谷歌AI研究团队与DeepMind刚刚发布了 VaultGemma 1B —— 这是目前规模最大的、完全在差分隐私(Differential Privacy, DP)保障下从头训练的开源大语言模型。它不是在已有模型基础上做微调,而是从预训练阶段就嵌入了隐私保护机制。这个尝试,让我觉得有点像在一片风沙中种树——既要长得高,又不能伤根。
我们都知道,现在的LLM(大语言模型)训练数据动辄万亿token,来自整个互联网。但问题也随之而来:模型会“记住”训练数据中的敏感信息,甚至能被攻击者通过提示工程“撬”出用户姓名、电话、病历等私密内容。这在开源模型中尤其令人担忧——你把模型放出去了,别人却可能从中挖出不该知道的东西。
而差分隐私提供了一种数学上的保证:无论你如何查询模型,都无法判断某个具体样本是否参与过训练。换句话说,它不让任何一个数据点“太突出”。VaultGemma 的突破在于,它没有像很多工作那样只在微调阶段加DP,而是从最底层的预训练就开始做,这意味着它的隐私保护是“基因级”的。
模型架构上,VaultGemma 1B 基于Gemma系列的设计,参数量为10亿,共26层,采用Decoder-only结构。激活函数用的是GeGLU,前馈维度为13,824;注意力机制是Multi-Query Attention(MQA),上下文长度限制在1024个token——这个缩短是有意为之,因为DP训练对计算资源极其敏感,缩短序列能显著提升批处理效率,降低噪声引入的成本。
训练数据方面,它沿用了和Gemma 2相同的约13万亿token语料,主要来自英文网页、代码和科研文献。不过,在训练前进行了多轮清洗:过滤掉危险内容、减少个人信息暴露、确保评估集不污染——这些步骤看似常规,但在DP框架下,每一步都得小心拿捏,否则会影响最终的隐私预算。
真正的技术难点在训练过程本身。他们使用的是 DP-SGD(差分隐私随机梯度下降),核心是梯度裁剪 + 高斯噪声注入。为了在TPUv6e集群上高效运行,团队做了不少工程优化:比如向量化逐样本裁剪、梯度累积模拟大batch、以及在数据加载器中集成Truncated Poisson Subsampling,这些细节在论文里写得清楚,但在工程落地时,每一个都能卡住人。
最终,模型达到了一个形式化的隐私保证:ε ≤ 2.0,δ ≤ 1.1e−10(按序列级别)。这个数字意味着什么?简单说,就是即使攻击者掌握全部模型输出,他能“猜到”某条特定数据是否被训练过的概率,几乎可以忽略不计。
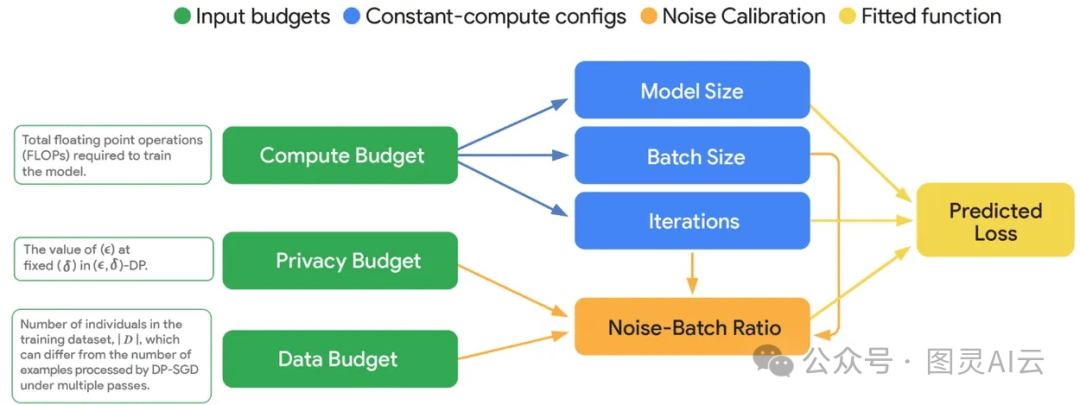
在训练资源配置上,他们在2048片TPUv6e上跑,总批大小约51.8万token,训练了10万步,噪声乘数设为0.614。有意思的是,他们没有靠试错,而是建立了一套DP专用的缩放定律(DP-specific scaling laws),通过二次拟合学习率、参数化损失外推、半参数拟合等方式,提前预测模型收敛效果。结果很惊人:实际训练损失与预测值偏差不到1%——说明这套方法不仅理论上成立,工程上也可靠。
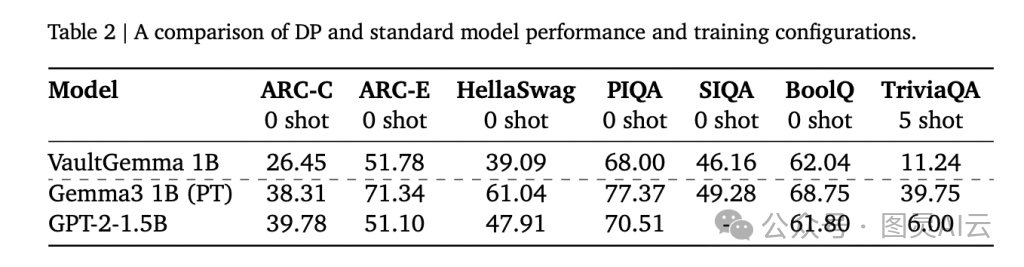
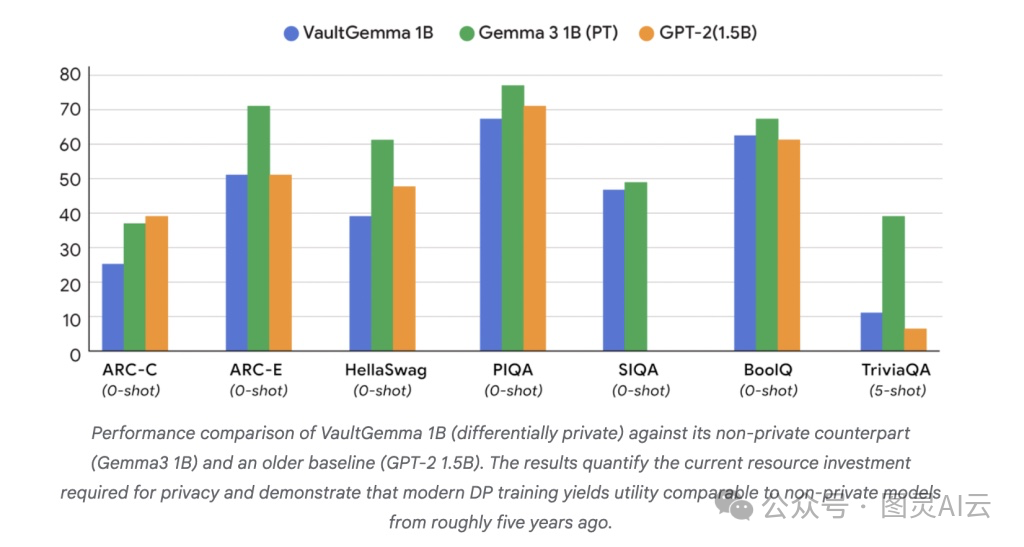
至于性能,我们得坦诚一点:相比非私有模型,VaultGemma确实有差距。
- • ARC-C:26.45 vs. Gemma-3 1B 的 38.31
- • PIQA:68.0 vs. GPT-2 1.5B 的 70.51
- • TriviaQA(5-shot):11.24 vs. Gemma-3 1B 的 39.75
看起来,它的能力大概相当于五年前的非私有模型水平。但这不是失败,而是一次“有代价的前进”。关键验证是:在对抗性记忆提取测试中,VaultGemma 没有泄露任何训练数据,而同期的非私有Gemma模型则被成功复现了大量原文片段。
这让我想起一句话:技术的进步,有时不是看它有多快,而是看它有多稳。当行业都在追求更大的参数、更快的速度时,有人愿意花力气去解决“安全”这个基础问题,本身就是一种难得的清醒。
VaultGemma 1B 不是终点,但它是一个信号:开源、强大、且真正尊重隐私的AI,是可能实现的。他们不仅开源了模型,还公开了训练代码、方法论和工具链(基于JAX Privacy),这对整个社区来说,价值远超一个模型本身。
如果你关心AI伦理、数据合规,或者只是单纯想看看“有没有可能既聪明又不偷窥”,那这个项目值得你花时间读一读论文,跑一跑Hugging Face上的模型。
详见
- 1. 论文:https://services.google.com/fh/files/blogs/vaultgemma\_tech\_report.pdf
- 2. 模型下载:https://huggingface.co/google/vaultgemma-1b
- 3. 技术细节:https://research.google/blog/vaultgemma-the-worlds-most-capable-differentially-private-llm/
《谷歌发布首个隐私安全模型VaultGemma》 是转载文章,点击查看原文。
