课程:B站大学
记录python学习,直到学会基本的爬虫,使用python搭建接口自动化测试,后续进阶UI自动化测试
接口自动化测试
- 接口自动化测试的场景
- 测试金字塔模型
- 自动化测试前需要思考什么?
- Pytest是什么?
- Pytest 有哪些格式要求?
- 在pycharm下安装pytest
- pytest知识点
-
- 测试用例示例
- 类级别的用例示例
- 断言
- 测试装置介绍
- 参数化
- 参数化测试函数使用
- Mark:标记测试用例
- Skip:使用场景
- pytest命令运行测试用例文件
- pytest中执行顺序如何调整
-
- pytest中py文件执行顺序如何调整
- pytest中测试类中的test用例执行顺序如何调整
- pytest中py文件执行顺序如何调整
- pytest中常见的异常
-
- python中捕获异常
- 数据驱动测试(参数化)
- 实践是检验真理的唯一标准
接口自动化测试的场景
手工功能测试、手工接口测试流程:

自动化测试流程:
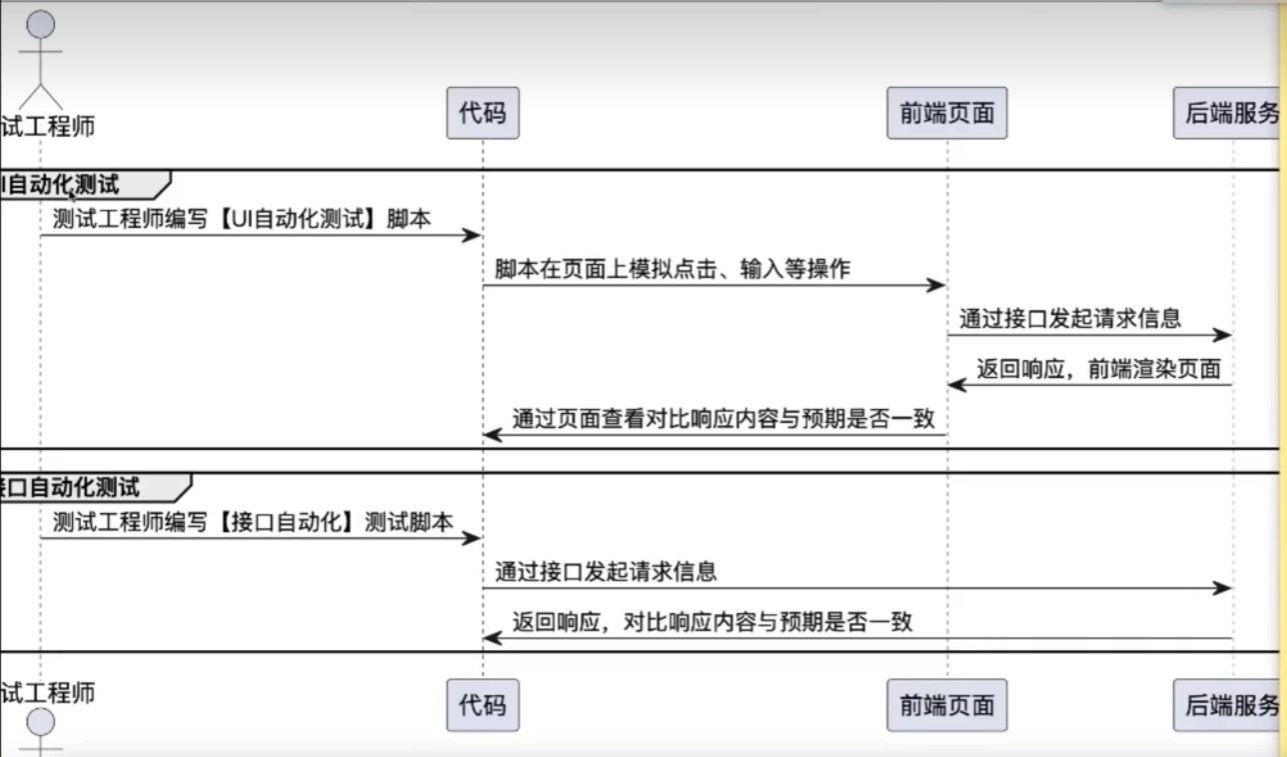
软件发起请求-得到响应流程:
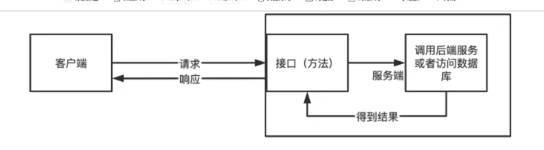
测试金字塔模型
自动化测试前需要思考什么?
• 自动化测试前,需要提前准备好数据,测试完成后,需要自动清理脏数据,有没有更好用的框架?
• 自动化测试中,需要使用多套测试数据实现用例的参数化,有没有更便捷的方式?
• 自动化测试后,需要自动生成优雅、简洁的测试报告,有没有更好的生成方法?
Pytest是什么?
pytest 能够支持简单的单元测试和复杂的功能测试;
pytest 可以结合 Requests 实现接口测试;结合 Selenium、Appium 实现自动化功能测试;
使用 pytest 结合 Allure 集成到 Jenkins 中可以实现持续集成。
pytest 支持 315 种以上的插件。
Pytest 有哪些格式要求?
Pytest 有哪些格式要求?
• 文件名
• 类
• 方法/函数
pytest命名要求:

在pycharm下安装pytest
打开 PyCharm 下方的 Terminal 标签页
输入以下命令安装 pytest:
1pip install pytest 2
验证是否安装成功(可选)
1pytest --version 2
这里我选择使用Anaconda Navigator虚拟环境管理用于管理环境,这个软件的好处就是有很多基础库,不好的的地方若其他人需要运行项目但是不想下载Anaconda,那么只能导入.txt依赖
pytest知识点
测试用例示例
1def test_xxx(self): 2 # 测试步骤1 3 # 测试步骤2 4 # 断言 实际结果 对比 预期结果 5 assert ActualResult == ExpectedResult 6
类级别的用例示例
常见的用例,先执行setup进行资源准备,然后执行test_xx用例函数,最后运行teardown清除资源和数据等后置操作
1class TestXXX: 2 def setup(self): 3 # 资源准备 4 pass 5 6 def teardown(self): 7 # 资源销毁 8 pass 9 10 def test_XXX(self): 11 # 测试步骤1 12 # 测试步骤2 13 # 断言 实际结果 对比 预期结果 14 assert ActualResult == ExpectedResult 15
断言
使用assert进行断言,断言验证接口响应是否符合预期
1def test_a(): 2 a = 1 3 b = 4 4 expect = 3 5 assert a + b == expect 6
测试装置介绍
| 类型 | 规则 |
|---|---|
| setup_module/teardown_module | 全局模块级 |
| setup_class/teardown_class | 类级,只在类中前后运行一次 |
| setup_function/teardown_function | 函数级,在类外 |
| setup_method/teardown_method | 方法级,类中的每个方法执行前后 |
| setup/teardown | 在类中,运行在调用方法的前后(重点) |
参数化
参数化设计方法就是将模型中的定量信息变量化,使之成为任意调整的参数。对于变量化参数赋予不同数值,就可得到不同大小和形状的零件模型。
参数化测试函数使用
参数化:笛卡尔积
• 比如
• a = [1,2,3]
• b = [a,b,c]
• 有几种组合形式?
• (1,a),(1,b),(1,c)
• (2,a),(2,b),(2,c)
• (3,a),(3,b),(3,c)
1import pytest 2 3# 1) 基本参数化:多个数据行 4@pytest.mark.parametrize("a,b,expected", [ 5 (1, 2, 3), 6 (2, 3, 5), 7 (0, 5, 5), 8]) 9def test_add(a, b, expected): 10 assert a + b == expected 11 12 13# 2) 使用 ids 给每一行命名,便于输出阅读 14@pytest.mark.parametrize("x,y,expected", [ 15 (2, 2, 4), 16 (10, -1, 9), 17 (3, 0, 3), 18], ids=["small", "mixed", "zero"]) 19def test_add_with_ids(x, y, expected): 20 assert x + y == expected 21 22 23# 3) 多个 @parametrize 装饰器会计算笛卡尔积(所有组合) 24@pytest.mark.parametrize("a", [1, 10]) 25@pytest.mark.parametrize("b", [0, 5]) 26def test_cartesian(a, b): 27 # 只做简单可重复的断言 28 assert (a + b) >= a 29 30 31# 4) 使用 pytest.param 设置 id 与 marks(例如对某个输入期望失败) 32@pytest.mark.parametrize("dividend,divisor,expected", [ 33 (10, 2, 5), 34 pytest.param(10, 0, None, marks=pytest.mark.xfail(reason="division by zero")), 35]) 36def test_division(dividend, divisor, expected): 37 # 对 0 做显式处理(这里让它抛出异常以触发 xfail) 38 result = dividend / divisor 39 assert result == expected 40 41 42# 5) 间接参数化:把参数传给 fixture 进行预处理 43@pytest.fixture 44def doubled(request): 45 # request.param 来自 indirect 参数传递 46 return request.param * 2 47 48 49@pytest.mark.parametrize("doubled,expected", [ 50 (1, 2), 51 (3, 6), 52], indirect=["doubled"]) 53def test_indirect(doubled, expected): 54 assert doubled == expected 55 56 57# 6) 参数化 fixture:fixture 本身就带有 params,测试会为每个 params 调用一次 58@pytest.fixture(params=[("a", 1), ("b", 2)], ids=["pair-a", "pair-b"]) 59def pair(request): 60 return request.param 61 62 63def test_param_fixture(pair): 64 name, val = pair 65 assert isinstance(name, str) 66 assert isinstance(val, int) 67 68 69# 7) 使用组合与说明:展示 pytest.param 多种用法 70@pytest.mark.parametrize( 71 "s,expected_len", 72 [ 73 pytest.param("", 0, id="empty"), 74 pytest.param("x", 1, id="one-char"), 75 pytest.param("hello", 5, id="hello"), 76 ], 77) 78def test_string_lengths(s, expected_len): 79 assert len(s) == expected_len 80 81 82# 8) 小结性的测试:演示参数化如何简化不同输入的覆盖 83@pytest.mark.parametrize("inputs,expected", [ 84 ([1, 2, 3], 6), 85 ([], 0), 86 ([10], 10), 87]) 88def test_sum_list(inputs, expected): 89 assert sum(inputs) == expected 90 91
Mark:标记测试用例
• 场景:只执行符合要求的某一部分用例 可以把一个web项目划分多个模块,然后指定模块名称执行。
• 解决:在测试用例方法上加 @pytest.mark.标签名
• 执行:-m执行自定义标记的相关用例
• pytest -s test_mark_zi_09.py -m=webtest
• pytest -s test_mark_zi_09.py -m apptest
• pytest -s test_mark_zi_09.py -m “not ios”
打标签mark可以运行指定的用例:
1import pytest 2import requests 3 4# ===== 1. 定义标记 ===== 5# 在pytest.ini或conftest.py中注册自定义标记(可选但推荐) 6# 示例:在pytest.ini中添加: 7# [pytest] 8# markers = 9# smoke: 冒烟测试用例 10# regression: 回归测试用例 11# api: 接口测试 12 13# ===== 2. 带标记的测试类 ===== 14class TestUserAPI: 15 # ===== 3. 用例级别标记 ===== 16 @pytest.mark.smoke # 冒烟测试标记 17 @pytest.mark.api # 接口测试标记 18 def test_get_user_info(self): 19 """获取用户信息(正常流程)""" 20 url = "https://api.example.com/users/1" 21 response = requests.get(url) 22 assert response.status_code == 200 23 assert response.json()["id"] == 1 24 25 @pytest.mark.regression # 回归测试标记 26 @pytest.mark.parametrize("user_id, expected_status", [ # 参数化标记 27 (1, 200), # 正常用户 28 (999, 404) # 不存在的用户 29 ]) 30 def test_get_user_by_id(self, user_id, expected_status): 31 """根据ID获取用户(参数化测试)""" 32 url = f"https://api.example.com/users/{user_id}" 33 response = requests.get(url) 34 assert response.status_code == expected_status 35 36 # ===== 4. 跳过测试标记 ===== 37 @pytest.mark.skip(reason="该接口已废弃,暂不测试") # 跳过标记 38 def test_deprecated_api(self): 39 pass 40 41 # ===== 5. 条件跳过标记 ===== 42 @pytest.mark.skipif( 43 condition=not hasattr(requests, "get"), # 条件成立时跳过 44 reason="requests库缺少get方法" 45 ) 46 def test_conditional_skip(self): 47 pass 48 49# ===== 6. 命令行执行示例 ===== 50""" 51# 运行所有冒烟测试 52pytest -v -m smoke 53 54# 运行除smoke外的所有测试 55pytest -v -m "not smoke" 56 57# 运行参数化测试中的特定数据(需结合pytest参数化标记) 58pytest -v -k "test_get_user_by_id and 1" 59""" 60
通过标签我们可以分层测试需要测试的接口信息
Skip:使用场景
Skip 使用场景
- 调试时不想运行这个用例
- 标记无法在某些平台上运行的测试功能
- 在某些版本中执行,其他版本中跳过
- 比如:当前的外部资源不可用时跳过
- 调试过程中,需要跳过的用例(比如登出)
如果测试数据是从数据库中取到的,连接数据库的功能如果返回结果未成功就跳过,因为执行也都报错
解决1:添加装饰器
1pytest.skip(reason) 2这里也就是跳过,reason就是原因 3
适用场景:
用例正在编写中,暂时不想执行
某个功能尚未开发完成
用例暂时不需要跑(如旧用例、备用用例
1@pytest.skip(reason="功能未开发,暂不测试") 2def test_unfinished(): 3 assert True 4
下方是条件跳过,默认skipif判断为ture
1@pytest.skipif 2
适用场景:
环境不满足(如测试环境、依赖服务不可用)
依赖未安装 / 模块缺失
接口/功能未上线
仅限特定条件执行(如非生产环境、特定版本等)
这里可以用来指定一些用例的条件,比如A模块中的用例执行完后才能执行B模块中的用例
1import sys 2import pytest 3 4@pytest.mark.skipif(sys.version_info < (3, 8), reason="需要 Python 3.8+") 5def test_python_version(): 6 assert True 7
在用例里面也是可以使用skip进行跳过用例的
pytest命令运行测试用例文件
在编写代码阶段,在windows端我们可以使用pycharm直接运行测试用例文件,但是接口自动化一般都是在服务端运行,故一般运行时采用命令行运行。
- pytest—— 运行所有测试
- pytest -v—— 显示详细日志(推荐日常调试用)
- pytest -s——打印输出日志(-vs,打印输出详细日志)
- pytest 文件.py—— 运行指定测试文件
- pytest -m smoke—— 只运行标记为 smoke 的用例
- pytest -k “login”—— 按用例名称关键字筛选执行
- pytest -x—— 遇到失败立即停止,快速排查问题
- pytest -n 4—— 多进程并行执行,提升测试速度
- pytest --junitxml=report.xml—— 生成标准测试报告,用于 CI/CD
服务端调试使用
1pytest 文件名.py::函数名 2
运行指定文件中的某个测试函数,如 pytest test_login.py::test_login_success
一般在本地开发完自动化测试代码后,就可以直接git上传,然后服务端进行部署接口测试项目,后续集成CI/CD【Jenkins】,就可以自动执行pytest -m xxxx命令,执行对应的标签用例。
故自动化测试项目的标签很好用。
一般来说一个业务场景就写成一个用例文件,多个用例文件有执行顺序,这时候可以用
pytest中执行顺序如何调整
pytest中py文件执行顺序如何调整
对于pytest文件的指定顺序,可以进行CI/CD持续集成,比如Jenkins调用可以写个shell脚本
shell脚本的顺序就是py文件执行的顺序
1#!/bin/bash 2 3# 按你希望的顺序执行测试文件 4pytest tests/test_login.py 5pytest tests/test_order.py 6pytest tests/test_user.py 7
pytest中测试类中的test用例执行顺序如何调整
在测试函数上添加装饰器 @pytest.mark.order(数字)
1# test_order.py 2 3import pytest 4 5@pytest.mark.order(2) 6def test_b(): 7 print("执行 test_b") 8 9@pytest.mark.order(1) 10def test_a(): 11 print("执行 test_a") 12
若不用order,那么python是自上而下运行的执行顺序,可以结合skip进行跳过操作
pytest中常见的异常
常见异常类型
AssertionError:断言失败时抛出FixtureLookupError:找不到指定的 fixture 时抛出ImportError:导入模块或测试文件失败时抛出TimeoutError:测试超时时抛出(需配合插件使用)PytestFailedException:pytest 内部测试失败异常
python中捕获异常
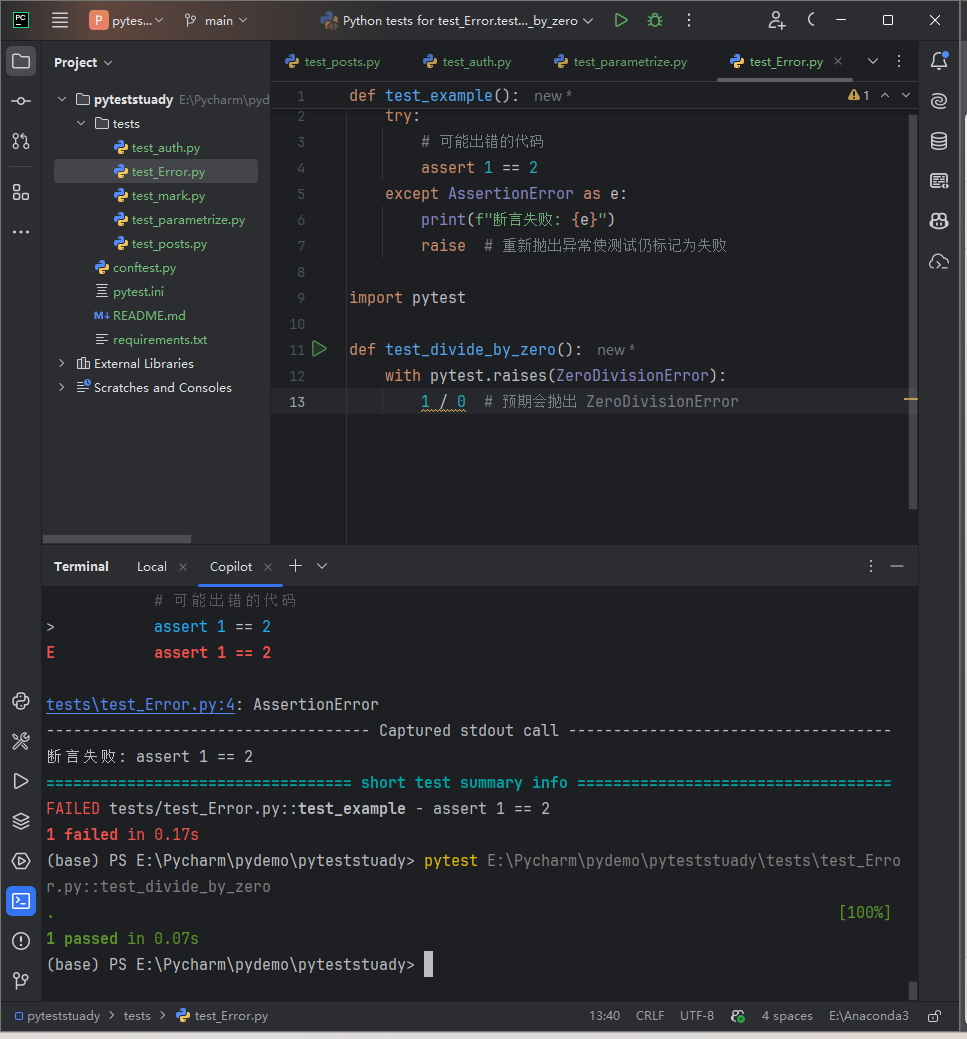
1、使用 try-except 捕获:
1def test_example(): 2 try: 3 # 可能出错的代码 4 assert 1 == 2 5 except AssertionError as e: 6 print(f"断言失败: {e}") 7 raise # 重新抛出异常使测试仍标记为失败 8
2、 pytest.raises 上下文管理器(推荐使用方式):
1import pytest 2 3def test_divide_by_zero(): 4 with pytest.raises(ZeroDivisionError): 5 1 / 0 # 预期会抛出 ZeroDivisionError 6
比如在调试业务中会常常见到token过期的异常,此时可以使用异常断言
1def test_exception(): 2 with pytest.raises(ValueError) as excinfo: 3 int("abc") 4 assert "invalid literal" in str(excinfo.value) # 检查异常信息 5
这里的raises用于异常,那么只要符合异常就直接会运行通过,这里不会打印抛出日志,我一般使用try-except语句抛出指定的异常信息
数据驱动测试(参数化)
数据驱动是指通过改变数据来驱动自动化测试的执行,从而引起测试结果的改变。简单来说,这是参数化的一种应用。对于数据量较小的测试用例,可以通过代码参数化实现数据驱动;而在数据量较大的情况下,建议使用结构化的文件(如 yaml、json 等)来存储数据,并在测试用例中读取这些数据。
参数的好处:数据驱动、数据隔离、不影响代码逻辑
目录结构:
1api_tests/ 2├── test_api.py # 测试代码(核心逻辑) 3└── test_data.yaml # 测试数据(YAML 格式) 4
test_data.yaml:
1# 只需维护这一份数据,格式:case_name, 请求参数, 预期结果 2- case_name: "登录成功" 3 url: "https://httpbin.org/post" 4 method: "POST" 5 data: {"username": "admin", "password": "123456"} 6 expected: {"status_code": 200} 7 8- case_name: "登录失败" 9 url: "https://httpbin.org/post" 10 method: "POST" 11 data: {"username": "wrong", "password": "123"} 12 expected: {"status_code": 200} 13
每个测试用例包含:case_name(用例名)、url(接口地址)、method(HTTP方法)、data(请求参数)、expected(预期结果)。
直接复用 httpbin.org模拟真实 API(实际项目替换成你的接口地址)。
test_api.py:
1import pytest 2import requests 3import yaml 4 5# 1. 读取 YAML 数据(1行代码) 6test_data = yaml.safe_load(open("test_data.yaml")) 7 8# 2. 参数化测试(1个函数搞定所有用例) 9@pytest.mark.parametrize("case", test_data, ids=lambda x: x["case_name"]) # 用例名显示在报告中 10def test_api(case): 11 # 发请求(自动适配 POST/GET) 12 resp = requests.request(case["method"], case["url"], json=case["data"]) 13 14 # 断言(只检查状态码,可扩展) 15 assert resp.status_code == case["expected"]["status_code"] 16
运行命令:
1pytest test_api.py -v 2
实践是检验真理的唯一标准
《pytest1-接口自动化测试场景》 是转载文章,点击查看原文。

