在端到端自动驾驶领域,传统扩散模型应用面临计算开销大、模态坍缩问题,现有多模态规划方法依赖大量锚点。华中科技大学与地平线机器人团队提出的 DiffusionDrive,创新设计截断扩散策略(锚定高斯分布 + 2 步去噪)与级联扩散解码器,在 NAVSIM 达 88.1 PDMS,NVIDIA 4090 上 45 FPS,兼顾性能与实时性。
原文链接:https://arxiv.org/pdf/2411.15139
代码链接:https://github.com/hustvl/DiffusionDrive
沐小含持续分享前沿算法论文,欢迎关注...
一、引言
1.1 研究背景与核心痛点
端到端自动驾驶凭借数据驱动的优势,逐渐成为替代传统规则式运动规划的主流方向。这类方法直接从原始传感器输入中学习驾驶策略,无需人工设计复杂的中间模块,在复杂真实驾驶场景中展现出更强的泛化能力。当前主流的端到端规划器(如 Transfuser、UniAD、VAD)多采用单模态轨迹回归范式,通过 ego-query 输出一条最优轨迹,但这种方式无法应对驾驶行为固有的不确定性和多模态特性 —— 例如遇到障碍物时,车辆既可以减速避让,也可以选择变道绕行,单模态输出难以覆盖所有合理决策。
为解决多模态规划问题,VADv2 提出了基于固定锚点词汇表的方案,通过预定义 4096 条锚点轨迹离散化动作空间,再根据预测分数采样轨迹。然而,这种方法存在两大局限:一是锚点的数量和质量直接限制了模型的泛化能力,在锚点未覆盖的场景(out-of-vocabulary)中易失效;二是大量锚点带来了沉重的计算负担,难以满足自动驾驶的实时性要求。
扩散模型作为一种强大的生成式建模工具,在机器人策略学习中已被证明能够有效建模多模态动作分布,其通过迭代去噪过程从高斯分布中直接采样物理上合理的多模态动作。这启发研究者将扩散模型引入端到端自动驾驶领域,但直接应用面临两大核心挑战:
- 计算开销过大:传统扩散策略(如 DDIM)需要 20 步以上的去噪迭代,导致推理速度极慢,无法满足自动驾驶实时性需求;
- 模态坍缩问题:在动态开放的交通场景中,从随机高斯噪声采样的轨迹经过去噪后易出现严重重叠,难以生成真正多样化的合理决策。
1.2 核心贡献
针对上述问题,论文提出了 DiffusionDrive—— 一种基于截断扩散策略和高效级联扩散解码器的端到端自动驾驶模型。其核心贡献可概括为以下四点:
- 首次将扩散模型引入端到端自动驾驶领域,提出截断扩散策略(Truncated Diffusion Policy),解决了传统扩散模型直接应用时的模态坍缩和计算开销过大问题;
- 设计了高效的基于 Transformer 的扩散解码器,通过级联机制增强与条件场景上下文的交互,提升轨迹重建质量;
- 在 NAVSIM 数据集上取得 88.1 PDMS 的刷新纪录成绩,且在 NVIDIA 4090 上实现 45 FPS 的实时推理速度,无需任何后处理技巧;
- 定性实验验证了模型在复杂场景中能够生成多样化、合理的多模态驾驶轨迹,展现出更强的场景适应性。
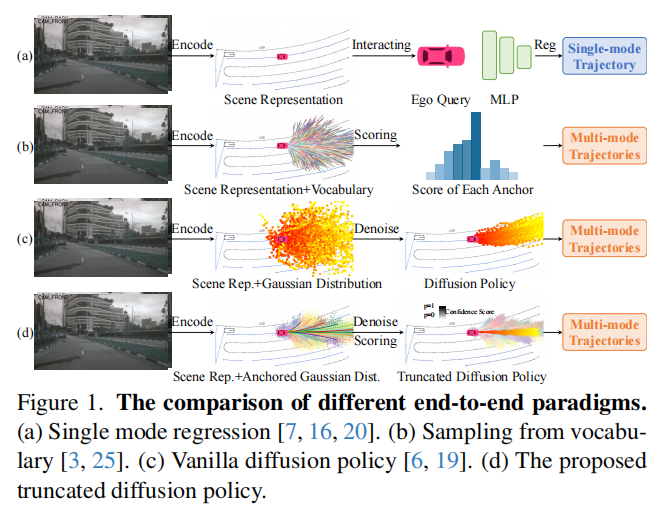
1.3 方法对比
论文通过图 1 清晰展示了 DiffusionDrive 与现有主流范式的差异:
- 图 1 (a):单模态回归范式(如 Transfuser),直接输出一条最优轨迹,缺乏多样性;
- 图 1 (b):锚点词汇表采样范式(如 VADv2),依赖大量预定义锚点,泛化性和实时性受限;
- 图 1 (c):传统扩散策略,从随机高斯噪声开始去噪,需多步迭代且易模态坍缩;
- 图 1 (d):DiffusionDrive 的截断扩散策略,从锚定高斯分布(Anchored Gaussian Distribution)开始去噪,仅需少量步骤即可生成多模态轨迹。
二、相关工作
2.1 端到端自动驾驶
早期的 UniAD 通过融合多感知任务提升规划性能,VAD 则采用紧凑的向量化场景表示优化效率。后续一系列工作(如 Transfuser、PARA-Drive)均延续了单轨迹规划范式。近年来,VADv2 转向多模态规划,通过大规模固定锚点词汇表实现轨迹采样;Hydra-MDP 进一步优化了 VADv2 的评分机制,引入规则基评分器的额外监督。与这些方法不同,DiffusionDrive 采用生成式扩散模型,无需依赖固定锚点词汇表,即可实现高效的多模态规划。
2.2 交通仿真中的扩散模型
MotionDiffuser、CTG 等工作将扩散模型应用于多智能体运动预测,但仅依赖抽象的感知真值,难以直接迁移到真实自动驾驶场景。CTG++ 引入大语言模型实现语言驱动的交通仿真,Diffusion-ES 则用进化搜索替代奖励梯度引导的去噪。DiffusionDrive 突破了扩散模型在交通仿真中的局限,通过截断扩散策略和高效解码器,实现了真实场景下的实时端到端驾驶。
2.3 机器人策略学习中的扩散模型
Diffusion Policy 证明了扩散模型在机器人策略学习中建模多模态动作分布的潜力,Diffuser 则通过无分类器引导和图像修复实现引导采样。后续工作将扩散模型应用于机械臂操作、移动机器人导航等任务,但这些场景的动态性和开放性远低于自动驾驶,直接迁移会面临实时性和轨迹合理性的挑战。DiffusionDrive 提出的截断扩散策略是针对自动驾驶场景的创新设计,尚未在机器人领域被探索。
2.4 图像生成中的扩散模型
DDIM 通过非马尔可夫扩散过程实现少步高效采样,Flow Matching 直接建模连续概率流优化生成过程,TDPM 提出截断去噪以加速采样。与这些方法不同,DiffusionDrive 引入了显式的驾驶先验(锚定高斯分布),引导扩散过程生成更精准、高效的驾驶轨迹,专门适配端到端自动驾驶需求。
三、方法细节
3.1 任务定义与扩散模型基础
3.1.1 任务 formulation
端到端自动驾驶的核心任务是:输入原始传感器数据(如相机图像、激光雷达点云),预测自车未来的轨迹序列 ,其中
为规划时域(论文中为 4 秒),
为自车坐标系下各时刻的路点位置。
3.1.2 条件扩散模型
条件扩散模型包含前向扩散和反向去噪两个过程:
- 前向扩散:逐步向干净的轨迹样本
中添加高斯噪声,生成含噪样本
,其分布定义为:
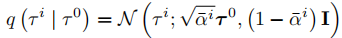
其中,
为噪声调度表,控制各步噪声添加强度。
- 反向去噪:训练模型
,在条件信息
(场景上下文)的引导下,从含噪样本
出发,通过迭代去噪逐步优化得到最终轨迹
3.2 传统扩散模型的问题分析
为验证传统扩散模型在自动驾驶中的适用性,论文将经典端到端规划器 Transfuser 改造为 TransfuserDP—— 替换其 MLP 回归头为条件 UNet 扩散模型,采用 20 步 DDIM 去噪。实验发现两个关键问题:
3.2.1 模态坍缩(Mode Collapse)
从高斯分布采样 20 个不同噪声,经过 20 步去噪后,轨迹严重重叠(图 2)。论文定义模态多样性分数 D(基于轨迹间的平均交并比 mIoU)定量评估:mIoU 越高,多样性越差。实验显示 TransfuserDP 的 D 仅为 11%,验证了模态坍缩的严重性。
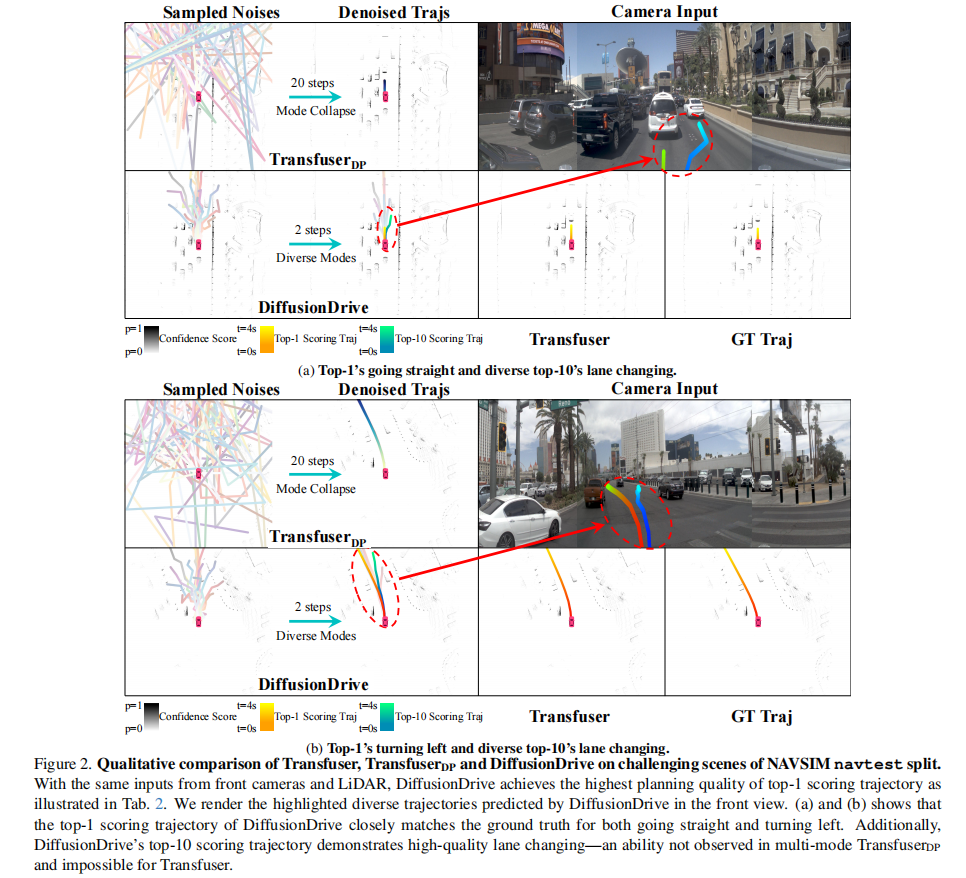
注:DiffusionDrive 的 Top-1 轨迹与真值高度吻合,Top-10 轨迹展现出多样化的变道行为,而 TransfuserDP 存在明显模态坍缩。
3.2.2 计算开销过大
20 步去噪导致规划模块总耗时达 130ms,FPS 仅为 7(表 2),远低于自动驾驶实时性要求(通常需 30 FPS 以上)。
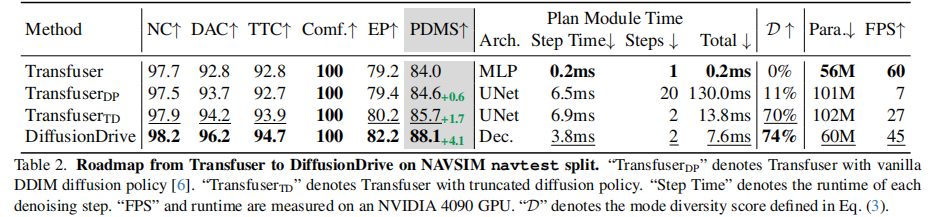
3.3 截断扩散策略(Truncated Diffusion Policy)
为解决传统扩散模型的缺陷,论文提出截断扩散策略,核心思想是引入驾驶先验锚点,缩短扩散过程。
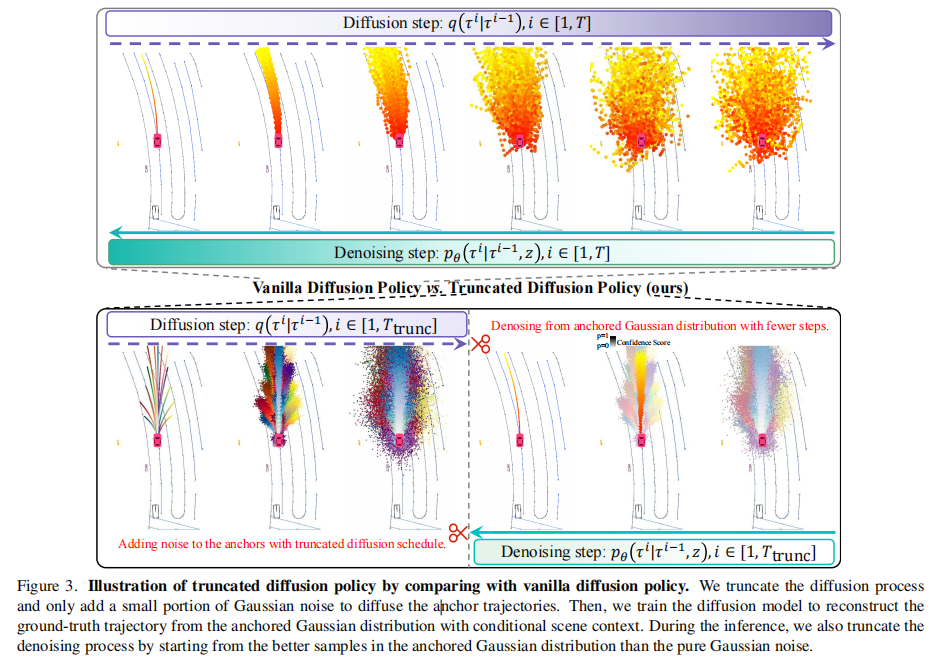
3.3.1 核心设计:锚定高斯分布
人类驾驶遵循固定模式,并会根据实时交通状况动态调整。受此启发,论文将高斯分布划分为多个以先验锚点为中心的子高斯分布,构成锚定高斯分布(Anchored Gaussian Distribution)。锚点通过 K-Means 聚类训练集中的人类驾驶轨迹得到,仅需 20 个锚点即可覆盖主要驾驶模式(远少于 VADv2 的 4096 个)。
3.3.2 截断扩散过程
- 训练阶段:截断扩散调度表,仅向锚点添加少量高斯噪声(而非完全扩散到随机噪声),让模型学习从锚定高斯分布到真实驾驶轨迹的去噪过程。截断后的扩散步数
(论文中
)。
- 推理阶段:从锚定高斯分布中采样含噪轨迹,而非随机高斯噪声,仅需 2 步去噪即可生成高质量轨迹。这种设计既保证了轨迹多样性(锚点覆盖主要模式,子高斯分布提供局部变异),又大幅降低了计算开销。
3.3.3 训练目标
训练时,模型输入 个含噪轨迹
,输出每个轨迹的分类分数
和去噪后的轨迹
。将与真值轨迹最接近的锚点对应的含噪轨迹设为正样本(
),其余为负样本(
),总损失为轨迹重建损失与二值交叉熵(BCE)分类损失的加权和:
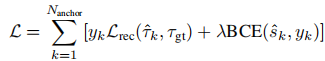
其中 为 L1 重建损失,
平衡两项损失的权重。
3.3.4 推理灵活性
模型训练时使用固定数量的锚点,但推理时可动态调整采样的含噪轨迹数量 ,根据计算资源和场景复杂度灵活权衡多样性与效率。
3.4 模型架构
DiffusionDrive 的整体架构如图 4 所示,主要包含感知模块和扩散解码器两部分:
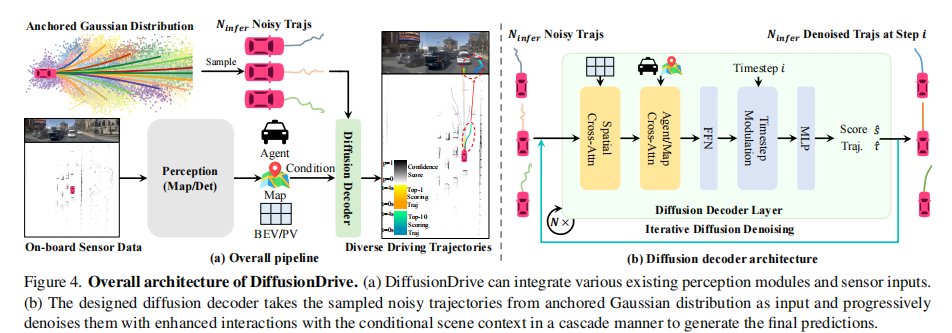
- 图 4 (a):整体流程,可集成现有各类感知模块,支持相机、激光雷达等多传感器输入;
- 图 4 (b):扩散解码器架构,采用级联设计,增强与场景上下文的交互。
3.4.1 扩散解码器细节
扩散解码器的核心目标是增强轨迹与场景上下文的交互,其结构包含以下关键组件:
- 可变形空间交叉注意力:基于轨迹坐标,与鸟瞰图(BEV)或透视视图(PV)特征进行交互,捕捉空间依赖;
- 智能体 / 地图交叉注意力:轨迹特征与感知模块输出的智能体查询、地图查询进行交互,理解交通参与者和道路结构;
- 时间步调制层:编码扩散时间步信息,让模型适应不同去噪阶段的特征优化需求;
- 前馈网络(FFN):对交互后的特征进行非线性变换;
- 级联机制:堆叠多个扩散解码器层,在每个去噪步骤中迭代优化轨迹重建质量,参数在不同去噪步骤间共享。
推理时,从锚定高斯分布采样的含噪轨迹输入解码器,经过多轮级联交互和去噪,最终选择置信度最高的轨迹作为输出。
四、实验验证
4.1 实验设置
4.1.1 数据集
- NAVSIM:面向规划的真实世界数据集,基于 nuPlan 构建,包含 360° 相机图像和融合激光雷达点云,标注频率 2Hz,侧重动态意图变化的复杂场景,排除了静止或匀速行驶等简单场景;
- nuScenes:经典自动驾驶数据集,场景相对简单,用于验证模型在常规场景下的泛化能力。
4.1.2 基线与参数配置
- 基线模型:Transfuser、UniAD、VADv2、Hydra-MDP 等主流端到端规划器;
- 骨干网络:NAVSIM 实验使用 ResNet-34(与基线一致),nuScenes 实验使用 ResNet-50;
- 训练配置:NAVSIM 上从头训练 100 轮,批大小 512,学习率 \(6×10^{-4}\);nuScenes 采用两阶段训练,基于 SparseDrive 的感知预训练权重微调 10 轮;
- 推理配置:NAVSIM 上使用 2 步去噪,采样 20 个含噪轨迹;nuScenes 上使用 2 步去噪,18 个锚点。
4.1.3 评估指标
- NAVSIM(闭环指标):PDMS(规划决策综合分数,加权融合无责任碰撞率 NC、可行驶区域合规性 DAC、碰撞时间 TTC、舒适性 Comf.、自车进度 EP);模态多样性分数 D(基于轨迹 mIoU);FPS(推理速度);
- nuScenes(开环指标):L2 误差(轨迹预测精度)、碰撞率、FPS。
4.2 定量结果
4.2.1 NAVSIM 数据集对比
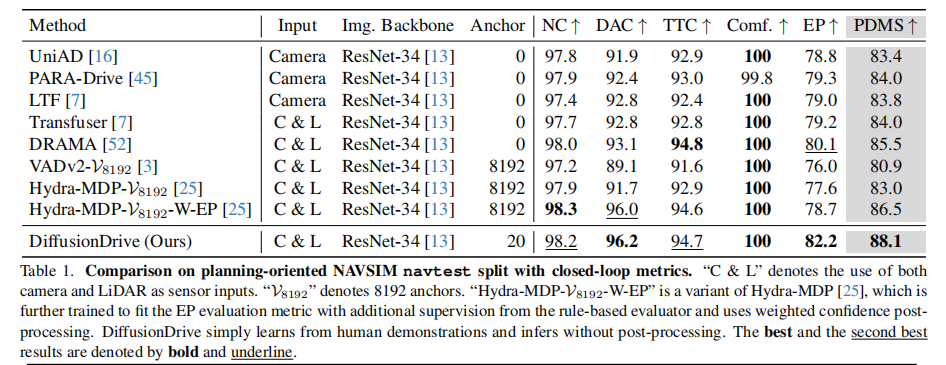
关键结论:
- DiffusionDrive 以 88.1 PDMS 刷新纪录,比次优的 Hydra-MDP-V8192-W-EP 高 1.6 分,且无需任何后处理(Hydra-MDP 采用了加权置信度后处理和额外规则监督);
- 锚点数量仅 20 个,相比 VADv2 的 8192 个减少 400 倍,大幅降低计算开销;
- 在所有子指标上均表现优异,尤其是 EP(自车进度)达到 82.2,远超其他方法,说明轨迹更具效率。
4.2.2 从 Transfuser 到 DiffusionDrive 的演进
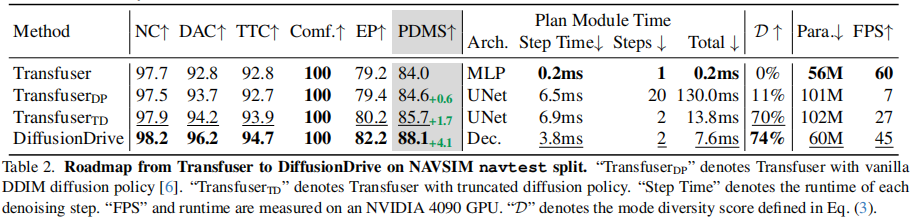
关键结论:
- TransfuserDP(传统扩散)虽提升 0.6 PDMS,但耗时增加 650 倍,FPS 仅 7,且模态多样性 D 仅 11%;
- TransfuserTD(仅截断扩散)将去噪步数从 20 减至 2,PDMS 提升 1.7 分,D 提升至 70%,FPS 达 27;
- DiffusionDrive(截断扩散 + 级联解码器)进一步提升 4.1 PDMS,D 达 74%,参数减少 40%,FPS 达 45,满足实时性要求。
4.2.3 nuScenes 数据集对比
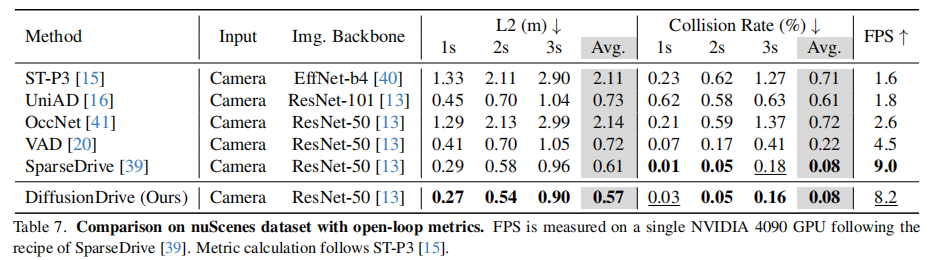
关键结论:
- DiffusionDrive 的平均 L2 误差仅 0.57m,比 VAD 低 20.8%;
- 碰撞率仅 0.08%,比 VAD 低 63.6%;
- FPS 达 8.2,是 VAD 的 4.6 倍,展现出优异的效率 - 性能权衡。
4.3 消融实验
4.3.1 扩散解码器设计选型
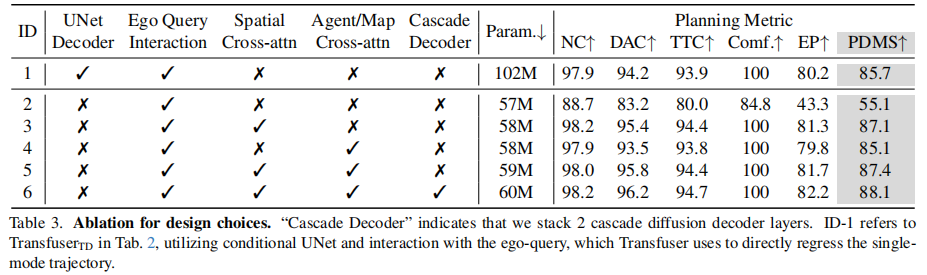
关键结论:
- 空间交叉注意力(ID3 vs ID2)是提升性能的关键,PDMS 从 55.1 提升至 87.1;
- 智能体 / 地图交叉注意力(ID5 vs ID3)进一步优化 DAC 和 EP,PDMS 提升 0.3 分;
- 级联机制(ID6 vs ID5)是最终突破的核心,PDMS 达到 88.1,且参数仅 60M(比 ID1 少 41%)。
4.3.2 去噪步数影响
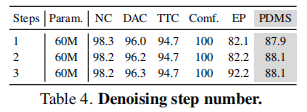
关键结论:仅 1 步去噪即可达到 87.9 PDMS,2 步后性能饱和,验证了锚定高斯分布的有效性 —— 无需多步迭代即可生成高质量轨迹。
4.3.3 级联阶段数影响
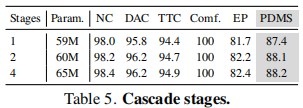
关键结论:2 级联阶段已能达到最优性能,进一步增加阶段数性能提升微小,但参数和耗时增加,因此选择 2 阶段为最优配置。
4.3.4 采样噪声数量影响
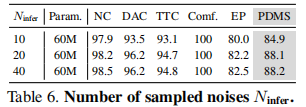
关键结论:采样 20 个噪声已能覆盖主要驾驶模式,PDMS 达 88.1,进一步增加采样数量性能提升有限,平衡效率与性能后选择 20 个采样噪声。
4.3.5 驾驶先验对比
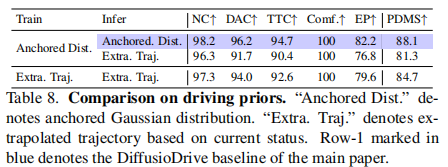
关键结论:基于锚定高斯分布的先验显著优于基于当前状态的外推轨迹先验,后者难以覆盖复杂场景的潜在动作空间(如避障、变道),验证了锚点设计的合理性。
4.4 定性分析
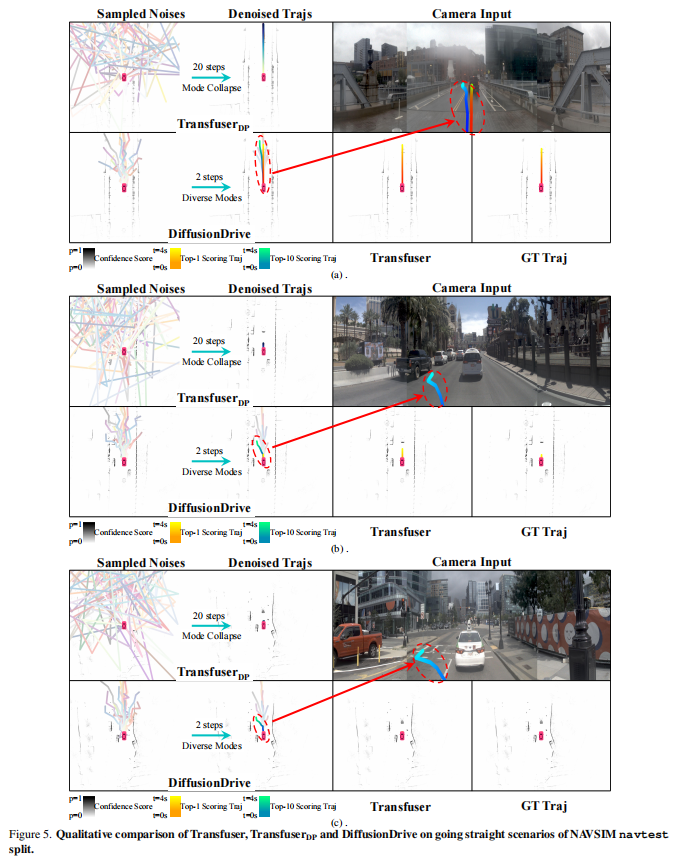
论文通过图 2、5、6、7 展示了 DiffusionDrive 在直行、左转、右转等复杂场景的表现:
- Top-1 轨迹与人类驾驶真值高度吻合,保证了基础驾驶安全性和合理性;
- Top-10 轨迹展现出多样化的合理决策(如变道超车、避障绕行、红绿灯前停车),而 TransfuserDP 存在严重模态坍缩,轨迹几乎重叠;
- 在动态场景中(如前方有慢车、路口转弯),DiffusionDrive 的轨迹能根据环境动态调整,展现出更强的场景适应性。
以图 2 (a) 为例,DiffusionDrive 的 Top-1 轨迹保持直行与真值一致,Top-10 轨迹则实现了高质量变道;
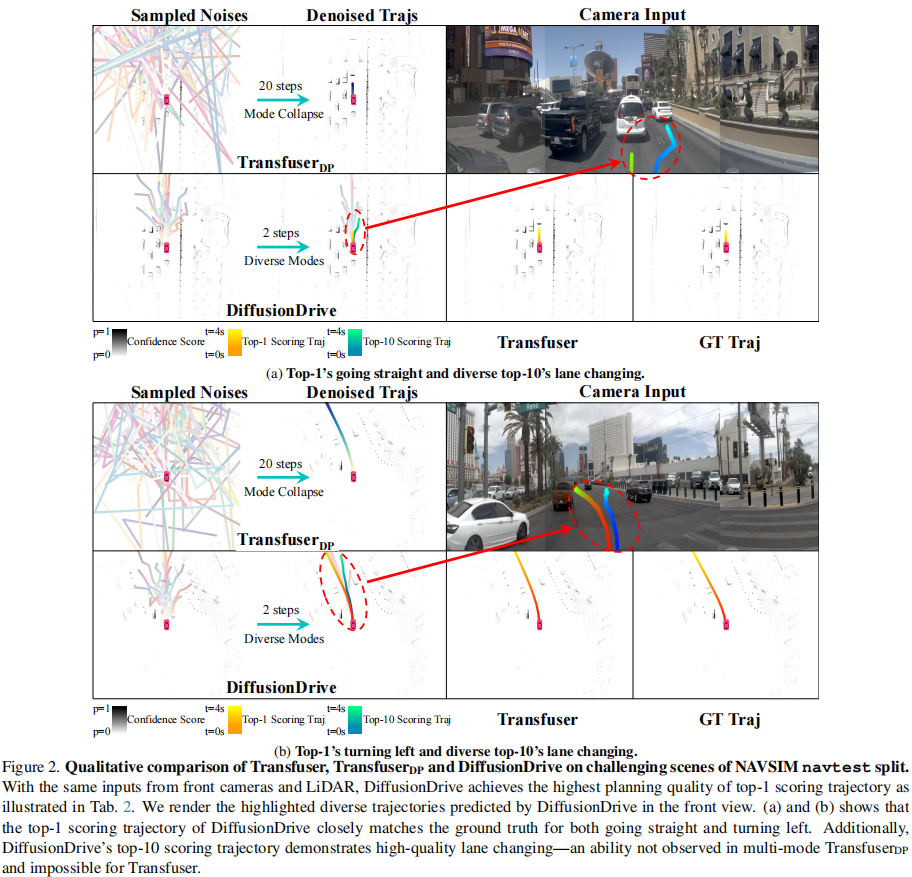
图 5 (c) 中,模型能识别红绿灯,生成在停止线前停车的合理轨迹,体现了对交通规则的理解。
五、结论与展望
5.1 核心总结
DiffusionDrive 首次将扩散模型成功应用于端到端自动驾驶,通过截断扩散策略和高效级联扩散解码器两大创新,解决了传统扩散模型的模态坍缩和计算开销问题。在 NAVSIM 和 nuScenes 数据集上的实验表明,模型在规划质量、实时性和模态多样性上均达到 state-of-the-art 水平,仅需 2 步去噪即可生成多样化、合理的驾驶轨迹,为端到端自动驾驶的多模态规划提供了全新解决方案。
5.2 未来方向
- 进一步优化锚点生成策略,结合场景动态信息自适应调整锚点分布,提升复杂场景泛化能力;
- 探索多模态传感器(如雷达、高精地图)与扩散解码器的更深层次融合,增强极端天气下的鲁棒性;
- 扩展规划时域,支持更长时间的轨迹预测,适应高速行驶等需要提前决策的场景;
- 结合强化学习进一步优化轨迹的长期收益,平衡安全性、效率和舒适性。
DiffusionDrive 的提出不仅推动了扩散模型在自动驾驶领域的应用,也为解决多模态规划问题提供了新的思路,有望加速端到端自动驾驶技术的落地。
《DiffusionDrive:面向端到端自动驾驶的截断扩散模型》 是转载文章,点击查看原文。



