摘要
本研究运用随机森林回归模型对汽车价格进行预测。通过对包含多种汽车属性的数据集进行预处理,包括对分类变量的独热编码,将其划分为训练集与测试集。利用训练集数据拟合随机森林模型,并使用测试集数据进行预测与评估。同时,借助多种可视化手段深入分析模型性能与数据特征。
数据集:https://pan.quark.cn/s/20eb55d25902
数据源:https://www.kaggle.com/datasets/vrajesh0sharma7/used-car-price-prediction
关键词
随机森林回归;汽车价格预测;数据预处理;可视化分析
一、引言
在汽车市场研究领域,准确预测汽车价格对于消费者、经销商以及制造商都具有重要意义。随机森林回归模型作为一种强大的机器学习算法,能够有效处理复杂的非线性关系,在众多预测任务中表现出色。本研究旨在运用该模型对汽车价格进行精准预测,并通过详细的分析揭示各因素对价格的影响。
二、数据处理与模型构建
2.1 数据加载
研究伊始,从“split_file_1.csv”文件中加载数据集,该数据集涵盖了丰富的汽车相关信息,为后续分析提供了基础。
1import pandas as pd 2df = pd.read_csv('split_file_1.csv') 3
2.2 数据预处理
为使数据适用于模型训练,对数据进行了必要的预处理。鉴于数据集中存在诸多分类变量,如汽车品牌(make)、型号(model)、变速器类型(transmission)等,采用独热编码的方式对这些分类变量进行转换。此操作将分类变量转换为数值形式,以便模型能够有效处理。
1categorical_cols = ['make','model', 'transmission', 'fuel_type', 'drivetrain', 'body_type', 'exterior_color', 'interior_color','seller_type', 'condition', 'trim', 'accident_history'] 2df_encoded = pd.get_dummies(df, columns=categorical_cols) 3
完成编码后,将数据集划分为特征矩阵X和目标变量y。特征矩阵X包含除价格(price)外的所有变量,而目标变量y即为汽车价格。
1X = df_encoded.drop(['price'], axis=1) 2y = df_encoded['price'] 3
2.3 数据集划分
为评估模型性能,将数据集按比例划分为训练集和测试集。其中,测试集占比20%,训练集占比80%,并通过设置随机种子(random_state = 33)确保划分结果的可重复性。
1from sklearn.model_selection import train_test_split 2X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=33) 3
2.4 模型定义与训练
选择随机森林回归模型作为预测工具,并设定决策树数量为100(n_estimators = 100),同时固定随机种子(random_state = 33)以保证模型训练的一致性。随后,使用训练集数据对模型进行训练。
1from sklearn.ensemble import RandomForestRegressor 2rf_model = RandomForestRegressor(n_estimators=100, random_state=33) 3rf_model.fit(X_train, y_train) 4
三、模型预测与评估
3.1 模型预测
利用训练好的随机森林模型对测试集数据进行预测,得到预测价格y_pred。
1y_pred = rf_model.predict(X_test) 2
3.2 模型评估
为衡量模型的预测准确性,采用均方误差(MSE)、均方根误差(RMSE)和R²分数作为评估指标。均方误差反映了预测值与真实值之间误差的平方的平均值;均方根误差则是均方误差的平方根,其单位与目标变量相同,更直观地体现了误差的大小;R²分数用于评估模型对数据的拟合优度,取值范围在0到1之间,越接近1表示模型拟合效果越好。
1from sklearn.metrics import mean_squared_error, r2_score 2import numpy as np 3mse = mean_squared_error(y_test, y_pred) 4rmse = np.sqrt(mse) 5r2 = r2_score(y_test, y_pred) 6 7print(f"均方误差 (MSE): {mse}") 8print(f"均方根误差 (RMSE): {rmse}") 9print(f"R² 分数: {r2}") 10
经计算,模型在本数据集上取得了一定的预测效果,具体指标数值为深入分析模型性能提供了依据。
四、可视化分析
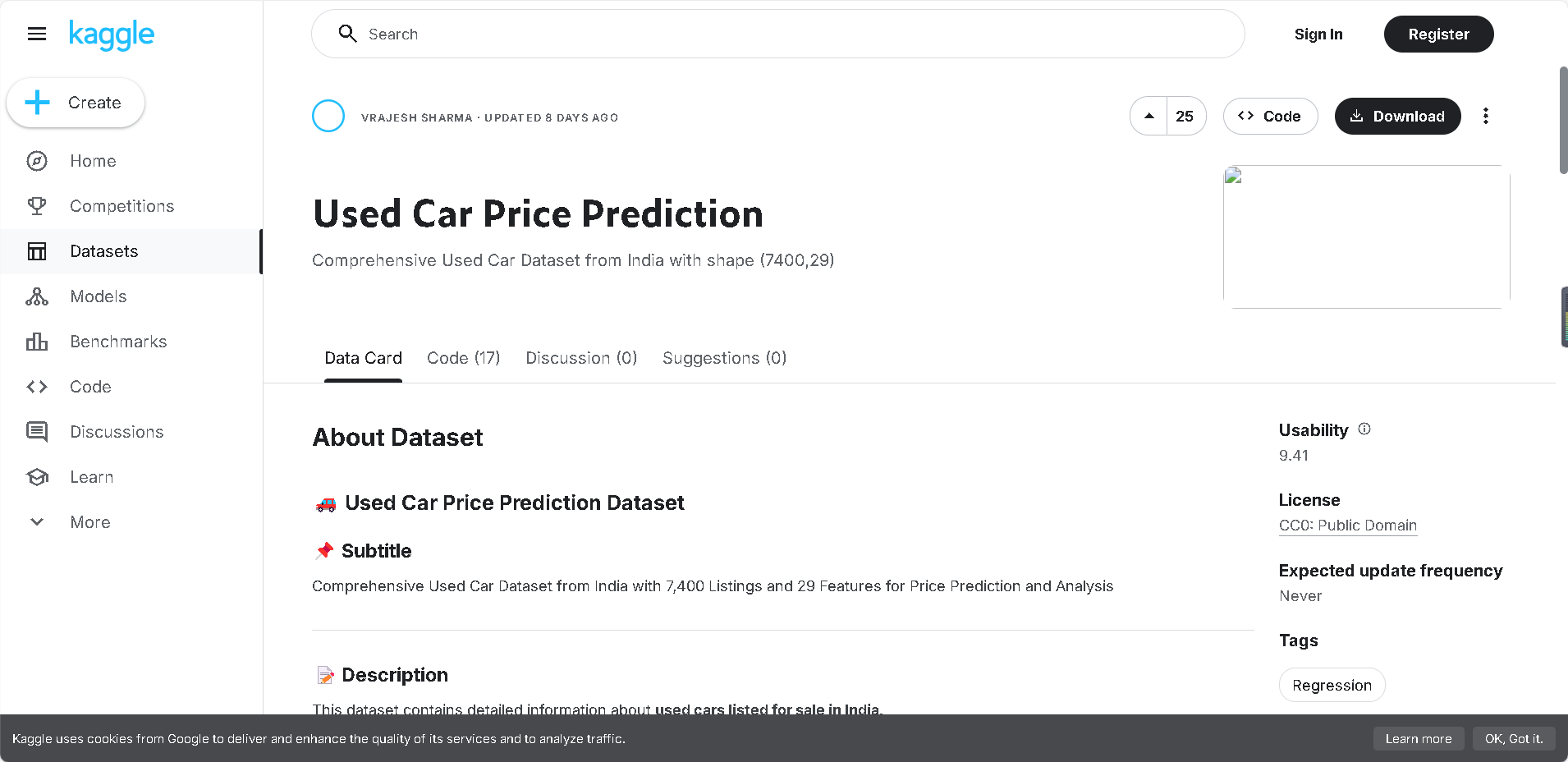
4.1 实际价格与预测价格对比
绘制实际价格与预测价格的散点图,同时添加一条表示理想预测情况(预测值等于真实值)的对角线。该图直观展示了模型预测值与实际值的分布关系,若预测点紧密分布在对角线上方,则表明模型预测效果良好。
1import matplotlib.pyplot as plt 2plt.figure(figsize=(10, 6)) 3plt.scatter(y_test, y_pred, alpha=0.5) 4plt.plot([y.min(), y.max()], [y.min(), y.max()], 'k--', lw=2) 5plt.xlabel('实际价格') 6plt.ylabel('预测价格') 7plt.title('实际价格 vs 预测价格') 8plt.show() 9
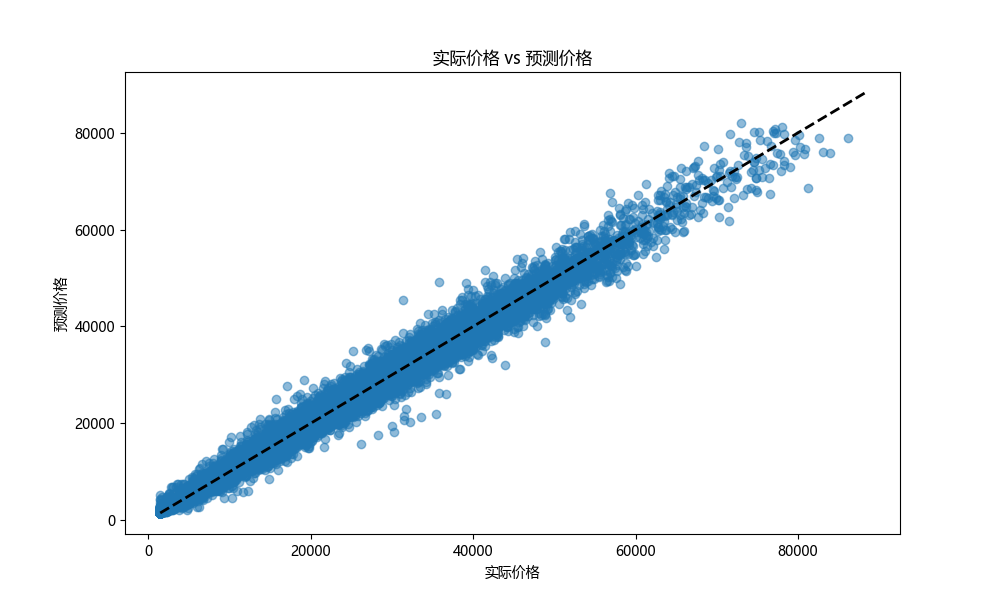
4.2 残差分析
计算并绘制残差图,以预测价格为横坐标,残差(实际价格 - 预测价格)为纵坐标,并添加一条水平参考线(y = 0)。理想情况下,残差应随机分布在参考线周围,无明显规律。若残差呈现特定趋势,则可能暗示模型存在一定问题。
1residuals = y_test - y_pred 2plt.figure(figsize=(10, 6)) 3plt.scatter(y_pred, residuals, alpha=0.5) 4plt.axhline(y=0, color='r', linestyle='--') 5plt.xlabel('预测价格') 6plt.ylabel('残差') 7plt.title('残差图') 8plt.show() 9
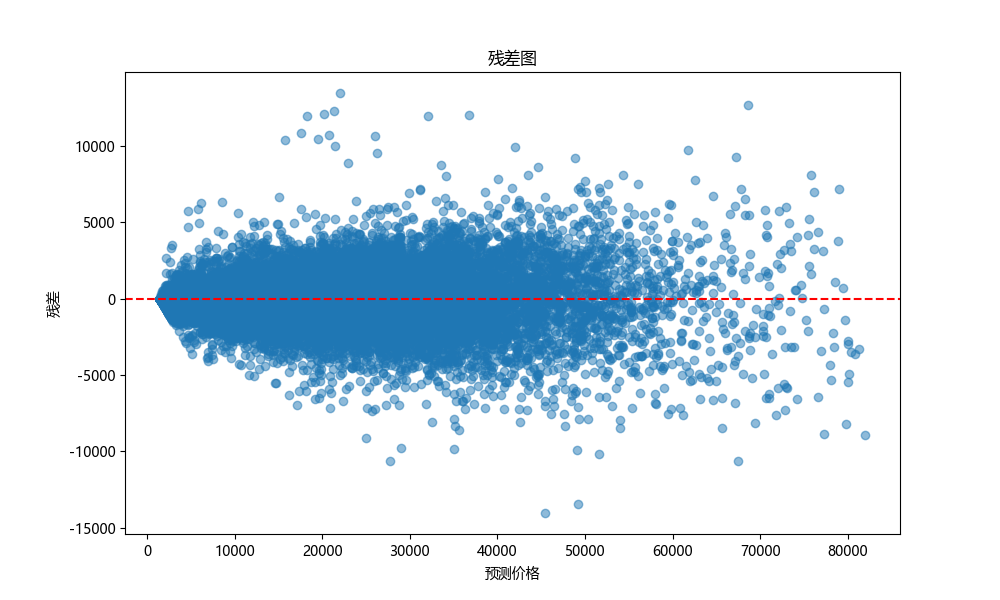
4.3 特征重要性评估
通过分析随机森林模型中各特征的重要性,筛选出最重要的20个特征,并绘制特征重要性条形图。该图能够直观展示各特征对汽车价格预测的贡献程度,帮助我们理解哪些因素在价格决定中起着关键作用。
1importances = rf_model.feature_importances_ 2indices = np.argsort(importances)[-20:] 3plt.figure(figsize=(10, 8)) 4plt.title('随机森林特征重要性') 5plt.barh(range(len(indices)), importances[indices], align='center') 6plt.yticks(range(len(indices)), [X.columns[i] for i in indices]) 7plt.xlabel('特征重要性') 8plt.show() 9
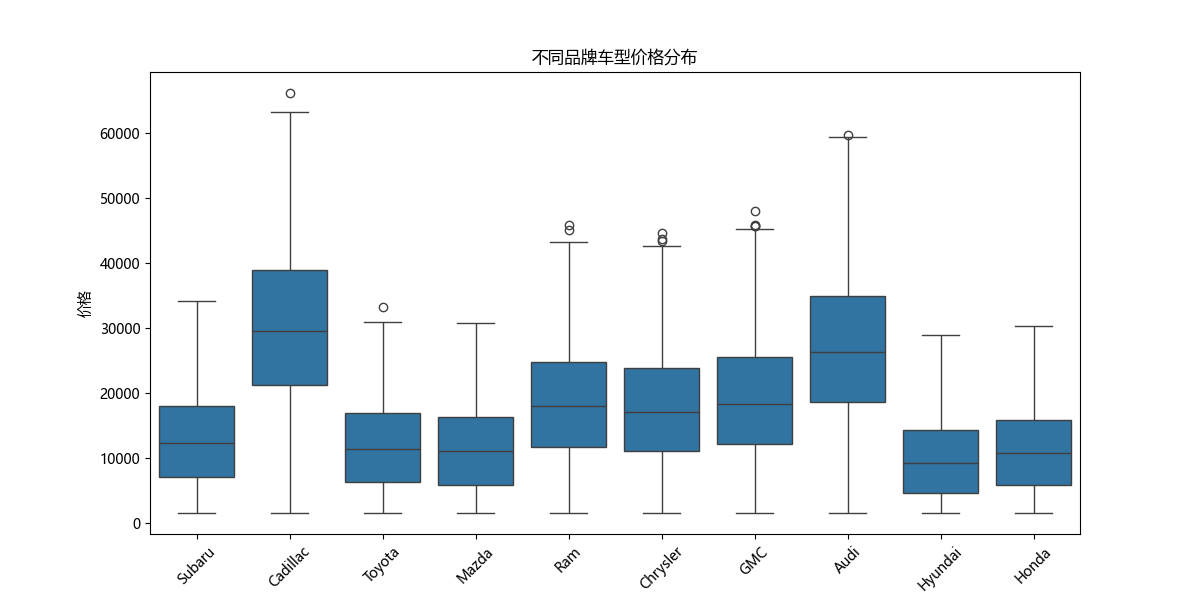
4.4 不同品牌价格分布
选取汽车品牌(make)作为分析对象,展示数量最多的10个品牌的汽车价格分布情况。通过箱线图,可以清晰观察到不同品牌汽车价格的中位数、四分位数以及异常值等信息,有助于深入了解各品牌在价格方面的差异。
1import seaborn as sns 2plt.figure(figsize=(12, 6)) 3top_makes = df['make'].value_counts().nlargest(10).index 4sns.boxplot(data=df[df['make'].isin(top_makes)], 5 x='make', 6 y='price') 7plt.xticks(rotation=45) 8plt.title('不同品牌车型价格分布') 9plt.xlabel('汽车品牌') 10plt.ylabel('价格') 11plt.show() 12
五、结论
本研究通过运用随机森林回归模型对汽车价格进行预测,并结合多种可视化分析手段,深入探讨了汽车价格与各属性之间的关系。模型评估指标表明,随机森林回归模型在本数据集上具有一定的预测能力。可视化分析不仅直观展示了模型的性能,还揭示了不同特征对汽车价格的影响程度以及不同品牌价格的分布特点。
《【数据挖掘】基于随机森林回归模型的二手车价格预测分析(数据集+源码)》 是转载文章,点击查看原文。


