作者:来自 Elastic Benjamin Trent, John Wagster 及 Ignacio Vera Sequeiros

介绍 DiskBBQ,一种 HNSW 的替代方案,并探讨何时以及为何使用它。
测试 Elastic 的领先开箱即用能力。深入我们的示例笔记本,开始免费的云试用,或立即在本地机器上尝试 Elastic。
DiskBBQ 是 Inverted Vector File (IVF) 索引的进化版。它是 Hierarchical Navigable Small Worlds (HNSW) 的替代方案,通过将向量划分为更小的簇,在低内存场景下能更高效地处理,同时提供良好的查询性能。
HNSW 有什么问题?
我们非常喜欢 HNSW。它是一种快速且计算高效的算法,能以对数级扩展到你的向量数据。然而,这种速度是有代价的。为了让 HNSW 良好运作,所有向量都需要驻留在 RAM 中。虽然我们通过引入越来越好的量化方法降低了成本,但仍然存在向量溢出内存导致性能骤降的问题。
此外,在建立索引时,你必须搜索现有的 HNSW 图。因此,RAM 的所有内存成本在索引期间同样存在。这会显著拖慢那些无法完全将向量存放在 RAM 中的硬件。
DiskBBQ 有什么不同?
DiskBBQ 使用 Hierarchical K-means 将向量划分为小簇。然后在查询单个向量之前,先选择代表性的质心进行查询。它利用这种层级的多层特性,在查询时最多只查询 2 层质心,从而限制总的搜索空间。最后,它通过批量计算簇内向量与查询向量之间的距离,来探索每个簇中包含的向量。
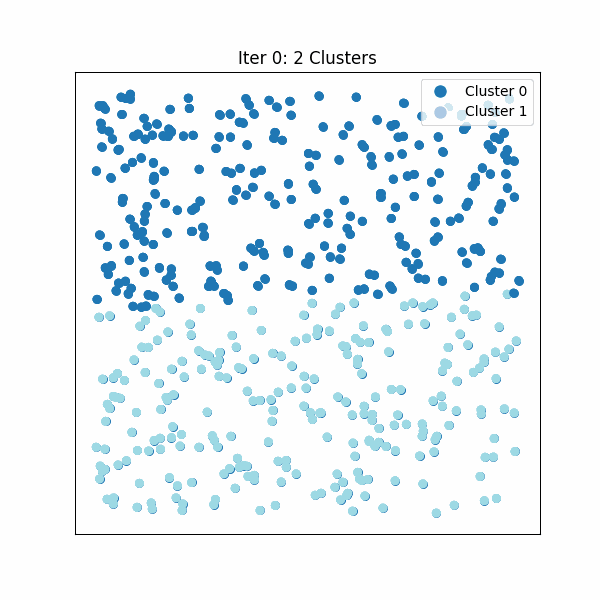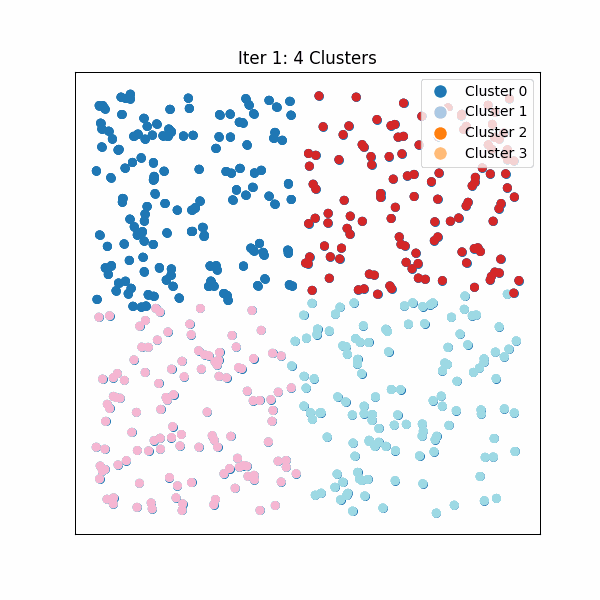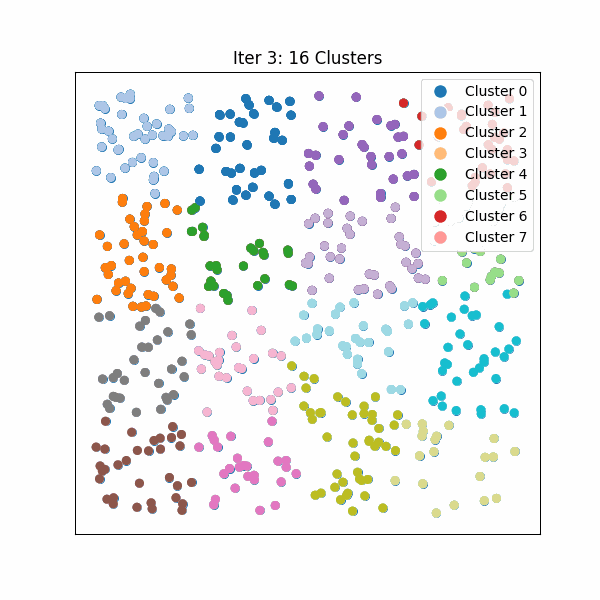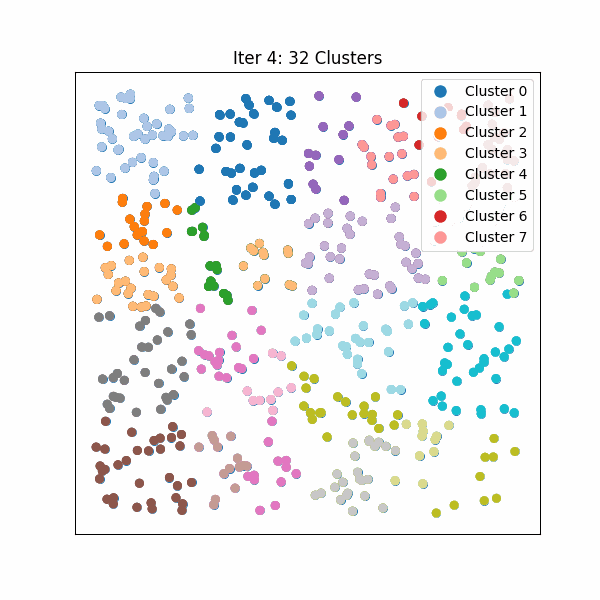
图 0. Hierarchical KMeans 算法流程示例。将向量分段,对每一段进行聚类,并递归拆分直到达到所需的分区大小。
正如名字所暗示的,DiskBBQ 还使用我们的 BBQ (Better Binary Quantization) 来减小向量和质心的大小。这使得可以一次将许多向量块加载到内存中进行快速评分,同时需要极低的内存和磁盘开销。
DiskBBQ 的另一个有趣之处在于它允许向量被分配到多个质心。它使用了 Google 的 Spilling with Orthogonality-Amplified Residuals (SOAR)的一个版本,将向量分配到多个簇中,这在向量位于两个簇边界附近时特别有益。由于向量被大量量化,这只会增加极少的磁盘开销,并且在搜索过程中需要探索的质心更少。
空谈无益,让我们看看一些数据。
HNSW 是按对数级扩展的。所以它一定比那种必须先搜索质心再对每个质心中的所有向量进行评分的方法快许多个数量级,对吧?
我们一直在努力让 DiskBBQ 完全具备与 HNSW 竞争的能力。虽然在所有情况下我们还没做到 100%,但对结果我们很满意。
DiskBBQ 利用了批量评分向量的优势,并尽可能多地在堆外执行操作。这意味着我们可以直接从文件中读取向量到内存中进行优化的向量运算,从而带来相当不错的性能。
DiskBBQ 有两个特别有趣的主要场景。第一个是整个索引都能放入 RAM 的情况。由于这是 HNSW 性能的关键,因此看看 DiskBBQ 在这种情况下的表现才公平。
| 类型 | 索引时间 | 延迟 | 召回率 |
|---|---|---|---|
| HNSW BBQ | 1,054,319ms | ~3.4ms | 92% |
| DiskBBQ | 94,075ms | ~4.0ms | 91% |
表 0. DiskBBQ 在超过 100 万向量下的对比。所有数据都能舒适地放入内存。DiskBBQ 在索引速度上能快上惊人的 10 倍,同时在 BBQ 量化向量上的查询速度几乎与 HNSW 一样快。
当内存逐渐减少到整个索引不再能完全放入内存时,情况会变得更有趣。我们将会单独写一篇博客来深入探讨为什么 DiskBBQ 在低内存环境下更好,以及我们的测试方法。然而,这里先给出一些高层级的数据:
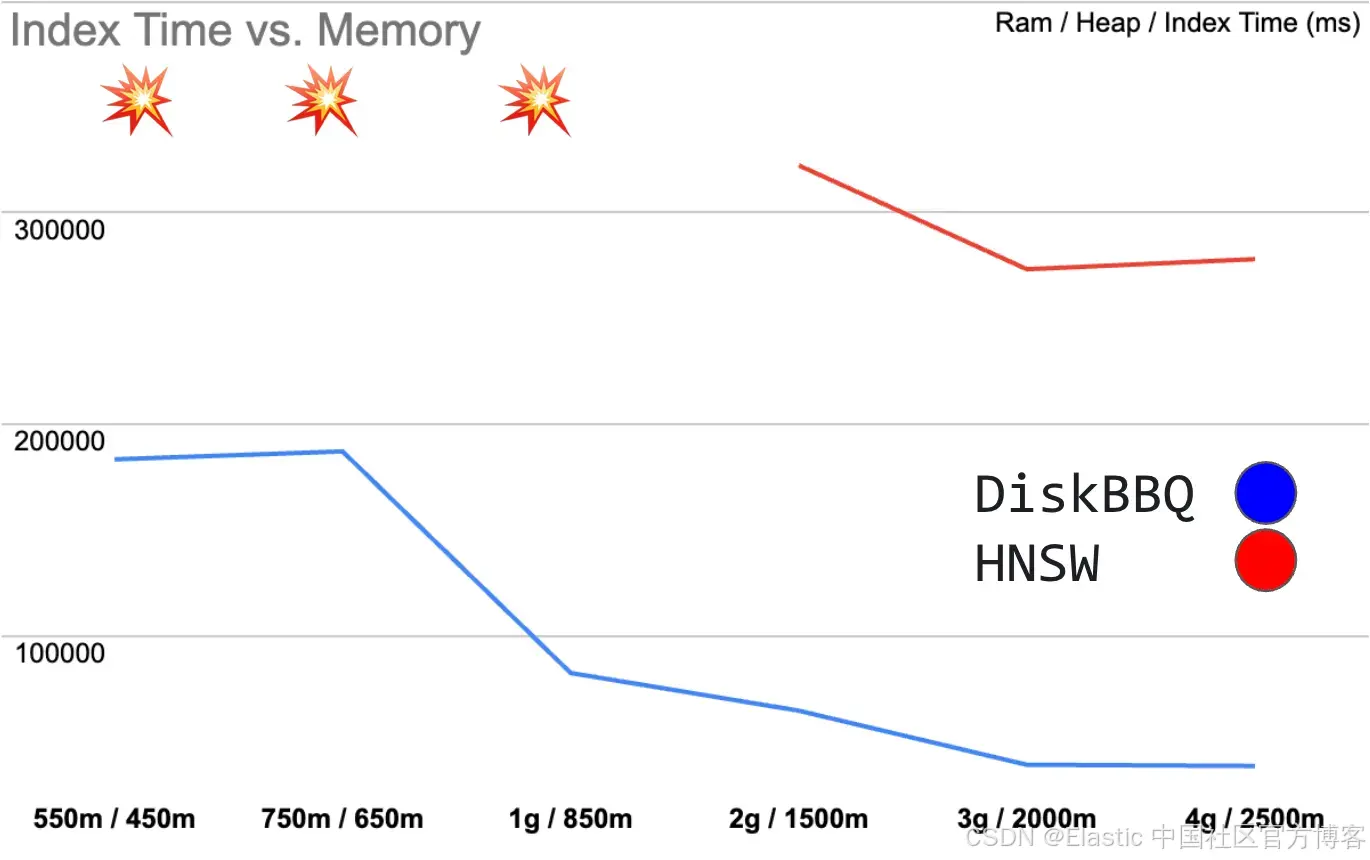
图 1:显示索引时间(毫秒)与 RAM / JVM Heap 的关系
随着总体内存减少,DiskBBQ 的索引性能会平稳下降。然而,HNSW 一旦内存非常受限,就会彻底崩溃。
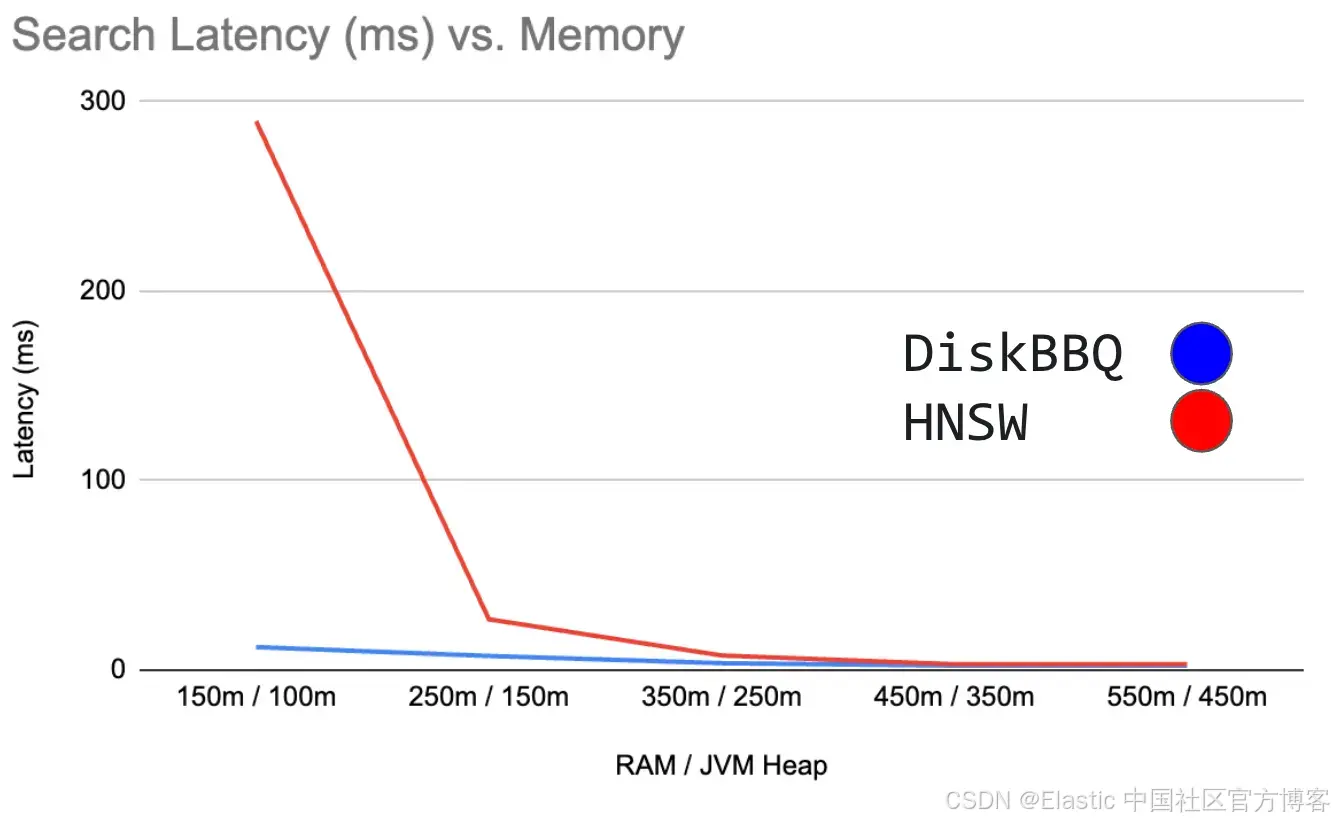
图 2:显示搜索延迟(毫秒)与 RAM / JVM Heap 的关系
同样,我们看到 DiskBBQ 在搜索延迟上平稳下降。确实,它开始变慢,但随着内存越来越受限,HNSW 的延迟会呈指数增长。
什么时候应该使用 DiskBBQ?
DiskBBQ 和 HNSW 都将在 Elasticsearch 中持续改进。目前,DiskBBQ 在非常高召回率(99% 以上)和非常低延迟的性能上,还不如 HNSW。我们希望在继续投入 HNSW 的同时提升 DiskBBQ 的性能。
如果你需要非常非常高的召回率,有大量堆外内存(或者愿意为此付费),且索引更新较少(因此索引成本低),使用带有某种量化的 HNSW 仍可能是最佳选择。
然而,如果你能接受 95% 或更低的召回率,对成本敏感,但仍希望快速搜索,DiskBBQ 可能是你的解决方案。
我该如何使用 DiskBBQ?
以下是启用 DiskBBQ 并开始查询的方法:
设置一个类似这样的 mapping:
{
"mappings": {
"properties": {
"image-vector": {
"type": "dense_vector",
"dims": 3,
"similarity": "l2_norm",
"index_options": {
"type": "bbq_disk"
}
}
}
}
}
插入一个向量:
{ "image-vector": [0.0127, 0.1230, 0.3929] }
这是一个查询该向量的示例:
{
"query" : {
"knn": {
"field": "image-vector",
"query_vector": [0.0127, 0.1230, 0.3929]
}
}
}
你仍然可以使用 num_candidates 来控制近似。
这是一个查询该向量的示例:
{
"query" : {
"knn": {
"field": "image-vector",
"query_vector": [0.0127, 0.1230, 0.3929],
"k": 10,
"num_candidates": 50
}
}
}
DiskBBQ 很快将在 Elasticsearch Serverless 中可用。
原文:https://www.elastic.co/search-labs/blog/diskbbq-elasticsearch-introduction
《介绍一种新的向量存储格式:DiskBBQ》 是转载文章,点击查看原文。

