目录
1、线程组
1.1 多线程组关系
1.2、线程组的设置参数含义
编辑1.3 如何查看线程数是否全部启动成功?
2、定时器
2.1 常数吞吐量定时器
3、监听器
3.1 查看结果树
3.1.1 多个线程并发时,查看结果树频繁刷屏,如果有失败,无法停止后看到想看的失败信息,如何解决?
编辑4.1.2 取样器结果里展示的字段都什么含义
3.2 聚合报告
3.2.1:聚合报告如何查看http请求的平均响应时间:
4、后置处理器
4.1 正则表达式提取器
1、线程组
1.1 多线程组关系
同一个测试计划下的多个线程组并行关系,但可以通过设置“测试活动”的延时启动来实现:间隔启动后续线程组的效果
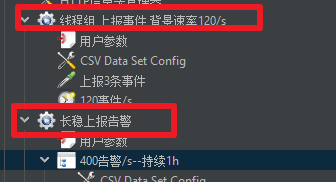
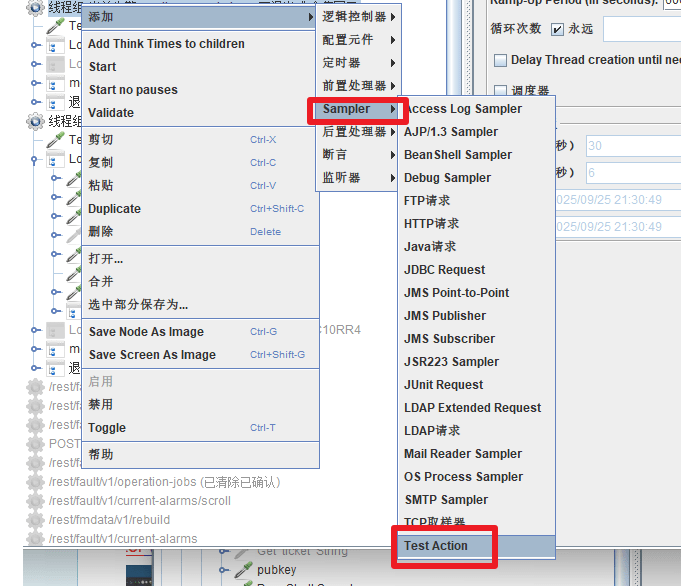
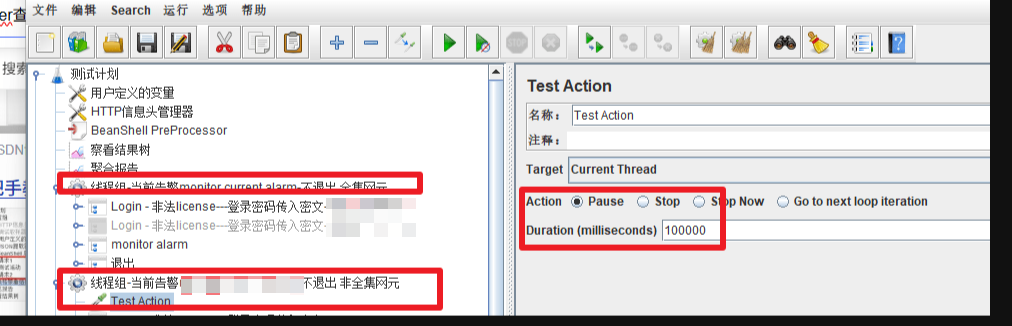
如:希望线程组1启动10S后再启动线程组2,可通过添加:取样器->Test Action(测试活动,Flow Control Action)的pause和延时时间组合来实现
Pause 暂停,配合 Duration 一起使用
Duration(milliseconds) 延迟时间,单位是毫秒
1.2、线程组的设置参数含义
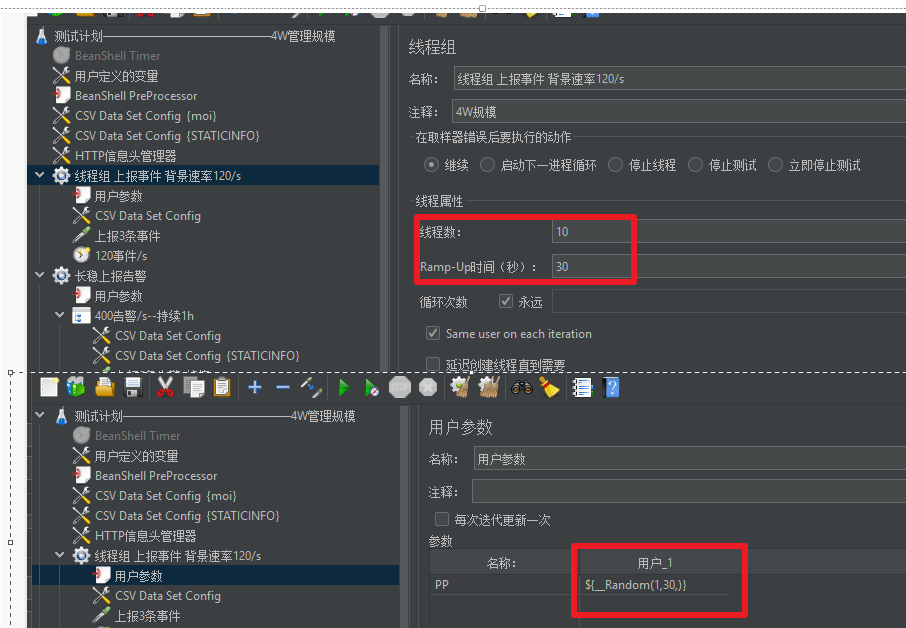
线程数:预计启动的线程数量,即并发数
Ramp-Up 时间 (秒):线程准备时长。如果线程数为 10,准备时长为 30,那么平均30/10= 3秒钟启动 1 个线程
如下述截图代表:每次从1到30用户中取一个用户进行线程组里的操作,共启动用户数=线程数的用户进行操作
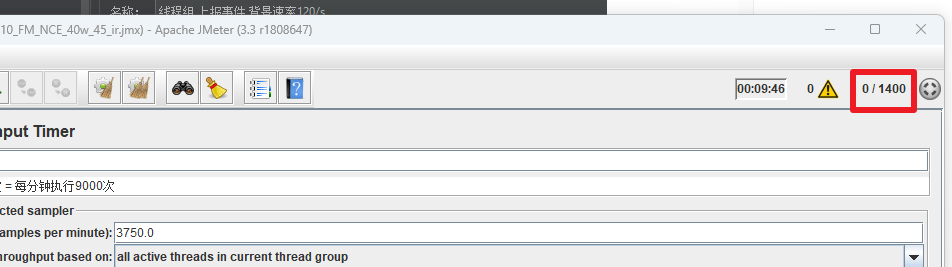
 1.3 如何查看线程数是否全部启动成功?
1.3 如何查看线程数是否全部启动成功?
启动后右上角展示线程启动情况
2、定时器
2.1 常数吞吐量定时器
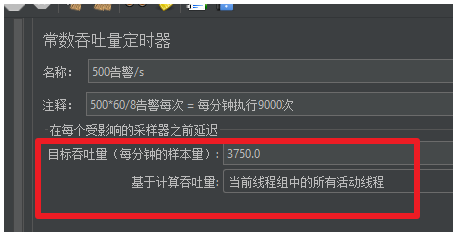
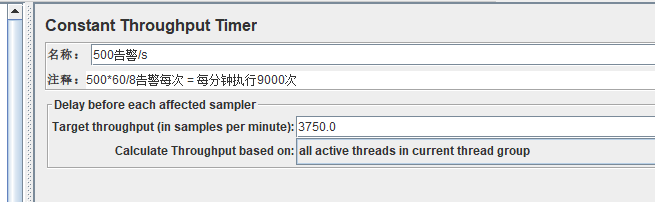
 举例:计划每秒上报500条告警,且预置的上报告警http请求里包含8条告警,故吞吐量=(500条/S*60S)/8=3750
举例:计划每秒上报500条告警,且预置的上报告警http请求里包含8条告警,故吞吐量=(500条/S*60S)/8=3750
吞吐量的值最好不要超过1W ,否则容易导致jmeter压力撑不住,而上压力失败
3、监听器
3.1 查看结果树
3.1.1 多个线程并发时,查看结果树频繁刷屏,如果有失败,无法停止后看到想看的失败信息,如何解决?
1、进入jmeter?安装目录,bin文件夹下。
2、打开jmeter.properties?文件,搜索:view.results.tree.max_results
3、把500改为0。记得去掉 前面的# 保存退出。

3.1.2 取样器结果里展示的字段都什么含义
 延迟(Latency)是指从发送请求到收到服务器的第一个响应的时间。在这个测试结果中,延迟时间是485毫秒。延迟高的高低判断取决于性能需求。
延迟(Latency)是指从发送请求到收到服务器的第一个响应的时间。在这个测试结果中,延迟时间是485毫秒。延迟高的高低判断取决于性能需求。
一般来说,对于大多数Web应用,如果延迟在100-200毫秒之间,用户通常会感觉到反应迅速。如果延迟在200-400毫秒之间,用户可能会注意到一些延迟,但应用通常仍然可以接受。如果延迟超过400-500毫秒,用户可能会开始感觉到明显的延迟,并可能对应用的性能感到不满。
其中Latency延迟时间 <= Load time=请求的响应时间
3.2 聚合报告
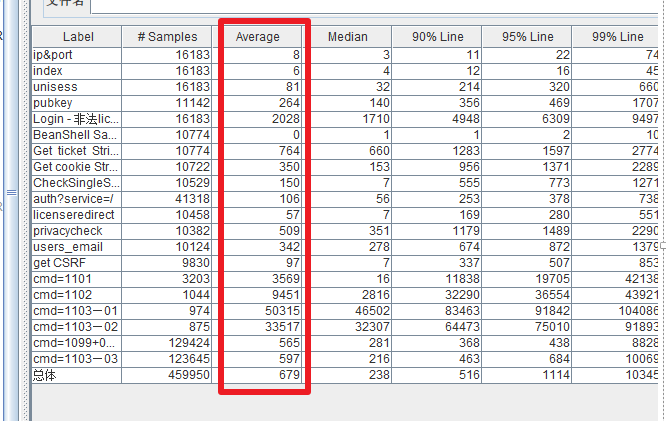
3.2.1:聚合报告如何查看http请求的平均响应时间:
Average:平均响应时间——默认情况下是单个?Request?的平均响应时间,当使用了?Transaction Controller?时,也可以以Transaction?为单位显示平均响应时间
4、后置处理器
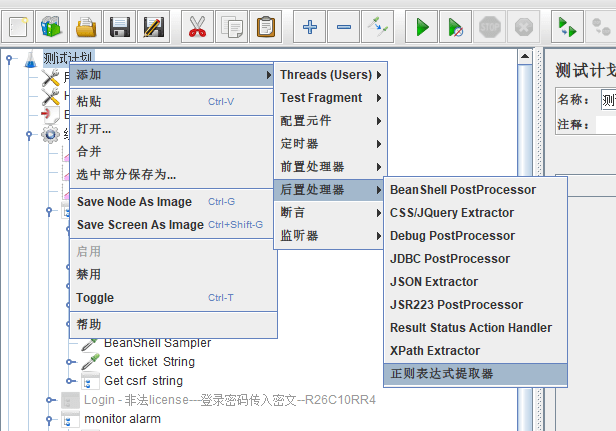
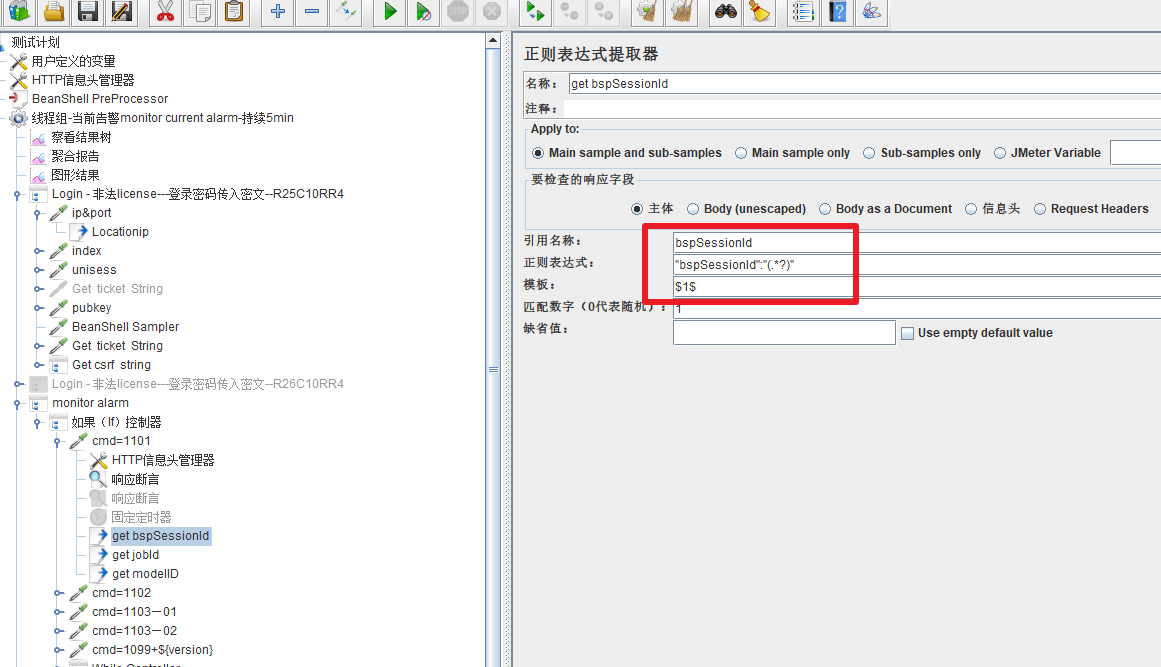
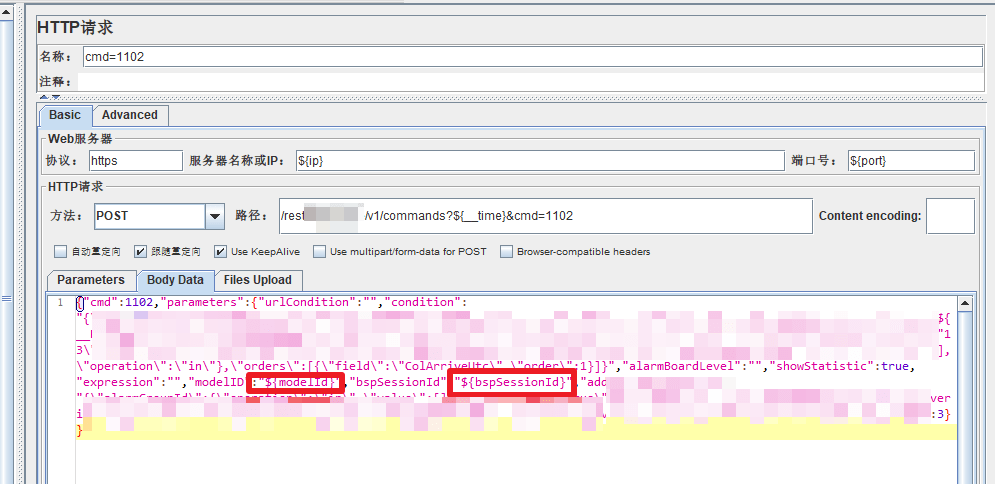
4.1 正则表达式提取器
一般上个请求的响应体是下个需求的输入,会使用到“正则表达式提取器”组件来获取响应体的某个参数:
《Jmeter 线程组、定时器、监听器、后置处理器常用配置说明》 是转载文章,点击查看原文。

