1. list 基本概念
什么是list?
双向链表:每个元素包含指向前后元素的指针,形成链式结构
核心特性(与vector/deque对比):
| 特性 | vector | deque | list |
|---|---|---|---|
| 随机访问 | ✅ O(1) | ✅ O(1) | ❌ O(n) |
| 头部插入删除 | ❌ O(n) | ✅ O(1) | ✅ O(1) |
| 尾部插入删除 | ✅ O(1) | ✅ O(1) | ✅ O(1) |
| 中间插入删除 | ❌ O(n) | ❌ O(n) | ✅ O(1) |
| 内存布局 | 连续 | 分段连续 | 完全分散 |

2. list 的基本使用
头文件和声明:
cpp
#include <list> using namespace std;
// 创建方式(与其他容器类似) list<int> lst1; // 空list list<int> lst2(10); // 10个元素,默认值0 list<int> lst3(5, 100); // 5个元素,每个都是100 list<int> lst4 = {1, 2, 3, 4, 5}; // 初始化列表 list<int> lst5(lst4); // 拷贝构造
3. list 的特有操作
高效的任意位置操作:
cpp
void list_special_operations() { list<int> lst = {1, 3, 5};
// 任意位置高效插入(与vector/deque的最大区别!)
auto it = lst.begin();
advance(it, 1); // 移动到第2个位置
lst.insert(it, 2); // 在位置1插入2: {1,2,3,5} - O(1)!
// 任意位置高效删除
it = lst.begin();
advance(it, 2); // 移动到第3个位置
lst.erase(it); // 删除3: {1,2,5} - O(1)!
// 头部尾部操作(与deque相同)
lst.push_front(0); // 头部插入: {0,1,2,5}
lst.push_back(6); // 尾部插入: {0,1,2,5,6}
lst.pop_front(); // 头部删除: {1,2,5,6}
lst.pop_back(); // 尾部删除: {1,2,5}
}
4. list 的容量管理
与vector/deque的对比:
cpp
void list_capacity() { list<int> lst = {1, 2, 3, 4, 5};
// 这些与其他容器相同:
cout << "大小: " << lst.size() << endl; // 5
cout << "是否为空: " << lst.empty() << endl; // false
lst.resize(10); // 扩容到10个元素
lst.resize(3); // 缩容到3个元素
// list特有的容量操作:
cout << "最大大小: " << lst.max_size() << endl;
// 但没有这些(因为链表不需要):
// lst.capacity(); // ❌
// lst.reserve(100); // ❌
// lst.shrink_to_fit();// ❌
}
5. list 的元素访问
这是与vector/deque的最大区别!
cpp
void list_access() { list<int> lst = {10, 20, 30, 40, 50};
// 只能顺序访问,不能随机访问!
cout << lst.front() << endl; // 10 - 头部元素 ✅
cout << lst.back() << endl; // 50 - 尾部元素 ✅
// 这些都不行!
// cout << lst[2] << endl; // ❌ 没有下标访问!
// cout << lst.at(2) << endl; // ❌ 没有at()方法!
// int* data = lst.data(); // ❌ 没有data()方法!
// 访问中间元素的正确方式:
auto it = lst.begin();
advance(it, 2); // 移动到第3个位置 - O(n)!
cout << *it << endl; // 30
}
访问方式对比:
cpp
void access_comparison() { vector<int> vec = {1,2,3,4,5}; list<int> lst = {1,2,3,4,5};
// vector - 随机访问
cout << vec[2] << endl; // ✅ O(1) - 直接计算地址
// list - 顺序访问
auto it = lst.begin();
advance(it, 2); // ✅ O(n) - 需要遍历节点
cout << *it << endl;
}
6. list 的修改操作
链表特有的高效操作:
cpp
void list_modifications() { list<int> lst = {1, 2, 3, 4, 5};
// 1. 拼接操作 - 链表特有!
list<int> other = {6, 7, 8};
lst.splice(lst.end(), other); // 把other拼接到lst末尾
// lst: {1,2,3,4,5,6,7,8}, other: 空
// O(1)操作!只是修改指针
// 2. 元素移动 - 链表特有!
auto it = find(lst.begin(), lst.end(), 3);
lst.splice(lst.begin(), lst, it); // 把3移动到开头
// lst: {3,1,2,4,5,6,7,8} - O(1)!
}
7. list 的迭代器
双向迭代器(不是随机访问!):
cpp
void list_iterators() { list<int> lst = {10, 20, 30, 40, 50};
// 正向遍历 ✅
for (auto it = lst.begin(); it != lst.end(); ++it) {
cout << *it << " ";
}
// 反向遍历 ✅
for (auto rit = lst.rbegin(); rit != lst.rend(); ++rit) {
cout << *rit << " ";
}
// 这些都不行! ❌
auto it = lst.begin();
// cout << it[2] << endl; // 没有随机访问
// it = it + 3; // 没有算术运算
// if (it1 < it2) { } // 没有比较位置
// 只能这样移动:
advance(it, 2); // O(n) - 需要一步步走
// 或者:
++it; ++it; // 也是O(n)
}
迭代器稳定性(重要优势!):
cpp
void iterator_stability() { list<int> lst = {1, 2, 3, 4, 5}; auto it = lst.begin(); advance(it, 2); // 指向3
cout << "当前指向: " << *it << endl; // 3
// list的迭代器在插入删除时不会失效!
lst.push_front(0); // 头部插入
lst.push_back(6); // 尾部插入
lst.insert(lst.begin(), 99); // 任意位置插入
cout << "插入后仍然指向: " << *it << endl; // 还是3! ✅
// 即使删除其他元素,迭代器仍然有效
lst.erase(lst.begin()); // 删除头部
cout << "删除后仍然指向: " << *it << endl; // 还是3! ✅
// 只有删除迭代器指向的元素时才会失效
// lst.erase(it); // 此时it失效,不能再使用
}
这是list相比vector/deque的巨大优势!
8. list 的特有算法
成员函数版本的算法(比通用算法更高效):
cpp
void list_algorithms() { list<int> lst = {5, 2, 8, 2, 1, 2, 9, 3};
// 1. 排序 - 成员函数版本
lst.sort(); // 原地排序: {1,2,2,2,3,5,8,9}
// 比std::sort更高效,因为专门为链表优化
// 2. 去重 - 需要先排序
lst.unique(); // 去除连续重复: {1,2,3,5,8,9}
// 3. 合并 - 链表特有操作
list<int> lst2 = {4, 6, 7};
lst2.sort(); // 必须先排序
lst.merge(lst2); // 合并两个有序链表
// lst: {1,2,3,4,5,6,7,8,9}, lst2: 空
// 4. 反转
lst.reverse(); // 反转链表: {9,8,7,6,5,4,3,2,1}
}
为什么需要成员函数版本?
cpp
void why_member_algorithms() { list<int> lst = {3, 1, 4, 2};
// 错误:std::sort需要随机访问迭代器
// sort(lst.begin(), lst.end()); // ❌ 编译错误!
// 正确:使用list的成员函数
lst.sort(); // ✅ 专门为链表实现的排序算法
}
9. list 的内部实现原理
节点结构:
cpp
// list的每个节点大致如下: struct ListNode { T data; // 存储的数据 ListNode* prev; // 指向前一个节点 ListNode* next; // 指向后一个节点 };
内存布局:
text
list: [头节点] ↔ [节点1] ↔ [节点2] ↔ [节点3] ↔ ... ↔ [尾节点] ↑ ↑ ↑ ↑ prev/next prev/next prev/next prev/next
这种设计的优势:
cpp
void list_advantages() { list<int> lst;
// 1. 任意位置插入删除都是O(1)
for (int i = 0; i < 1000; i++) {
auto it = lst.begin();
advance(it, i % (lst.size() + 1));
lst.insert(it, i); // 在任意位置插入 - 总是O(1)!
}
// 2. 不需要重新分配内存
// 每个新元素独立分配节点,不会导致已有元素移动
}
10. 性能特点
时间复杂度:
| 操作 | 时间复杂度 | 说明 |
|---|---|---|
| 头部插入删除 | O(1) | 修改指针 |
| 尾部插入删除 | O(1) | 修改指针 |
| 中间插入删除 | O(1) | 找到位置后修改指针 |
| 随机访问 | O(n) | 需要从头遍历 |
| 查找 | O(n) | 顺序查找 |
空间开销:
cpp
void space_overhead() { list<int> lst = {1, 2, 3};
// 每个元素都有额外开销:
// - 指向前一个节点的指针
// - 指向后一个节点的指针
// - 内存分配开销(每个节点独立分配)
// 对于int类型,额外开销可能比数据本身还大!
// 在64位系统上:int(4字节) + 两个指针(16字节) = 20字节/元素
}
11. list 的典型应用场景
适合使用list的场景:
1. 频繁在任意位置插入删除
cpp
class TextEditor { private: list<char> text;
public: void insert(char c, size_t position) { auto it = text.begin(); advance(it, position); text.insert(it, c); // O(1)插入! }
void deleteChar(size_t position) {
auto it = text.begin();
advance(it, position);
text.erase(it); // O(1)删除!
}
void display() {
for (char c : text) cout << c;
cout << endl;
}
};
2. LRU缓存实现
cpp
class LRUCache { private: list<pair<int, int>> cache; // (key, value)对 unordered_map<int, list<pair<int, int>>::iterator> map; int capacity;
public: LRUCache(int cap) : capacity(cap) {}
int get(int key) {
if (map.find(key) == map.end()) return -1;
// 移动到头部(最近使用)
cache.splice(cache.begin(), cache, map[key]);
return map[key]->second;
}
void put(int key, int value) {
if (map.find(key) != map.end()) {
// 键已存在,更新值并移动到头部
map[key]->second = value;
cache.splice(cache.begin(), cache, map[key]);
} else {
// 新键,插入到头部
if (cache.size() == capacity) {
// 删除最久未使用的(尾部)
int lastKey = cache.back().first;
cache.pop_back();
map.erase(lastKey);
}
cache.emplace_front(key, value);
map[key] = cache.begin();
}
}
};
3. 音乐播放列表
cpp
class Playlist { private: list<string> songs; list<string>::iterator current;
public: Playlist(const vector<string>& initialSongs) { songs.assign(initialSongs.begin(), initialSongs.end()); current = songs.begin(); }
void addSong(const string& song, bool playNext = false) {
if (playNext) {
current = songs.insert(next(current), song);
} else {
songs.push_back(song);
}
}
void removeCurrent() {
current = songs.erase(current);
if (current == songs.end()) current = songs.begin();
}
void next() {
if (next(current) != songs.end()) ++current;
}
void previous() {
if (current != songs.begin()) --current;
}
};
12. 注意事项和最佳实践
1. 避免频繁的随机访问
cpp
void bad_practice() { list<int> lst(1000);
// 错误:频繁随机访问
for (int i = 0; i < lst.size(); i++) {
auto it = lst.begin();
advance(it, i); // 每次都是O(n)!
cout << *it << " "; // 总时间复杂度O(n²)!
}
// 正确:顺序访问
for (auto it = lst.begin(); it != lst.end(); ++it) {
cout << *it << " "; // 总时间复杂度O(n)
}
}
2. 利用迭代器稳定性
cpp
void use_iterator_stability() { list<int> lst = {1, 2, 3, 4, 5}; vector<list<int>::iterator> important_positions;
// 保存重要位置的迭代器
auto it = lst.begin();
advance(it, 2);
important_positions.push_back(it); // 指向3
// 进行各种修改操作...
lst.push_front(0);
lst.push_back(6);
lst.insert(lst.begin(), 99);
// 迭代器仍然有效!
cout << *important_positions[0] << endl; // 还是3!
}
13. 总结
list的核心优势:
- 任意位置O(1)插入删除
- 迭代器稳定性 - 插入删除不影响其他迭代器
- 不需要连续内存
- 特有的高效链表算法
list的缺点:
- 没有随机访问 - 只能顺序访问
- 内存开销大 - 每个元素都有指针开销
- 缓存不友好 - 内存不连续
以下是一些 std::list 的主要应用场景:
(1)频繁插入和删除操作:std::list 允许在序列中的任意位置进行常数时间的插入和删除操作。这使得它非常适合需要频繁添加或移除元素的场景,如日志记录、任务队列、事件处理等。
(2)双向迭代:std::list 支持双向迭代,这意味着可以轻松地遍历列表,向前或向后移动。这种特性在处理需要前后关联的数据时非常有用,如文本编辑器中的撤销与重做操作。
(3)保持元素顺序:std::list 通过链表结构保持元素的插入顺序。这对于需要维护元素原始顺序的场景(如数据库查询结果、事件历史记录等)非常有用。
(4)动态数据结构:当数据结构的大小经常变化时,std::list 是一个很好的选择。与基于数组的容器(如 std::vector)相比,std::list 在插入和删除元素时不需要移动大量数据,因此性能更高。
(5)内存管理:在某些情况下,可能希望更好地控制内存使用。std::list 允许管理每个元素的内存分配,这在处理大量数据或需要精确控制内存使用的场景中非常有用。
选择指南:
使用 list 当:
- ✅ 需要频繁在任意位置插入删除
- ✅ 需要稳定的迭代器
- ✅ 实现LRU缓存、undo操作等场景
- ✅ 内存碎片化严重
使用 vector/deque 当:
- ✅ 需要随机访问
- ✅ 主要进行尾部操作
- ✅ 重视缓存性能和内存效率
性能对比总结:
| 操作 | vector | deque | list |
|---|---|---|---|
| 尾部插入删除 | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐⭐ |
| 头部插入删除 | ⭐ | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐⭐ |
| 中间插入删除 | ⭐ | ⭐ | ⭐⭐⭐⭐⭐ |
| 随机访问 | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐ | ⭐ |
| 内存效率 | ⭐⭐⭐⭐⭐ | ⭐⭐⭐ | ⭐⭐ |
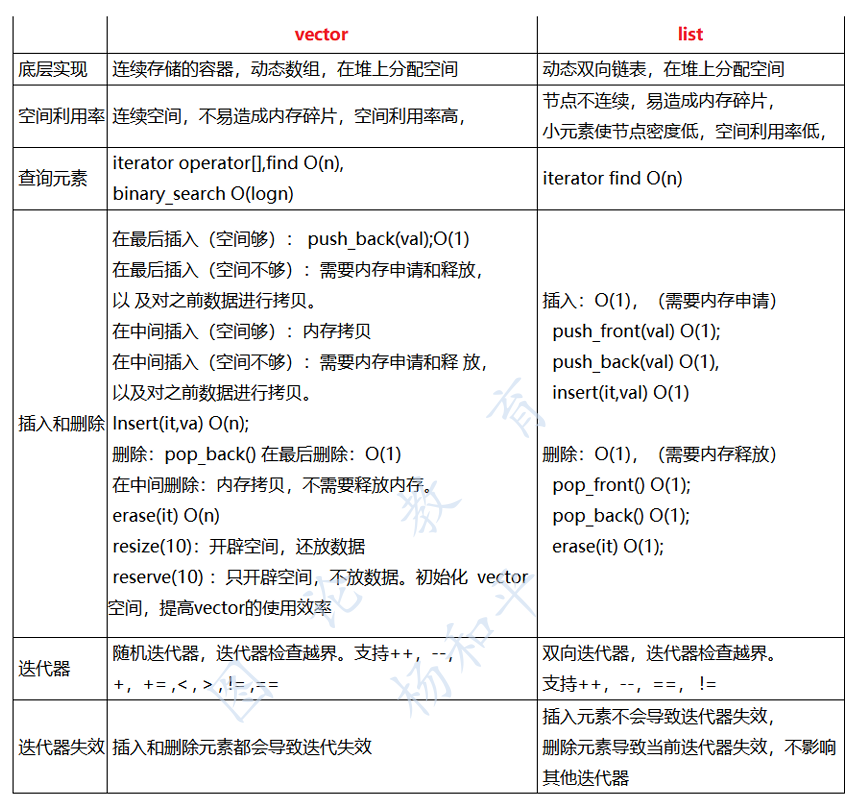
1)vector 底层实现是数组;list 是双向链表。
2)vector 支持随机访问,list 不支持。
3)vector 是顺序内存,list 不是。
4)vector 在中间节点进行插入删除会导致内存拷贝,list 不会。
5)vector 一次性分配好内存,不够时才进行 2 倍扩容(或 1.5 倍);list 每次插入新节点都会进行内存申请。
6)vector 随机访问性能好,插入删除性能差;list 随机访问性能差,插入删除性能好
一句话总结:
list = 任意位置高效操作 + 稳定迭代器 - 随机访问能力
list在特定场景下是不可替代的工具,理解它的特性可以让你在合适的时候做出最佳选择!
《C++笔记——STL list》 是转载文章,点击查看原文。
