系列文章目录
目录
系列文章目录
前言
一、前言
二、引言
2.1 LeRobotDataset
2.1.1 数据集类的设计
2.2 代码示例:批处理(流式)数据集
2.2.1 批处理(流式)数据集
2.3 代码示例:收集数据
2.3.1 记录数据集
前言
机器人学习正处于一个转折点,这得益于机器学习的快速进步以及大规模机器人数据日益普及。这种从经典的基于模型的方法向数据驱动、基于学习的范式转变,正在为自主系统释放前所未有的能力。本教程全面梳理现代机器人学习领域,从强化学习与行为克隆的基础原理出发,逐步阐述如何构建通用型语言条件模型——这类模型不仅能适应多样化任务,甚至能在不同机器人形态间无缝迁移。作为面向研究者与实践者的指南,我们致力于为读者提供概念理解与实用工具,助力机器人学习领域的发展,并提供基于lerobot框架实现的现成示例。
一、前言
机器人学本质上是一个跨学科领域,自20世纪60年代诞生以来正经历着前所未有的发展。然而,在Unimate机器人问世六十余年后,机器人仍未能完全融入人类所处的丰富、非结构化且动态的世界。数十年来,众多学科在应对自主机器人系统研发挑战方面展现出巨大潜力。本教程在现代机器学习能否主导自主机器人发展的争论中明确表态:我们坚信其必将发挥关键作用。
然而我们同样认为,过去六十年间学术界与产业界在经典机器人学领域积累的丰硕成果,其价值之高远非纯粹基于学习的方法所能取代。然而,经典机器人学与现代机器学习的融合仍处于萌芽阶段,其整合路径尚未清晰界定。因此,我们的目标在于呈现当今机器人学习领域最具相关性的方法,同时诚挚邀请各界合作拓展研究疆域!立即在此贡献力量。
本教程…
- 本书无意成为机器人学、操作系统或欠驱动系统等广泛领域的全面指南:Siciliano and Khatib(2016)以及Tedrake(a, b)对此的阐述远胜于我们。
- 本书并非统计学习或深度学习的入门指南:Shalev-Shwartz与Ben-David(2014)及Prince(2023)对这些领域的阐述远胜于我们。
- 本书无意深入探讨强化学习、扩散模型或流匹配:诸如Sutton和Barto(2018)、Nakkiran等人(2024)以及Lipman等人(2024)等不可或缺的著作对此的阐述远胜于我们。
相反,我们的目标是直观地阐释为何这些看似割裂的理念最终汇聚成激动人心的现代机器人学习领域,推动着当今前所未有的进步。秉承这一精神,我们遵循古训:“通才虽不如专才精深,却常胜于专精一技之人。”
我们衷心希望本教程能成为您踏入机器人学习领域的宝贵起点。
二、引言
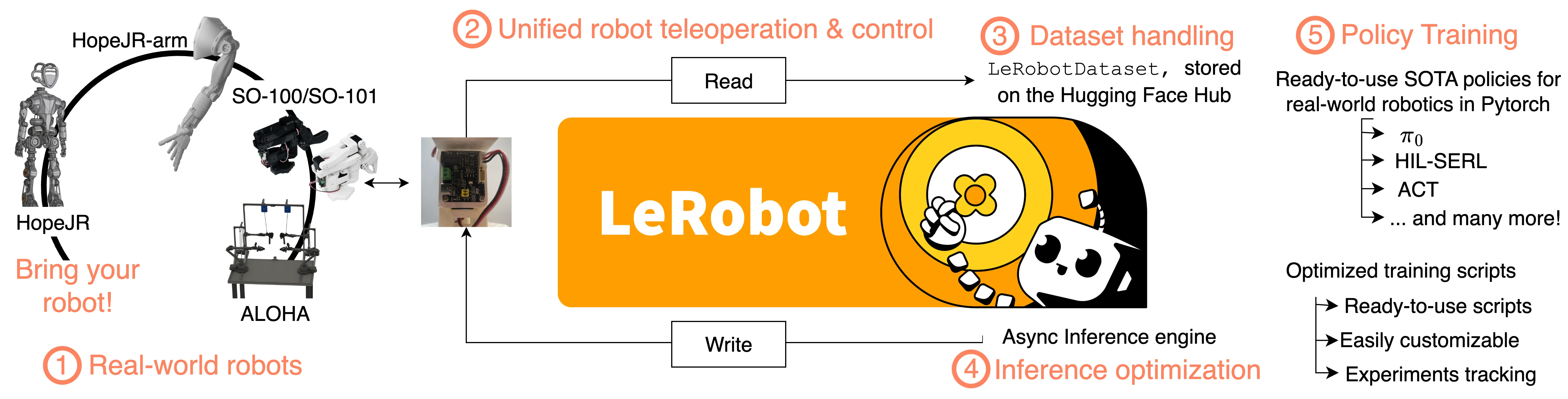
lerobot 是由 Hugging Face 开发的开源端到端机器人学库。该库在整个机器人技术栈上实现了垂直集成,支持对真实世界机器人设备的底层控制、先进的数据与推理优化,以及采用纯 PyTorch 实现的简单操作的 SOTA 机器人学习方法。
自主机器人技术旨在将人类从重复性、疲劳性或危险性的人工任务中解放出来。因此,自20世纪50年代诞生以来,机器人学领域便受到广泛研究。近年来,机器学习(ML)的进步催生了一类相对新兴的方法,用于解决机器人学难题——这类方法不再依赖人类专业知识和建模技能,而是借助海量数据与计算能力来开发自主系统。
机器人研究的前沿确实正日益脱离经典的基于模型的控制范式,拥抱机器学习领域的进展,旨在实现以下目标:(1) 构建感知到动作的整体控制管道;(2) 开发多模态数据驱动的特征提取策略;同时(3) 降低对精确世界模型的依赖;以及(4) 更好地利用日益丰富的开放机器人数据资源。尽管操作、运动和全身控制的核心问题仍需刚体动力学、接触建模及不确定性规划等知识支撑,但最新研究表明学习方法与显式建模同样有效,由此引发了机器人学习领域的热潮。鉴于构建精确的机器人-环境交互模型面临重大挑战,这种研究热潮具有充分合理性。
此外,由于在不断扩大的文本和图像数据集上进行端到端学习,历来是开发能够进行多模态(图像、文本、音频等)语义推理的基础模型的核心,因此基于学习的机器人方法的衍生显得尤为重要——尤其随着公开数据集数量的持续增长。
机器人技术本质上是一个跨学科领域,需要广泛的软硬件专业知识。基于学习的技术的整合进一步拓宽了技能范围,提高了研究和实际应用的门槛。lerobot是一个开源库,旨在与整个机器人技术栈实现端到端集成。该库重点关注易于获取的实际应用机器人
- lerobot支持众多公开可用的机器人平台,涵盖操作、移动乃至全身控制领域。同时实现
- 统一的低级机器人配置读写方案,可低成本扩展至其他机器人平台。该库引入了 LeRobotDataset,
- 这是当前机器人社区广泛采用的原生数据集格式,可高效记录和共享数据。lerobot 还支持众多机器人学习领域的尖端算法——主要基于强化学习(RL)和行为克隆(BC)技术——提供基于 Pytorch 的高效实现,并扩展至实验设计与实验追踪支持。
- Lerobot定义了专为机器人策略优化的推理栈,将动作规划与动作执行解耦,有效保障运行时更强的适应性。
本教程旨在实现双重目标:既为常见机器人学习技术的科学原理与实际应用提供实用参考,又为关注机器人学习领域的研究者与从业者提供严谨而简洁的核心概念概述。为此,我们将结合具体应用实例(附带lerobot代码示例),阐释这些技术背后的核心原理,并指导如何实际运用相关技术。教程结构如下:
- [经典]章节回顾经典机器人学基础,阐述基于动力学方法的局限性。
- [强化学习]章节深入剖析基于动力学方法的缺陷,引入强化学习作为解决机器人问题的实用方案,并分析其优势与潜在局限。
- [模仿学习]章节进一步阐述了针对单任务学习的机器人学习技术,通过基于模仿的学习方法自主复现特定专家演示。
- [通用模型学习]章节展示了近期在机器人应用通用模型开发方面的进展,通过学习大规模多任务多机器人数据集(机器人基础模型)实现突破。
本教程旨在直观阐释机器学习(ML)领域中各种看似割裂的理念为何得以融合,并如何推动当前机器人技术的演进,从而催生出我们今日所见的前所未有的进步。我们将结合lerobot工具的实际代码实现,介绍机器人学习中最常见且最新的方法,并首先阐述lerobot引入的数据集格式。
2.1 LeRobotDataset
LeRobotDataset 是 lerobot 最具影响力的功能之一,其开发基于这样一个观察:机器人数据在机器人学习中日益占据核心地位。因此,lerobot 定义了一种标准化数据集格式,旨在满足机器人学习研究的特定需求,提供跨模态的统一便捷访问通道,涵盖感觉运动读数、多摄像头数据流及遥操作状态等机器人数据。LeRobotDataset还支持存储数据采集的通用信息,包括远程操作者执行任务的文本描述、所用机器人类型,以及相关测量细节——例如图像流与机器人状态流的记录帧率。
在此背景下,LeRobotDataset 提供了一个处理多模态、时间序列数据的统一接口,并设计为能与 PyTorch 和 Hugging Face 生态系统无缝集成。该数据集支持用户轻松扩展与高度定制,现已兼容lerobot平台各类实体设备公开数据源——涵盖SO-100机械臂、ALOHA-2系统等操作平台,真实人形机器人机械臂与手部数据,以及纯模拟数据集和自动驾驶汽车数据。该数据集格式在确保训练效率的同时,具备充分的灵活性以适应机器人领域中各类数据类型,同时促进实验可重复性并提升用户操作便捷性。
2.1.1 数据集类的设计
LeRobotDataset 背后的核心设计决策在于将底层数据存储与用户接口分离。这种设计既能实现高效存储,又能以直观、即用型格式呈现数据。
数据集始终由三个主要组件构成:
- 表格数据(Tabular Data):低维高频数据(如关节状态和动作)存储于高效内存映射文件中,通常由Hugging Face更成熟的数据集库进行卸载处理,在消耗有限内存的同时提供高速访问。
- 视觉数据(Visual Data):为处理海量摄像头数据,坐标系序列经拼接编码为MP4文件。同一事件的坐标系数据始终归入同一视频,多个视频按摄像头进行分组。为减轻文件系统压力,当视频数量超过阈值时,同一视角的坐标系组会被拆分为多个子目录。
- 元数据(Metadata):由JSON文件组成的集合,通过元数据描述数据集结构,作为数据表格式与可视化维度的关联对应层。元数据包含不同特征模式、帧率、归一化统计信息及剧集边界等要素。
为实现可扩展性,并支持可能包含数百万条轨迹(导致产生数亿甚至数十亿个独立摄像机坐标系)的数据集,我们将不同事件的数据合并到同一高级结构中。具体而言,这意味着任何给定的表格集合和视频通常不仅包含单个事件的信息,而是多个事件可用信息的拼接。此设计有效缓解了本地及Hugging Face等远程存储服务商的文件系统压力,但代价是更依赖关系型元数据来重建关键信息——例如在特定文件中某个片段的起止位置。以LeRobotDataset为例,其结构示意如下:
- meta/info.json:此元数据文件是核心元数据文件,包含完整的数据集架构,定义了所有特征(如观察状态、动作)、其形状及数据类型。同时存储关键信息,包括数据集的帧率(fps)、采集时的lerobot版本,以及用于定位数据和视频文件的路径模板。
- meta/stats.json:该文件存储整个数据集中每个特征的聚合统计量(均值、标准差、最小值、最大值),用于大多数策略模型的数据归一化,并可通过 dataset.meta.stats 外部访问。
- meta/tasks.jsonl:该文件包含自然语言任务描述与整数任务索引的映射关系,适用于任务条件化策略训练。
- meta/episodes/*:该目录包含每个独立片段的元数据,如片段时长、对应任务及数据在数据集文件中的存储位置指针。为提升可扩展性,此类信息分散存储于多个文件而非单一大型 JSON 文件中。
- data/*:包含核心逐帧表格数据,采用 Parquet 格式实现快速内存映射访问。为提升性能并处理大规模数据集,多个片段的数据会被拼接至大型文件中。这些文件通过分块子目录组织,以保持目录规模可控。单个文件通常包含多个单集的数据。
- videos/*:存储所有视觉观测流的MP4视频文件。与data/目录类似,多个集的视频素材被拼接为单个MP4文件。此策略显著减少了数据集中的文件数量,更符合现代文件系统的效率要求。
2.2 代码示例:批处理(流式)数据集
本节概述了如何使用 LeRobotDataset 类访问托管在 Hugging Face 上的数据集。Hugging Face Hub 上的每个数据集都包含上述三大支柱(表格化、可视化及关系型元数据),且可通过单条指令进行访问。
在实际应用中,大多数强化学习(RL)和行为克隆(BC)算法倾向于在观测与动作的栈结构上运行。为简明起见,我们将关节空间与摄像机帧统称为帧。例如,RL算法可能利用历史帧序列 来缓解局部可观测性问题,而BC算法在实际训练中通常采用多动作块回归
而非单一控制变量。为适应机器人学习训练的这些特性,LeRobotDataset提供了原生窗口操作功能:用户可通过delta_timestemps参数定义任意帧前后指定秒数的窗口范围。缺失帧将自动填充,同时返回填充掩码用于过滤填充帧。值得注意的是,所有操作均在 LeRobotDataset 内部完成,对训练机器学习模型时常用的高级封装器(如 torch.utils.data.DataLoader)完全透明。
值得一提的是,通过将LeRobotDataset与Pytorch DataLoader结合使用,可自动将数据集中的单个样本字典整合为批量张量字典,用于后续训练或推理。LeRobotDataset还原生支持数据集流式处理模式。用户只需修改一行代码,即可流式处理托管在Hugging Face Hub上的海量数据集。流式数据集支持高性能批处理(约80-100次/秒,具体取决于网络连接)和高水平帧随机化,这些是实用BC算法的关键特性——否则该算法可能运行缓慢或处理高度非独立同分布的数据。此功能旨在提升可访问性,使用户无需大量内存和存储即可处理大型数据集。
2.2.1 批处理(流式)数据集
https://github.com/fracapuano/robot-learning-tutorial/blob/main/snippets/ch1/01\_datasets.py
1import torch 2from lerobot.datasets.lerobot_dataset import LeRobotDataset 3from lerobot.datasets.streaming_dataset import StreamingLeRobotDataset 4 5delta_timestamps = { 6 "observation.images.wrist_camera": [-0.2, -0.1, 0.0] # 0.2, and 0.1 seconds *before* each frame 7} 8 9# Optionally, use StreamingLeRobotDataset to avoid downloading the dataset 10dataset = LeRobotDataset( 11 "lerobot/svla_so101_pickplace", 12 delta_timestamps=delta_timestamps 13) 14 15# Streams frames from the Hugging Face Hub without loading into memory 16streaming_dataset = StreamingLeRobotDataset( 17 "lerobot/svla_so101_pickplace", 18 delta_timestamps=delta_timestamps 19) 20 21# Get the 100th frame in the dataset by 22sample = dataset[100] 23print(sample) 24# { 25# 'observation.state': tensor([...]), 26# 'action': tensor([...]), 27# 'observation.images.wrist_camera': tensor([3, C, H, W]), for delta timesteps 28# ... 29# } 30 31batch_size=16 32# wrap the dataset in a DataLoader to use process it batches for training purposes 33data_loader = torch.utils.data.DataLoader( 34 dataset, 35 batch_size=batch_size 36) 37 38# Iterate over the DataLoader in a training loop 39num_epochs = 1 40device = "cuda" if torch.cuda.is_available() else "cpu" 41 42for epoch in range(num_epochs): 43 for batch in data_loader: 44 # Move data to the appropriate device (e.g., GPU) 45 observations = batch["observation.state"].to(device) 46 actions = batch["action"].to(device) 47 images = batch["observation.images.wrist_camera"].to(device) 48 49 # Next, you can do amazing_model.forward(batch) 50 ...
2.3 代码示例:收集数据
2.3.1 记录数据集
https://github.com/fracapuano/robot-learning-tutorial/blob/main/snippets/ch1/02\_record\_data.py
1import torch 2from lerobot.datasets.lerobot_dataset import LeRobotDataset 3from lerobot.datasets.streaming_dataset import StreamingLeRobotDataset 4 5delta_timestamps = { 6 "observation.images.wrist_camera": [-0.2, -0.1, 0.0] # 0.2, and 0.1 seconds *before* each frame 7} 8 9# Optionally, use StreamingLeRobotDataset to avoid downloading the dataset 10dataset = LeRobotDataset( 11 "lerobot/svla_so101_pickplace", 12 delta_timestamps=delta_timestamps 13) 14 15# Streams frames from the Hugging Face Hub without loading into memory 16streaming_dataset = StreamingLeRobotDataset( 17 "lerobot/svla_so101_pickplace", 18 delta_timestamps=delta_timestamps 19) 20 21# Get the 100th frame in the dataset by 22sample = dataset[100] 23print(sample) 24# { 25# 'observation.state': tensor([...]), 26# 'action': tensor([...]), 27# 'observation.images.wrist_camera': tensor([3, C, H, W]), for delta timesteps 28# ... 29# } 30 31batch_size=16 32# wrap the dataset in a DataLoader to use process it batches for training purposes 33data_loader = torch.utils.data.DataLoader( 34 dataset, 35 batch_size=batch_size 36) 37 38# Iterate over the DataLoader in a training loop 39num_epochs = 1 40device = "cuda" if torch.cuda.is_available() else "cpu" 41 42for epoch in range(num_epochs): 43 for batch in data_loader: 44 # Move data to the appropriate device (e.g., GPU) 45 observations = batch["observation.state"].to(device) 46 actions = batch["action"].to(device) 47 images = batch["observation.images.wrist_camera"].to(device) 48 49 # Next, you can do amazing_model.forward(batch) 50 ...

