🚀 欢迎来到「数据中心网络与异构计算」专栏!
在这个算力定义未来的时代,我们正见证一场从底层网络到计算架构的深刻变革。本专栏将带您穿越技术迷雾,从当前困境出发,历经三次关键技术跃迁,最终抵达「数据中心即计算机」的终极愿景。
目录
一、形式遵循功能:从 “通信指令” 到 “访问指令” 的蜕变
二、RDMA 与智能网卡 / DPU 的本质区别:从 “通信优化” 到 “内存总线化”
三、RDMA 的技术实现:三大协议与各自的 “性能 - 成本” 取舍
3.1 InfiniBand(IB):原生无损的 “性能极致派”
3.2 RoCEv2(RDMA over Converged Ethernet):以太网生态的 “妥协实用派”
3.3 iWARP:TCP 之上的 “兼容试水派”
四、范式革命的成果:绕开远程 CPU
4.1 彻底绕开远程 CPU
4.2 异构设备的 “对等访问” 成为可能
五、结语:范式革命的里程碑与未尽之题
上一篇我们看到,智能网卡与 DPU 虽大幅为 CPU 减负,却仍困于 “数据拷贝” 与 “远程 CPU 隐性参与” 的瓶颈。当 AI 训练、高性能计算对 “微秒级延迟”“无 CPU 干预通信” 的需求愈发迫切时,一场更深层的范式革命呼之欲出 ——RDMA(远程直接内存访问) 技术的出现,彻底打破 “发送消息” 的通信思维,转向 “访问内存” 的新范式,一举绕开远程 CPU,却也为 “异构计算单元的缓存一致” 留下了待解的难题。
一、形式遵循功能:从 “通信指令” 到 “访问指令” 的蜕变
建筑学中 “形式遵循功能(Form Follow Function)” 的设计原则,在数据中心网络演进中同样成立:当系统功能从 “以 CPU 为中心的进程间通信”,转向 “以数据为中心的设备间协同” 时,接口必须从 “send/recv” 这类通信指令,进化为 “read/write” 般的内存访问指令。
RDMA 正是这种 “内存语义” 的核心载体。它的本质,是让网络中任何计算设备(CPU、GPU、FPGA、DPU 等),都能以对等身份直接操作彼此的内存数据—— 不再需要通过 “发送消息→远程 CPU 接收→数据拷贝到内存” 的繁琐流程,而是像访问本地内存一样,直接读写远程内存地址。这种 “内存语义” 的价值,在于将通信的抽象层级从 “字节流、消息” 提升到 “内存操作”,为 “分布式计算机像单机一样协同” 奠定基础。
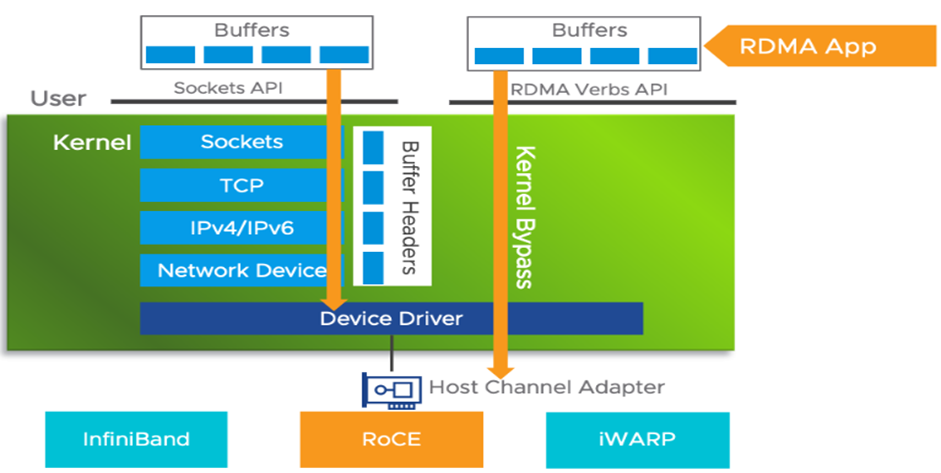
二、RDMA 与智能网卡 / DPU 的本质区别:从 “通信优化” 到 “内存总线化”
若把智能网卡 / DPU 比作 “超级物流中心”—— 能高效完成 “包裹分拣、打包、贴标”(协议处理),让本地与远程 CPU 从杂活中解放,但 “包裹最终仍需收件人(远程进程)签收”;那么 RDMA 更像 “共享仓库”:设备无需 “寄送包裹”,而是直接拥有权限,能走进任何一个 “远程内存仓库”,把数据放在指定 “货架(内存地址)” 上,或直接取走数据。
这种区别的核心在于设计层级:
- 智能网卡 / DPU 是在计算机网络层面优化 “通信流程”,让 “寄包裹” 更高效;
- RDMA 则是在计算机体系结构层面,试图将 “网络” 变成一台 “分布式计算机” 的 “内存总线”—— 就像单机里 CPU 通过 PCIe 访问显卡内存、通过内存控制器访问主存,RDMA 要让不同服务器的内存,也能通过网络被 “直接访问”。
最终体现在延迟上:传统通信范式的端到端延迟 = 处理延迟(发送端 CPU + 接收端 CPU) + 网络传输延迟;而 RDMA 的内存语义延迟 ≈ 网络传输延迟,彻底绕开了 CPU 参与的处理环节。
三、RDMA 的技术实现:三大协议与各自的 “性能 - 成本” 取舍
RDMA 并非单一技术,而是通过不同协议实现 “远程内存直接访问”,各协议在 “性能、兼容性、成本” 上各有侧重,
RDMA目前有三种网络协议:
- Infiniband:一种原生支持RDMA的定制网络协议,但由于协议定制,不兼容以太网协议设备,成本高。(适合大规模,更受产业界欢迎)
- RoCE:分为RoCEv1和RoCEv2,兼容以太网;RoCEv1使用IB协议作为网络层,RoCEv2使用IP/UDP作为网络层。(适合小规模,更受学术界欢迎)
- **iWARP:**允许在TCP上执行RDMA的网络协议,同样兼容以太网,但需将整个TCP/IP协议栈卸载到硬件,存在成本、实现复杂度、性能方面的限制。
3.1 InfiniBand(IB):原生无损的 “性能极致派”
InfiniBand 不是简单的网卡或线缆,而是一套专为高性能计算设计的端到端网络架构。它的设计哲学是 “不惜代价将软件协议开销降为零,把硬件性能推到极致”:
- 底层可靠性:摒弃 “以太网思维(靠上层软件保证可靠)”,在链路层就通过 “基于信用的流量控制” 实现无损传输 —— 接收方主动告知发送方 “空闲缓冲区数量(信用值)”,发送方有信用才发数据,从源头杜绝拥塞丢包;
- 集中式网络管理:子网管理器像 “交通总控”,自动发现网络拓扑并为数据流计算最优路径;
- 内存语义 API:通过 Verbs API 提供 “内存区域、队列对” 的抽象,程序员只需关注 “把数据放到远程内存地址”,无需操心通信细节。
这种设计让 InfiniBand 的延迟低至 1 微秒级,吞吐量轻松突破 400Gbps,但兼容性与成本是短板—— 它不兼容以太网设备,需专用网卡、交换机与线缆,部署成本高,更适合超算中心、大型 AI 训练集群等 “性能优先、成本其次” 的场景。
3.2 RoCEv2(RDMA over Converged Ethernet):以太网生态的 “妥协实用派”
RoCE 的使命是在标准以太网上实现 RDMA 的高性能。但 RDMA 天生需要 “无损网络”,而传统以太网是 “尽力而为” 的有损网络,因此 RoCE 做了两大关键改造:
- 流量控制与拥塞管理:通过优先级流量控制(PFC),让交换机在端口缓存将满时,向发送方发 “暂停帧”,强制其停止特定优先级流量,实现局部无损;再通过 ** 显式拥塞通知(ECN)** 与端到端拥塞控制(如 DCQCN),让交换机在检测到拥塞时给数据包打标,由接收端反馈给发送端降速,实现预防性拥塞管理;
- 协议封装:将 RDMA 数据包封装在 UDP/IP 包里,让其能被标准三层网络设备路由,同时在 InfiniBand 传输头中携带 RDMA 操作所需的 “目标内存地址、操作码” 等信息。

- UDP/IP 头: 使得数据包可以被标准的三层网络设备路由。
- InfiniBand 传输头: 里面包含了RDMA操作所需的全部信息(如操作码、目标内存地址、密钥等)
RoCEv2 的优势是兼容现有以太网基础设施,能让 RDMA 流量与 TCP/IP 流量在同一张物理网络共存,大幅降低部署成本;但代价是配置复杂度高——PFC、ECN、交换机缓冲区等需精细配置,否则性能会急剧下降,且由于共享网络,延迟与吞吐量的 “可预测性、稳定性” 不如 InfiniBand。它更适合对成本敏感、需融合现有网络的云数据中心。
3.3 iWARP:TCP 之上的 “兼容试水派”
iWARP 允许在 TCP 协议上执行 RDMA,同样兼容以太网,但需将整个 TCP/IP 协议栈卸载到硬件(如专用网卡)。这种设计的局限明显:TCP 本身的 “拥塞控制、重传机制” 会引入额外延迟,且硬件卸载 TCP 栈的成本与复杂度高,导致 iWARP 的性能(延迟、吞吐量)远不如 InfiniBand 与 RoCEv2,仅在对兼容性要求极高、对性能要求相对宽松的场景有少量应用。
四、范式革命的成果:绕开远程 CPU
RDMA 带来的 “从发送消息到访问内存” 的范式革命,取得了突破性成果:
4.1 彻底绕开远程 CPU
在 RDMA 的 “内存语义” 下,远程 CPU 无需参与数据传输的核心流程 —— 发送方应用可直接指定 “远程内存地址”,由 RDMA 网卡通过硬件完成 “数据从本地内存到远程内存” 的传输,远程 CPU 既不用处理协议栈,也不用参与数据接收后的拷贝与分发,真正实现了 “无 CPU 干预的端到端通信”。以 AI 训练为例,GPU 可通过 RDMA 直接从远程 GPU 内存中拉取参数梯度,无需 CPU 中转,使通信延迟从数十微秒降至数微秒,算力利用率提升 30% 以上。
4.2 异构设备的 “对等访问” 成为可能
RDMA 让 CPU、GPU、DPU 等异构计算设备,都能以 “内存访问” 的方式交互 ——GPU 可直接写数据到远程 CPU 的内存,DPU 可直接读取远程 GPU 的计算结果,无需关注对方的 “设备类型”,为 “分布式异构计算像单机一样协同” 打开了大门。
但 RDMA 并非 “终极方案”,它仍留下了关键遗憾:异构计算单元间的缓存一致性未被解决。
在单机系统中,CPU 与 GPU 通过缓存一致性协议(如 PCIe 的缓存一致扩展),能保证彼此缓存数据的实时同步,让 “异构协同” 像 “同构核心” 一样流畅。但在 RDMA 构建的分布式系统中,不同服务器的 CPU、跨服务器的 GPU 等异构单元,其缓存之间并无统一的一致性协议 —— 当 A 服务器的 CPU 修改了某块内存,B 服务器的 GPU 缓存中该内存的旧数据无法实时更新,若 B 服务器 GPU 基于旧数据计算,会导致结果错误。这种 “缓存不一致” 的问题,让 RDMA 虽实现了 “内存直接访问”,却无法达到 “单机异构协同” 的 “终极效率”,成为分布式计算向 “一台计算机” 演进的最后一道坎。
五、结语:范式革命的里程碑与未尽之题
RDMA 以 “内存语义” 颠覆了传统通信范式,将网络从 “消息管道” 升级为 “分布式内存总线”,彻底绕开远程 CPU,为 AI、HPC 等场景带来质的飞跃。但 “异构缓存一致” 的缺失,意味着它只是 “从群岛到大陆” 征程中的关键一步,而非终点。要实现 “一台真正的分布式计算机” 的终极愿景,还需在 RDMA 的基础上,进一步突破 “异构缓存一致性” 的技术壁垒 —— 这也正是下一篇将探讨的,以 CXL 为代表的 “融合架构” 所承载的使命。
《范式革命:RDMA 如何让网络成为 “分布式内存总线”》 是转载文章,点击查看原文。


