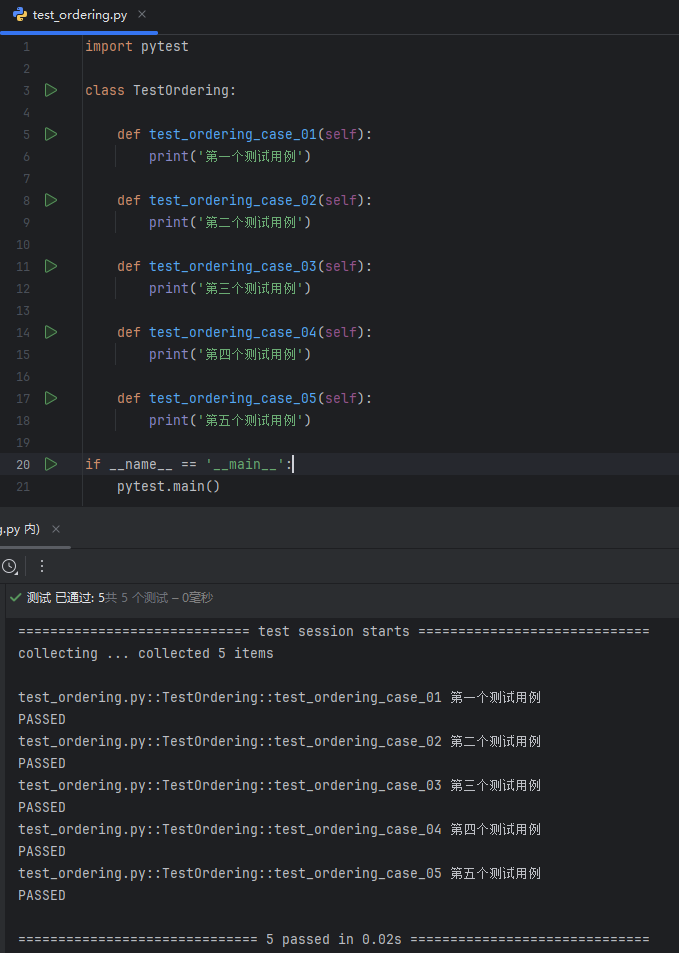
第一种写法
通过 pytest 装饰器 @pytest.mark.run(order=4) 调用插件里面的 run 方法来设置执行顺序;
1import pytest 2 3class TestOrdering: 4 @pytest.mark.run(order=4) 5 def test_ordering_case_01(self): 6 print('第一个测试用例') 7 8 @pytest.mark.run(order=5) 9 def test_ordering_case_02(self): 10 print('第二个测试用例') 11 12 @pytest.mark.run(order=1) 13 def test_ordering_case_03(self): 14 print('第三个测试用例') 15 16 @pytest.mark.run(order=2) 17 def test_ordering_case_04(self): 18 print('第四个测试用例') 19 20 @pytest.mark.run(order=3) 21 def test_ordering_case_05(self): 22 print('第五个测试用例') 23 24 25if __name__ == '__main__': 26 pytest.main()
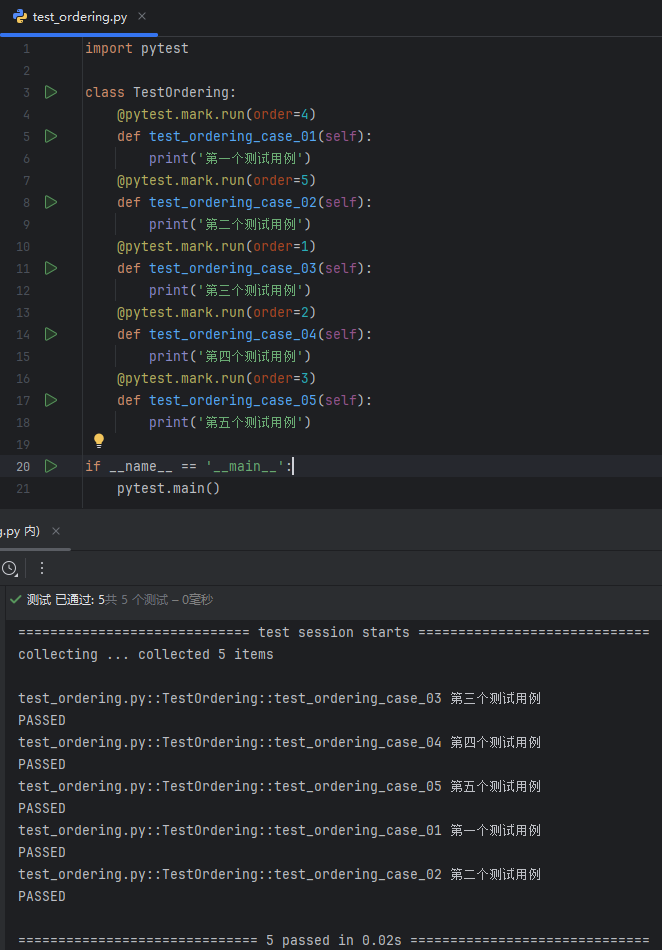
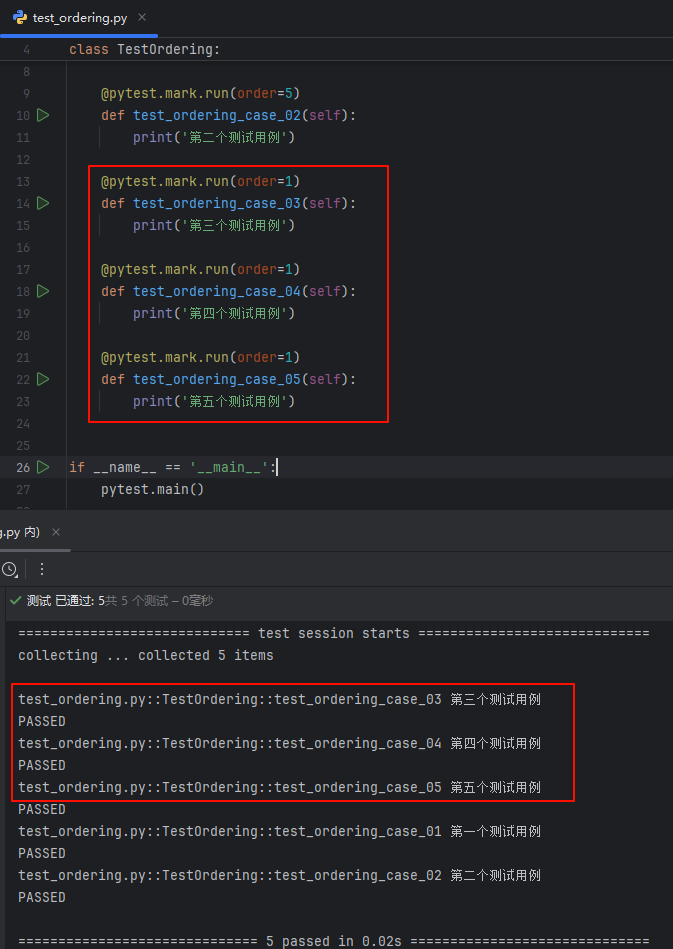
注意:当编号相同时,就根据文件设置的编码去执行了;
第二种写法、通过自定义方式
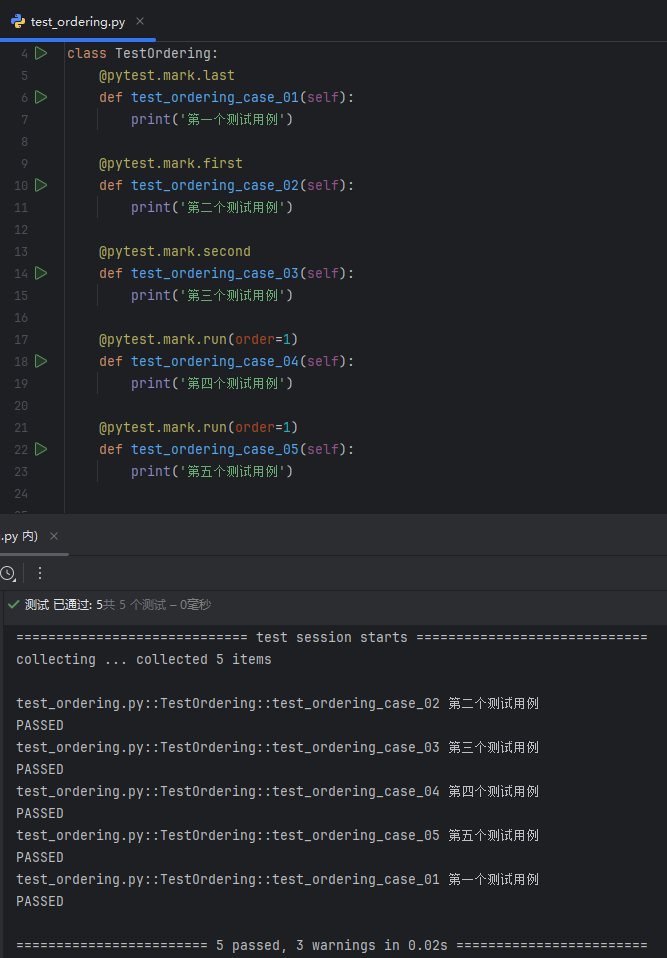
1import pytest 2 3 4class TestOrdering: 5 @pytest.mark.last 6 def test_ordering_case_01(self): 7 print('第一个测试用例') 8 9 @pytest.mark.first 10 def test_ordering_case_02(self): 11 print('第二个测试用例') 12 13 @pytest.mark.second 14 def test_ordering_case_03(self): 15 print('第三个测试用例') 16 17 18if __name__ == '__main__': 19 pytest.main()
运行后若发现警告信息(大致意思是“pytest 识别到了未注册的自定义标记”,如果使用的自定义标记不是 pytest 中自带的,而是个人自定义的时候就会出现警告信息),可以通过在 pytest.ini 配置文件中使用 markers 注册自定义标记来消除警告信息;
1[pytest] 2addopts = -vs --reruns 3 3 4testpaths = ./testcase 5 6python_files = test_*.py 7 8python_classes = Test* 9 10python_functions = test_* 11 12markers = 13 last 14 first 15 second
第四个、测试报告 allure-pytest
后续介绍。。。
八、参数化处理
在 pytest 中,参数化处理是最重要的部分之一,在实际工作场景中会经常用到,测试某一个功能时,需要传参数,才能去校验准确性;参数化是一种测试用例复用的方法,允许在一个测试函数上运行多组输入数据,以覆盖不同的测试场景,参数化使用 @pytest.mark.parametrize 装饰器来实现;
1、参数化的基本用法
使用 @pytest.mark.parametrize 装饰器,通过装饰器将参数传递给测试函数;
指定参数名和参数值;
在测试函数的参数中接收参数值,用于运行多次测试;
语法:@pytest.mark.parametrize("params1,params2,params3...",params_value)
params:参数值,可接收多个;
params_value:任何可迭代的对象,例如“列表、集合、字典等”
2、代码实现
参数化时会把“可迭代对象”里面的数据传递给“可接收参数”;
例如 可迭代对象 列表中 ['python', 'java', 'C#'] 有三组数据,参数化时会把 这三组数据 传递给 可接收参数 params;然后在测试函数中接收参数 def test_params_01(self, params): 在测试函数里面去接收参数化传递过来的值,这两个值(params)要一样,不能变,就是 @pytest.mark.parametrize 装饰器中的第一个参数 params 要和测试函数中接收的参数 params 一致;
接收单个参数
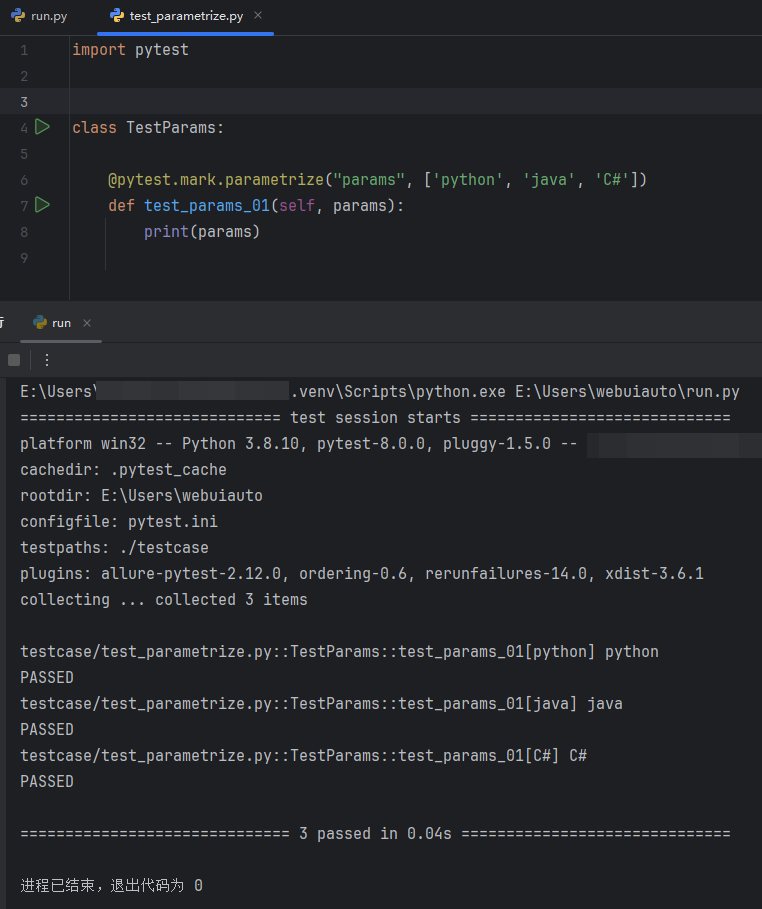
1import pytest 2 3class TestParams: 4 5 @pytest.mark.parametrize("params", ['python', 'java', 'C#']) 6 def test_params_01(self, params): 7 print(params)
运行 run.py 主函数文件,查看 test_params_01 测试方法能不能接收到 @pytest.mark.parametrize 装饰器参数化传递的参数;
可以看到 test_params_01 这一个测试用例成功执行了三次;
接收多个参数
接收多个参数时,注意相互对应,最好数据个数和接收参数个数相同;
可迭代对象:列表
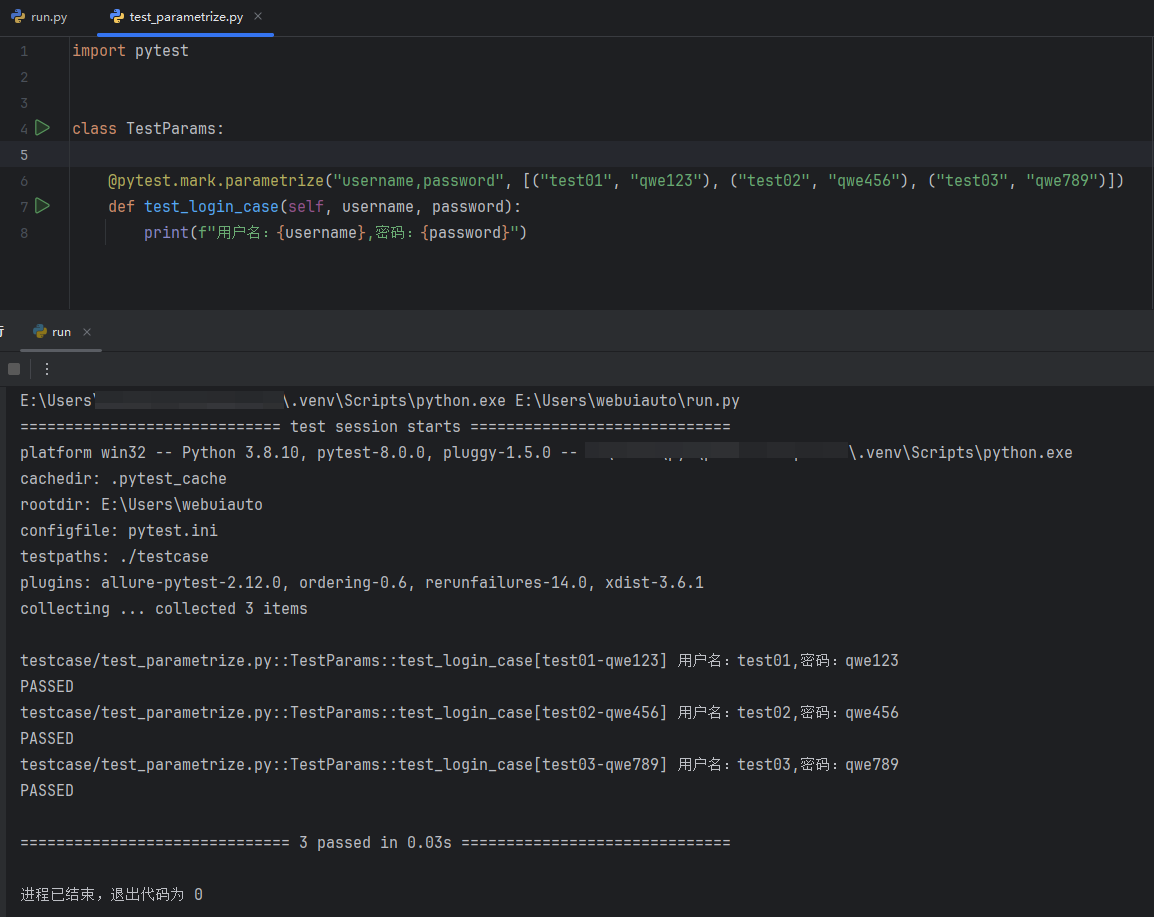
1import pytest 2 3class TestParams: 4 5 @pytest.mark.parametrize("username,password", [("test01", "qwe123"), ("test02", "qwe456"), ("test03", "qwe789")]) 6 def test_login_case(self, username, password): 7 print(f"用户名:{username},密码:{password}")
可迭代对象:集合
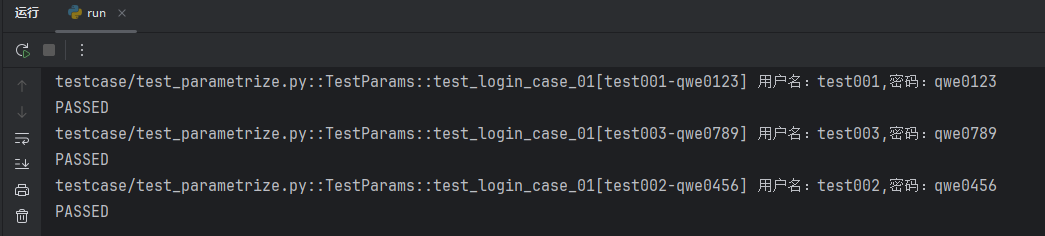
1import pytest 2 3class TestParams: 4 5 @pytest.mark.parametrize("params", ['python', 'java', 'C#']) 6 def test_params_01(self, params): 7 print(params) 8 9 @pytest.mark.parametrize("username,password", [("test01", "qwe123"), ("test02", "qwe456"), ("test03", "qwe789")]) 10 def test_login_case(self, username, password): 11 print(f"用户名:{username},密码:{password}") 12 13 @pytest.mark.parametrize("usernames,passwords", {("test001", "qwe0123"), ("test002", "qwe0456"), ("test003", "qwe0789")}) 14 def test_login_case_02(self, usernames, passwords): 15 print(f"用户名:{usernames},密码:{passwords}")
可迭代对象:字典
字典的迭代对象是只迭代 key 值,所以使用一个参数去接收;一般很少使用这种场景;
1import pytest 2 3class TestParams: 4 5 @pytest.mark.parametrize("params", ['python', 'java', 'C#']) 6 def test_params_01(self, params): 7 print(params) 8 9 @pytest.mark.parametrize("username,password", [("test01", "qwe123"), ("test02", "qwe456"), ("test03", "qwe789")]) 10 def test_login_case(self, username, password): 11 print(f"用户名:{username},密码:{password}") 12 13 @pytest.mark.parametrize("usernames,passwords,address", 14 {("test001", "qwe0123", "BJ"), ("test002", "qwe0456", "SH"), ("test003", "qwe0789", "SZ")}) 15 def test_login_case_02(self, usernames, passwords, address): 16 print(f"用户名:{usernames},密码:{passwords},地址:{address}") 17 18 @pytest.mark.parametrize("user_name", {"test0001": "qwe00123", "test0002": "qwe00456"}) 19 def test_login_case_03(self, user_name): 20 print(f"用户名:{user_name}") 21
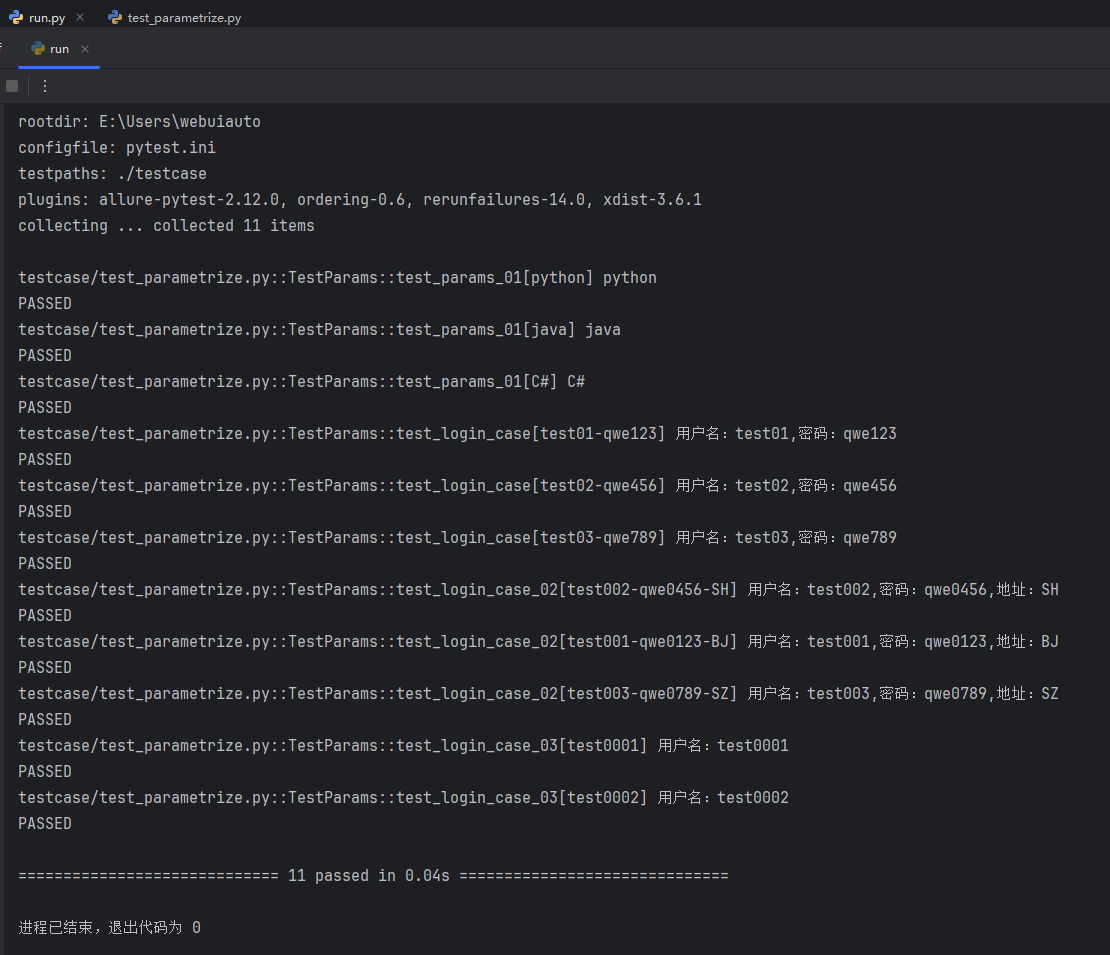
后续把参数化中的参数改造成可读取文件中的数据(例如 yaml 文件、Excel 文件等等)
未完待续。。。
《使用 Python 语言 从 0 到 1 搭建完整 Web UI自动化测试学习系列 18--测试框架Pytest基础 2--插件和参数化》 是转载文章,点击查看原文。

