
目录
k8s提供的核心能力
1. 自动化运维与自愈能力
2. 服务的弹性伸缩
3. 服务发现与负载均衡
4. 发布与回滚
5. 配置与秘钥管理
组件
核心组件
概念组件
扩展组件
下载安装
测试
kubectl命令
k8s提供的核心能力
k8s可以理解为一个
1. 自动化运维与自愈能力
这是 K8S 最吸引人的能力之一。
- 自动重启:如果容器崩溃,K8S 会自动重启它。
- 自动替换:如果整个节点(服务器)宕机,K8S 会检测到它上面的容器失效,并在其他健康节点上重新创建它们。
- 自动调度:你不需要手动指定容器在哪台机器上运行。K8S 的调度器会根据资源需求、策略等自动选择最合适的节点。
- 健康检查:K8S 可以定期检查应用是否健康(通过 HTTP 请求、执行命令、检查端口等方式)。如果应用不健康(如死锁、响应慢),它会主动重启或替换容器,而不是等待它完全崩溃。
业务价值:极大减少了人工运维干预,提供了极高的可用性,实现了 7x24 小时不间断服务。
2. 服务的弹性伸缩
K8S 可以轻松应对流量波动,实现资源的动态分配。
- 水平扩缩容:这是最常见的伸缩方式。流量大了,只需一个命令或配置一个规则,Pod(应用实例)的副本数量就能从 3 个增加到 10 个;流量低了,再缩回 3 个。这一切可以是手动的,也可以是全自动的(基于 CPU/内存使用率或自定义指标)。
- 自动扩缩容:结合 HPA,你可以设置规则,例如“当 CPU 平均使用率超过 80% 时,自动增加 Pod 数量”。
业务价值:既保证了应用在流量高峰期的稳定性,又避免了在低峰期资源的浪费,节约成本。
3. 服务发现与负载均衡
在微服务架构中,服务实例是动态变化的(IP 地址不固定,数量也会变)。K8S 内置机制解决了“如何找到并访问这些服务”的难题。
- 服务发现:每个服务都有一个稳定的虚拟 IP 地址(ClusterIP)和 DNS 名称。其他服务只需通过这个固定的名称就能访问它,无需关心它背后有多少个 Pod、IP 是什么。
- 负载均衡:K8S 自动将到达 Service 的请求均匀地分发到后端所有健康的 Pod 实例上。
业务价值:应用开发者无需在代码中硬编码服务地址或自己实现负载均衡,简化了开发,提升了架构的灵活性。
4. 发布与回滚
K8S 提供了多种控制流量切换的策略,使得发布新版本和出问题时回滚变得安全、可控。
- 蓝绿部署:同时部署新旧两套版本,通过一键切换所有流量到新版本。
- 金丝雀发布:先将一小部分流量(例如 5%)导入新版本,验证没问题后再逐步扩大比例,直至完全替换。
- 滚动更新:K8S 默认的更新策略。逐步创建新版本的 Pod,同时逐步终止旧版本的 Pod。在整个过程中,服务始终可用,没有中断。
- 一键回滚:如果新版本上线后发现问题,可以立即回滚到之前的稳定版本。
业务价值:大大降低了发布新版本的风险,提升了发布频率和可靠性,是实现 DevOps 和持续交付的基石。
5. 配置与秘钥管理
应用配置(如数据库地址、功能开关)和敏感信息(如密码、API 密钥)不应硬编码在容器镜像中。K8S 提供了安全的机制来管理它们。
- ConfigMap:用于存储应用的配置信息(明文)。
- Secret:用于存储敏感信息(会做 Base64 编码,但默认不加密,生产环境需配置加密)。
- 动态注入:你可以将 ConfigMap 和 Secret 作为环境变量或文件挂载到容器中。应用无需修改即可读取这些配置。当配置变更时,可以滚动更新 Pod 来使其生效。
业务价值:实现了应用配置与程序代码的分离,使得同一份镜像可以通过注入不同的配置,轻松地在开发、测试、生产环境中运行。秘钥管理更安全。
组件
核心组件
| 组件名称 | 主要功能 | 执行位置 | 特点 |
|---|---|---|---|
| kubelet (节点代理) | 管理 Pod 和容器生命周期、状态汇报、资源监控、卷管理、健康检查 | 所有节点(Master & Worker) | 集群中每个节点上都需运行的守护进程,与容器运行时和API Server交互 |
| kubeadm (集群部署工具) | 初始化集群、管理节点加入、升级集群版本 | 通常仅在初始化时使用于Master节点 | 用于快速部署标准化的Kubernetes集群,简化部署过程 |
| kubectl (集群管理命令行工具) | 部署应用、查看资源、管理集群状态、调试应用 | 任意可访问API Server的机器 | 用户与Kubernetes集群交互的主要命令行工具 |
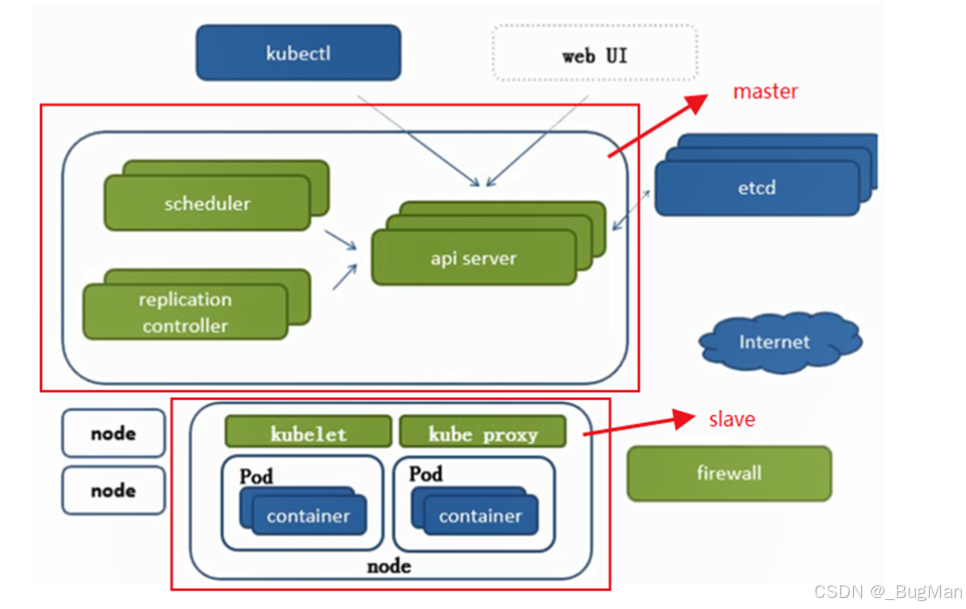
核心组件,k8s本身的组件:
- etcd:一个可信赖的分布式键值对存储服务,本质上就是一个键值对数据库。
- 主节点:
- scheduler:调度器,负责调度,计算出调度结果,交给api server。
- api server:所有服务访问的统一入口。
- replication controller:负责维护副本期望数目。
- 从节点:
- kube proxy:实现负载均衡、pod间通信。
- container:一般也就指的docker的容器。
- kubelet(节点代理):集群中每个节点上都需运行的守护进程,与容器运行时和API Server交互
- 其它
- kubectl:用户与Kubernetes集群交互的主要命令行工具
概念组件
除开核心组件外,还有一部分组件是k8s自身api的抽象,也就是说这些组件其实就是k8s自身的一部分能力,只是抽象出来单独做成了一个内嵌的组件,用到这部分组件时,通过编写yaml配置文件来配置:
| 名称 | 组件 | 能力 |
|---|---|---|
| 工作负载资源 | Pod, Deployment, StatefulSet , DaemonSet , Job, CronJob | 用于部署和管理应用程序 |
| 服务发现资源 | Service , Ingress | 定义如何访问应用程序以及将流量路由到应用程序 |
| 配置和存储资源 | ConfigMap , Secret , PersistentVolume (PV), PersistentVolumeClaim (PVC) | 为应用程序提供配置数据、敏感信息和持久化存储 |
| 集群与安全资源 | Namespace , ResourceQuota, ServiceAccount, Role, ClusterRole | 定义集群的结构、资源限制和访问控制 |
| 名称 | 能力 |
|---|---|
| namespace | 命名空间,用来进行资源隔离 |
| deployment | 用来描述应用的状态期望 |
| service | 用来声明配置网络相关的配置 |
| ingress | 用来对外暴露服务,类似于nginx |
| secret | 带加密功能的配置中心 |
| persistentvolumeclaim | 用来进行数据持久化 |
| statefulset | 用来对pod进行状态管理,当同一deployment中的pod要组成集群时给各个pod赋予角色 |
扩展组件
扩展组件是真正的实体组件,用来扩展k8s的能力。
下载安装
安装:
https://blog.csdn.net/qq%5F32060101/article/details/135688882
卸载:
https://blog.csdn.net/qq%5F32060101/article/details/135688669
安装
k8s安装至少需要2核2G的环境,否则会安装失败
lscpu
临时关闭swap ,如果不关闭在执行kubeadm部分命令会报错
swapoff -a
临时关闭selinux,减少额外配置
setenforce 0
关闭防火墙
systemctl stop firewalld systemctl disable firewalld
设置网桥参数
cat << EOF > /etc/sysctl.d/k8s.conf net.bridge.bridge-nf-call-ip6tables = 1 net.bridge.bridge-nf-call-iptables = 1 net.ipv4.ip_forward = 1 EOF
修改hosts文件 方便查看域名映射:
vim /etc/hosts #追加: 192.168.21.223 master
让配置生效:
service network restart 或者 /etc/init.d/network restart
修改hostname:
hostnamectl set-hostname master
安装docker:
yum install -y yum-utils device-mapper-persistent-data lvm2 yum-config-manager --add-repo https://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo yum -y install docker-ce
修改docker的 /etc/docker/daemon.json文件 如果没有该文件则直接创建:
设置国内阿里云docker源,地址改为自己在阿里云容器镜像服务申请的地址即可。
设置cgroupdriver为systemd,这步尤为重要(会导致后面初始化kubectl失败),笔者就是因为没设置走了很多弯路
sudo tee /etc/docker/daemon.json <<-'EOF' { "registry-mirrors": ["https://zydpncxr.mirror.aliyuncs.com"], "exec-opts": ["native.cgroupdriver=systemd"] } EOF
修改完成后 重启docker ,使docker与kubelet的cgroup 驱动一致
sudo systemctl daemon-reload sudo systemctl restart docker systemctl enable docker
安装kubeadm kubelet kubectl:
配置k8s下载资源配置文件(阿里云yum源)
cat <<EOF > /etc/yum.repos.d/kubernetes.repo [kubernetes] name=Kubernetes baseurl=https://mirrors.aliyun.com/kubernetes/yum/repos/kubernetes-el7-x86_64/ enabled=1 gpgcheck=1 repo_gpgcheck=1 gpgkey=https://mirrors.aliyun.com/kubernetes/yum/doc/yum-key.gpg https://mirrors.aliyun.com/kubernetes/yum/doc/rpm-package-key.gpg EOF
安装kubelet kubeadm kubectl:
yum install -y kubelet-1.23.5 kubeadm-1.23.5 kubectl-1.23.5
- kubelet :运行在cluster,负责启动pod管理容器
- kubeadm :k8s快速构建工具,用于初始化cluster
- kubectl :k8s命令工具,部署和管理应用,维护组件
查看是否安装成功:
kubelet --version kubectl version kubeadm version
启动kubelet:
systemctl daemon-reload systemctl start kubelet systemctl enable kubelet
拉取init-config配置 并修改配置 init-config 主要由 api server、etcd、scheduler、controller-manager、coredns等镜像构成:
kubeadm config print init-defaults > init-config.yaml
修改 刚才拉取的init-config.yaml文件,共3处修改:
- localAPIEndpoint.advertiseAddress
- nodeRegistration.name
- imageRepository
apiVersion: kubeadm.k8s.io/v1beta3 bootstrapTokens:
- groups:
- system:bootstrappers:kubeadm:default-node-token token: abcdef.0123456789abcdef ttl: 24h0m0s usages:
- signing
- authentication kind: InitConfiguration localAPIEndpoint: advertiseAddress: 10.77.69.150 //修改1 master节点IP地址 可cat /etc/hosts 看到 bindPort: 6443 nodeRegistration: criSocket: /var/run/dockershim.sock imagePullPolicy: IfNotPresent name: master //修改2 master节点node的名称 taints: null
apiServer: timeoutForControlPlane: 4m0s apiVersion: kubeadm.k8s.io/v1beta3 certificatesDir: /etc/kubernetes/pki clusterName: kubernetes controllerManager: {} dns: {} etcd: local: dataDir: /var/lib/etcd imageRepository: registry.aliyuncs.com/google_containers kind: ClusterConfiguration kubernetesVersion: 1.23.0 networking: dnsDomain: cluster.local serviceSubnet: 10.96.0.0/12 scheduler: {}
拉取k8s相关镜像:
kubeadm config images pull --config=init-config.yaml
如果镜像拉取失败,可以通过命令列出需要的镜像后逐个拉取,命令如下:
kubeadm config images list --config init-config.yaml
显示如下:
[root@master install]# kubeadm config images pull --config=init-config.yaml [config/images] Pulled registry.aliyuncs.com/google_containers/kube-apiserver:v1.23.0 [config/images] Pulled registry.aliyuncs.com/google_containers/kube-controller-manager:v1.23.0 [config/images] Pulled registry.aliyuncs.com/google_containers/kube-scheduler:v1.23.0 [config/images] Pulled registry.aliyuncs.com/google_containers/kube-proxy:v1.23.0 [config/images] Pulled registry.aliyuncs.com/google_containers/pause:3.6 [config/images] Pulled registry.aliyuncs.com/google_containers/etcd:3.5.1-0 [config/images] Pulled registry.aliyuncs.com/google_containers/coredns:v1.8.6
运行kubeadm init安装master节点 把192.168.21.223替换成你自己的网卡IP
kubeadm init --apiserver-advertise-address=192.168.21.223 --apiserver-bind-port=6443 --pod-network-cidr=10.244.0.0/16 --service-cidr=10.96.0.0/12 --kubernetes-version=1.23.5 --image-repository registry.aliyuncs.com/google_containers
成功后会有输出,千万要保存好相关输出:
尤其是这一部分,这一部分是后续的节点加入当前集群的命令:
kubeadm join 192.168.21.223:6443 --token <your-token>
--discovery-token-ca-cert-hash <your-ca-cert-hash>Your Kubernetes control-plane has initialized successfully! To start using your cluster, you need to run the following as a regular user: mkdir -p $HOME/.kube sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config sudo chown $(id -u):$(id -g) $HOME/.kube/config Alternatively, if you are the root user, you can run: export KUBECONFIG=/etc/kubernetes/admin.conf You should now deploy a pod network to the cluster. Run "kubectl apply -f [podnetwork].yaml" with one of the options listed at: https://kubernetes.io/docs/concepts/cluster-administration/addons/ Then you can join any number of worker nodes by running the following on each as root: kubeadm join 10.77.69.150:6443 --token efupb6.18yhyjp5byzfivpj
--discovery-token-ca-cert-hash sha256:3e8be0d920922b960cdd6e39384f465c246346ba87f7e5b80f9edf3a7679e483
根据上面的提示执行下面的命令:
mkdir -p $HOME/.kube sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config sudo chown $(id -u):$(id -g) $HOME/.kube/config
如果失败,就执行:
kubeadm reset
部署网络插件kube-flannel
wget https://raw.githubusercontent.com/coreos/flannel/master/Documentation/kube-flannel.yml kubectl apply -f kube-flannel.yml
(关键步骤)设置 master 节点允许调度, 默认不允许调度 pod
原因:当部署单机版的 k8s 时,这个时候 master 节点是默认不允许调度 pod 。导致创建的pod一直处于pending状态 执行以下命令, 将 master 标记为可调度即可。
kubectl taint nodes --all node-role.kubernetes.io/master-
后续节点如何加入原来的集群
不用执行kubeadm init命令,这个命令是用来初始化master的,只要照上面步骤安装好相关的k8s的核心组件即可,然后执行kubeadm join命令即可。
测试
发布一个Nginx的镜像作为测试:
demo_nginx_deployment.yaml
nginx 服务
apiVersion: v1 kind: Service metadata: name: demo-nginx labels: app: demo-nginx spec: type: NodePort ports: # node port 要求端口大于30000
- nodePort: 30013 port: 80 targetPort: 80 protocol: TCP selector: app: demo-nginx
nginx 部署 deployment
apiVersion: apps/v1 kind: Deployment metadata: name: demo-nginx labels: app: demo-nginx spec: replicas: 1 selector: matchLabels: app: demo-nginx template: metadata: labels: app: demo-nginx spec: containers: - name: demo-nginx image: docker.io/nginx:latest imagePullPolicy: IfNotPresent ports: - containerPort: 80 resources: requests: memory: "1Gi" cpu: "200m"
发布:
kubectl apply -f demo_nginx_deployment.yaml
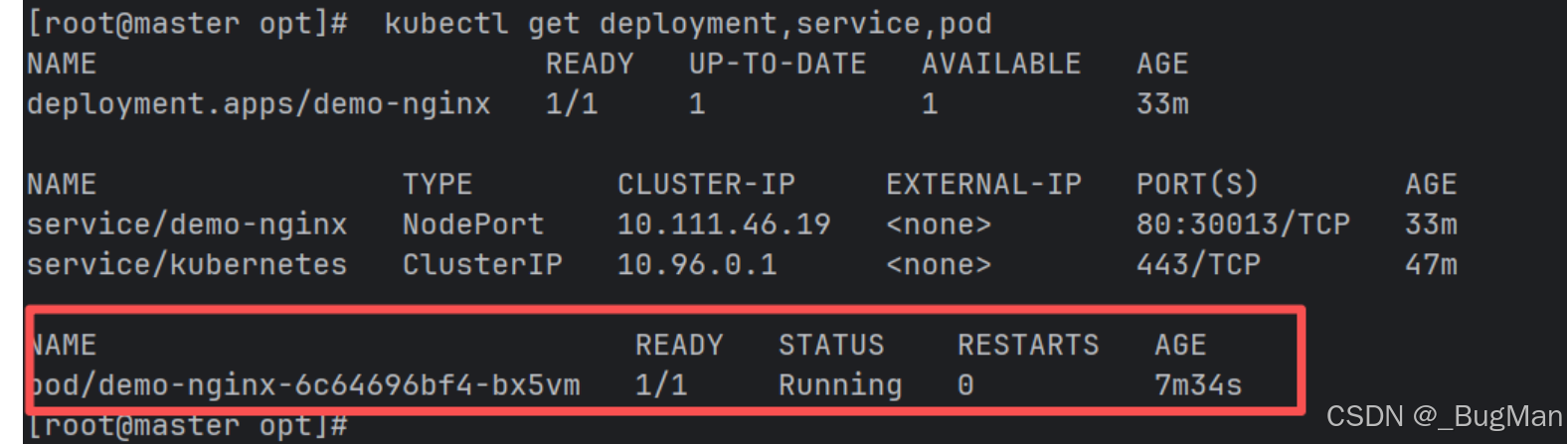
查看状态:
pod应该是Running才正确
kubectl get deployment,service,pod
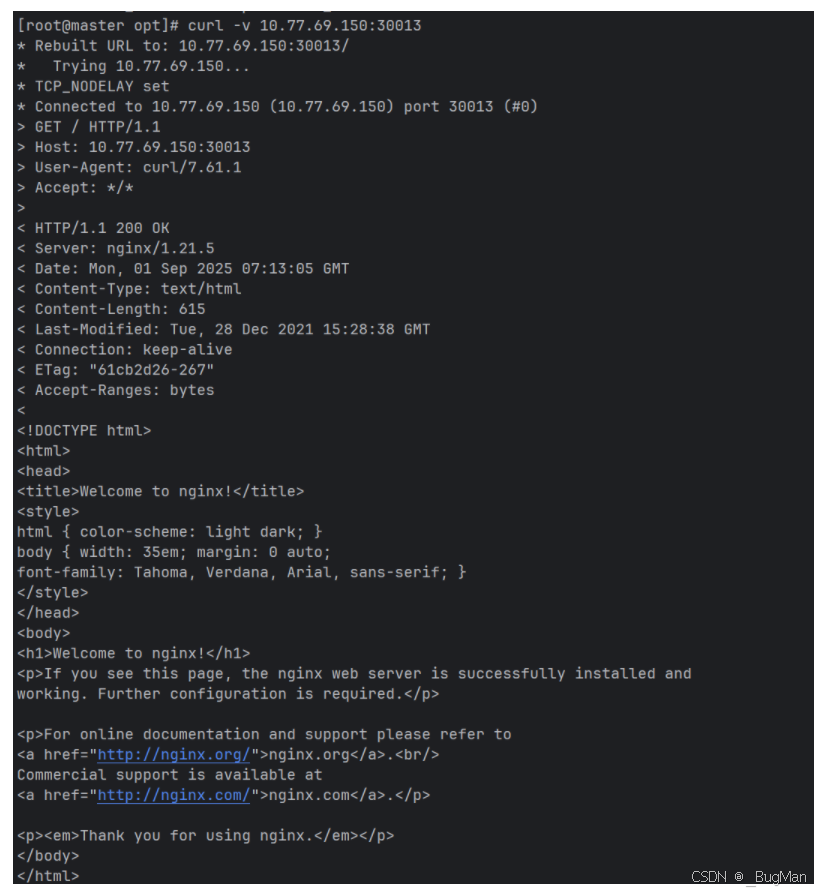
测试:
curl -v 10.77.69.150:30013
kubectl命令
| 类别 | 常用命令示例 | 说明 |
|---|---|---|
| 资源管理 | kubectl get pods | 查看Pod |
| kubectl describe pod <pod-name> | 查看Pod详细信息 | |
| kubectl delete pod <pod-name> | 删除Pod | |
| kubectl apply -f deployment.yaml | 通过YAML文件创建或更新资源(声明式) | |
| kubectl create deployment nginx --image=nginx | 命令式创建Deployment | |
| 日志与诊断 | kubectl logs <pod-name> | 查看Pod日志 |
| kubectl logs -f <pod-name> | 实时流式输出Pod的日志(类似 tail -f) | |
| kubectl exec -it <pod-name> -- /bin/sh | 进入Pod的Shell交互 | |
| 部署与弹性扩缩 | kubectl scale deployment/<name> --replicas=3 | 扩容或缩容Deployment的副本数 |
| kubectl set image deployment/nginx nginx=nginx:1.25 | 更新Deployment的镜像版本,触发滚动更新 | |
| kubectl rollout status deployment/<name> | 查看滚动更新的状态 | |
| kubectl rollout undo deployment/<name> | 回滚到上一个版本 | |
| 服务与网络 | kubectl expose deployment nginx --port=80 --type=NodePort | 将Deployment暴露为Service |
| kubectl get svc | 查看Service | |
| 集群管理 | kubectl get nodes | 查看集群节点 |
| kubectl top pods | 查看Pod的资源(CPU/内存)使用情况 | |
| kubectl cluster-info | 显示集群的基本信息 |
查看集群中的节点:
kubectl get nodes

查看集群中的服务:
kubectl get svc

《【k8s】基础概念+下载安装教程》 是转载文章,点击查看原文。
