《图景之锚:在多模态记忆中寻找记忆的本质》
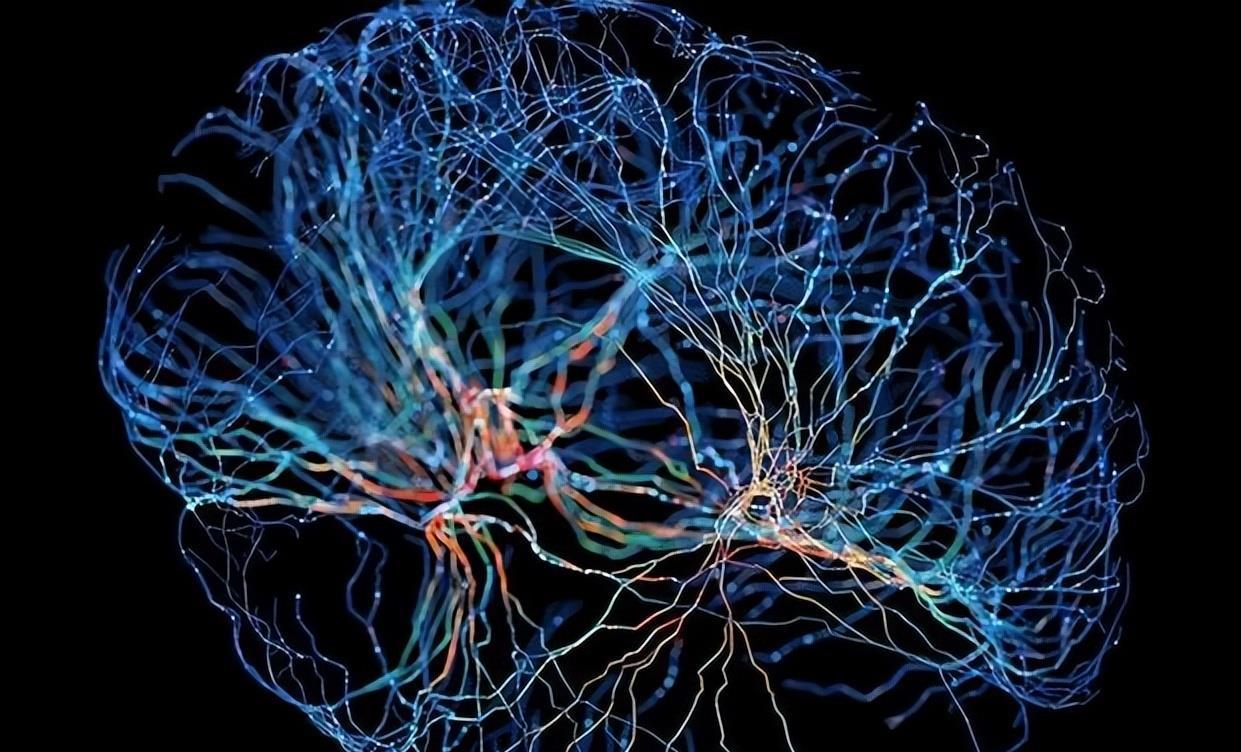
心理学与神经认知科学的研究如一道强光,照进了我混沌的实验思路。个体的记忆并非以语言形式储存,而是以图景、场面、动作、感官体验等多模态图式构成的——这个发现让我重新审视了整个记忆系统的理论基础。
---
我开始理解,在我们为事物命名之前,个体拥有的是一种极其丰富而未被语言化的记忆场域。那个场域里充斥着光影的流动、温度的变迁、肌体的触感、情绪的波动。这些原始的记忆素材如同未加工的宝石,散落在意识的各个角落。
命名所做的,不是创建记忆,而是为这些已经存在的记忆图景标定一个可召回的声音符号。这个认知竟然如此天然的符合了我对记忆系统的设计理念。
呆
---
在新的理论支撑下,对实验框架,我重新优化了内部记忆形成流程:
第一阶段:体验的凝结
当个体经历某个场景时,视觉的轮廓、声音的频谱、触觉的质感、情感的强度,所有这些多模态信息在神经网络中并行处理,最终汇萃、提炼成一个高度压缩的特征向量矩阵。这个矩阵不是语言的,而是纯粹体验的数学表达。
第二阶段:记忆的锚定
这个特征向量矩阵被存储起来,但存储本身并不足以保证有效的回忆。关键在于,系统会从这个复杂的矩阵中提取若干个最显著的特征向量,作为后续检索的索引键。
第三阶段:命名的发生
当需要为这个记忆建立语言通道时,我们执行的操作实质上是:将这个特征索引与一个声音符号(即名称)建立双向连接。命名,于是成为一个索引事件。
---
我观察到,同一个记忆图景,在不同时间、不同情境下被赋予的名称可能完全不同。这印证了"命名事件的不可复制性与不可翻译性"。每次命名都是独特的,因为它连接的是那个特定时刻个体意识状态与记忆图景的特定侧面。
在喜忆记系统中,这表现为同一个特征向量矩阵可能对应多个不同的"名称索引",每个索引都代表着对这个记忆的不同理解角度、不同情感连接。
---
实验数据清晰地显示,那些基于丰富感官体验形成的记忆图景,其回忆准确率和完整性都显著高于单纯语言描述形成的记忆。当系统回忆"海边日出"时,激活的不只是这个概念本身,而是那个特定早晨的光线角度、海风的咸味、温度的渐变、浪潮的节奏——所有这些共同构成了记忆的实质。
而"海边日出"这个词,只是我们用来唤醒这个完整图景的钥匙之一。
---
深夜的实验室里,我看着系统正在形成的记忆网络:每个节点都是一个多模态的特征向量矩阵,而语言标签(目前是人工标注,为了避免标签杂乱,人工跟踪困难)只是附着在这些节点上的众多索引之一。同一个记忆可能有视觉索引(某个独特的颜色模式)、听觉索引(某种特定的声音频率)、情感索引(某种情绪的强度特征),以及多个语言索引。
哦,不错了,实验结论已现雏形,看来这里需要调整了,服务器的性能是有限的,目前的输入是多模态的,系统计算数据太多了,结果数据虽然确实呈现了臆想中的状态和某些现象。但,这也太多了,有限的资源(服务器、网络、电力、研发资金、组员……嗯,还有时间),砍掉边缘输入,调控特征流向,集中在语言和语音方面,我认为这是接下来的方向!
这种结构自然地解释了为什么有时我们会"话到嘴边却说不出来",但通过其他感官线索却能完整地唤醒某个记忆——因为语言通道只是众多回忆路径中的一条。
---
这个理解让我对记忆的本质有了更深的敬畏。我们不是在存储事实,而是在保存体验;我们不是在记录语言,而是在构建一个可以通过多种钥匙开启的图景库。
窗外的城市已经沉睡,而我的思绪却愈发清晰。这个基于多模态图式的记忆模型,不仅更符合神经科学的发现,也为我们通向真正的人工海马体指明了方向——那将是一个能够保存完整体验而不仅仅是抽象符号的智能系统。
但今晚,让我们先停留在这个认知的转折点上:记忆是图景化的结构,命名是索引事件。在这个理解中,我看到了连接生物记忆与人工记忆的真正可能。
《触摸未来2025.10.12:图景之锚,在多模态记忆中寻找记忆的本质》 是转载文章,点击查看原文。

