文章目录
- 一、索引
-
- 1.1 索引分类
- 1.2 主键选择🌟
- 二、约束
-
- 2.1 外键约束
- 2.2 约束与索引的区别
- 三、索引实现原理
-
- 3.1 索引存储层级结构
- 3.2 B+ 树
-
- B+ 树层高问题🌟
- 关于自增 ID
- B+ 树层高问题🌟
- 四、索引类型
-
- 4.1 聚集索引
- 4.2 辅助索引
一、索引
在数据库中,索引是提高查询性能的关键机制。它相当于书籍的目录,通过索引可以快速定位到数据在磁盘中的位置,从而减少 I/O 操作。对于 InnoDB 而言,索引不仅影响查询性能,还决定了数据在物理层的存储结构。
1.1 索引分类
① 主键索引(Primary Key Index)
非空唯一索引,一个表只有一个主键索引;且在 InnoDB 中是表的物理存储顺序。一个表只能有一个主键索引,它的 B+ 树叶子节点存储了整行数据。
1PRIMARY KEY(key1, key2) 2
② 唯一索引(Unique Index):不可以出现相同的值,可以有 NULL 值
1CREATE UNIQUE INDEX idx_user_email ON user(email); 2
③ 普通索引(Normal Index)
普通索引仅用于加速查询,没有唯一性或非空约束。
1CREATE INDEX idx_name ON user(name); 2
④ 组合索引(Composite Index)
组合索引是对多个列建立的索引,用于多个字段组合查询时提升效率。MySQL 遵循“最左前缀匹配原则”,即只会利用从左到右连续的字段部分。
1CREATE INDEX idx_user_name_age ON user(name, age); 2
⑤ 全文索引(FullText Index)
全文索引用于在长文本中进行关键词搜索,而不是简单的字符串匹配。它通常通过 MATCH ... AGAINST 来使用。
- 对短字符串:使用
LIKE '%关键字%' - 对长文本:使用
MATCH(text_column) AGAINST('keyword')
1.2 主键选择🌟
InnoDB 中表是索引组织表,主键索引的叶子节点直接保存整行记录,因此每张表必须有且仅有一个主键。
主键的选择遵循以下规则:
- 如果显示设置
PRIMARY KEY,则该设置的 key 为该表的主键 - 如果没有显示设置,则选择第一个非空唯一索引作为主键。
- 如果没有非空唯一索引,InnoDB 会自动生成一个隐藏的 6 字节
_rowid作为主键。
设计主键时建议使用递增的整型自增主键,不仅能避免页分裂,还能提高插入性能。
二、约束
约束是保证数据完整性和一致性的规则。
为了实现数据的完整性,对于 InnoDB,提供了以下几种约束:
primary key、unique key、foreign key、default、not null
2.1 外键约束
外键用来关联两个表,来保证参照完整性:
- MyISAM 存储引擎本身并不支持外键,只起到注释作用
- InnoDB 完整支持外键,并具备事务性
1-- 父表(被引用表) 2create table parent ( 3 id int not null, 4 primary key(id) 5) engine=innodb; 6 7-- 子表(引用表):parent_id关联父表id 8create table child ( 9 id int, 10 parent_id int, 11 foreign key(parent_id) references parent(id) 12 ON DELETE CASCADE -- 父表删除时,子表同步删除 13 ON UPDATE CASCADE -- 父表更新时,子表同步更新 14) engine=innodb; 15 16INSERT INTO parent VALUES (1); 17INSERT INTO parent VALUES (2); 18INSERT INTO child VALUES (10, 1); 19INSERT INTO child VALUES (20, 2); 20DELETE FROM parent WHERE id = 1; 21
外键行为选项:
CASCADE:子表做同样的行为SET NULL:更新子表相应字段为NULLNO ACTION:父类做相应行为报错RESTRICT:同NO ACTION
2.2 约束与索引的区别
约束是逻辑层面的规则,用于保证数据的正确性;索引是物理层面的结构,用于加速数据访问。两者虽有关联,但本质不同。
创建主键索引或者唯一索引的时候同时创建了相应的约束;但是约束是逻辑上的概念;索引是一个数据结构既包含逻辑的概念也包含物理的存储方式。
| 维度 | 约束(如主键约束) | 索引(如主键索引) |
|---|---|---|
| 本质 | 逻辑概念(仅保证数据完整性) | 数据结构(含逻辑规则 + 物理存储) |
| 关联 | 创建主键 / 唯一索引时自动生成对应约束 | 索引是约束的物理实现载体 |
三、索引实现原理
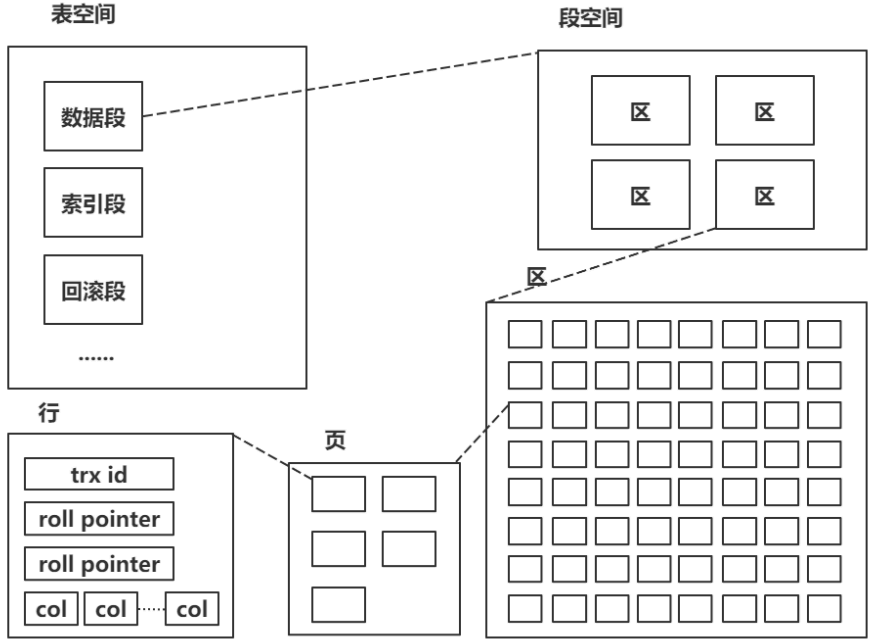
在 InnoDB 存储引擎中,每一个索引都对应一棵 B+ 树。而每棵 B+ 树的叶子节点或非叶子节点都存储在 页(Page) 中。
3.1 索引存储层级结构
InnoDB 的存储由段、区、页组成:
- 段:按功能分数据段(存表数据)、索引段(存索引)、回滚段(存事务回滚信息)
- 区:大小为 1 MB(一个区由 64 个连续页构成)。为了保证连续性,InnoDB 一次通常会申请 4~5 个区。
- 页:
- InnoDB 磁盘管理最小单位,默认 16KB,可通过innodb_page_size修改;
- 逻辑页(与磁盘物理页 4KB/8KB 区分);
- B + 树的一个节点大小 = 页大小(默认 16KB,两个物理页)。
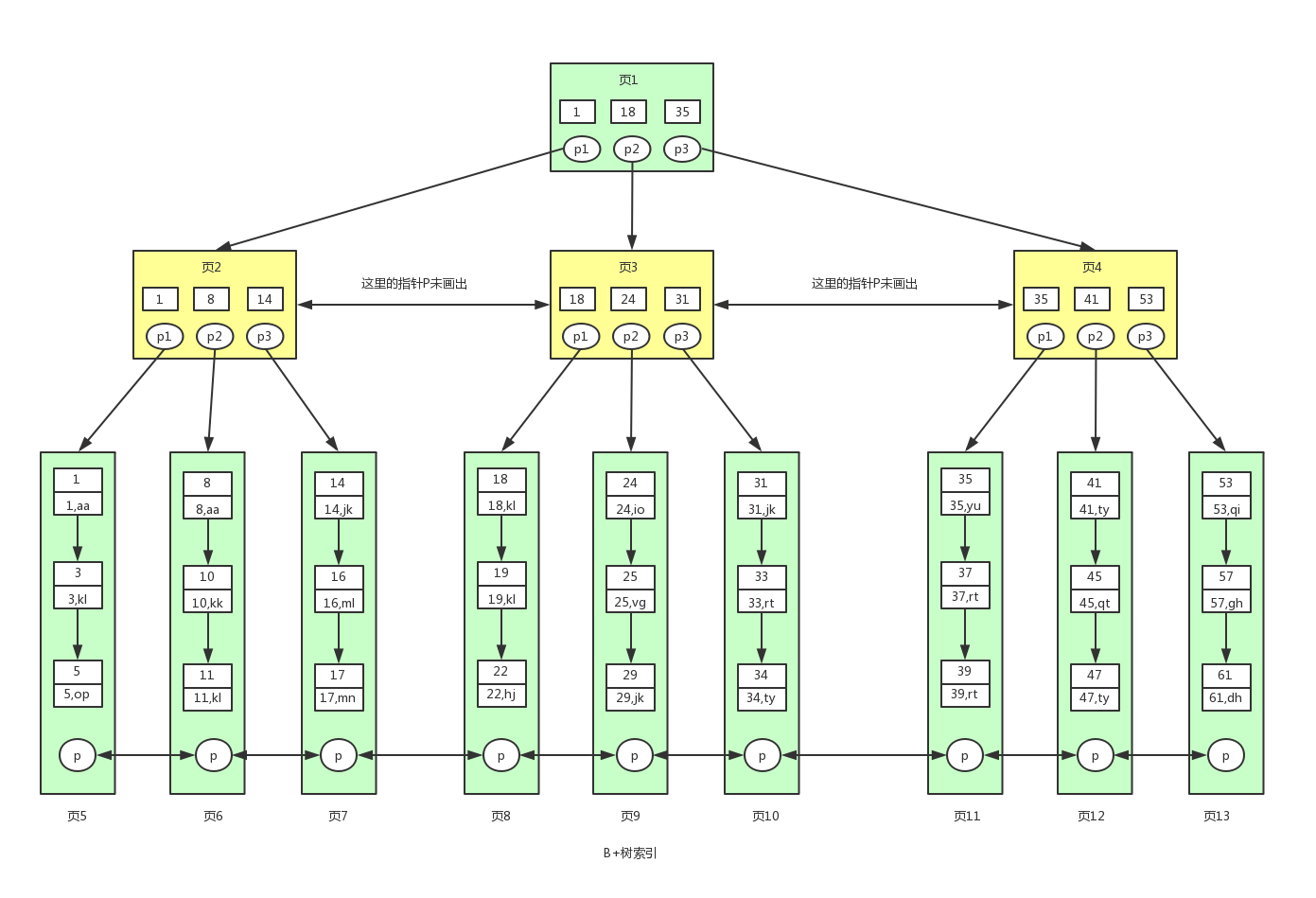
3.2 B+ 树
全称:多路平衡搜索树,减少磁盘访问次数
用来组织磁盘数据,以页为单位。
特征:
- 非叶子节点只存储索引信息
- 叶子节点存储完整数据
- 叶子节点之间互相连接,方便范围查询
- 节点的大小为 16 KB,映射的是连续的磁盘页
B+ 树层高问题🌟
B+ 树的一个节点对应一个数据页;B+ 树的层越高,要读取到内存的数据页越多,IO 次数越多。
假设:
- key 为 10 byte 且指针大小 6 byte
- 假设一行记录的大小为 1KB
- InnoDB 一个节点 16KB
计算:
| 层高 | 非叶子节点数量 | 叶子节点数量 | 最大记录数 |
|---|---|---|---|
| 2 | 1(根节点) | 1024(16KB/16byte) | 1024 × 16 = 16384 |
| 3 | 1 + 1024 | 1024×1024 | 1024×1024×16 = 16777216 |
| 4 | 1 + 1024 + 1024² | 1024³ | 1024³×16 = 17179869184 |
三层树即可支持上千万数据量,因此 B+ 树能高效应对大规模数据存储。
总结
- 为什么采用“多路”的树结构:一个节点多条链路,相较于平衡二叉搜索树是更矮胖的结构,树的高度较低,能减少磁盘 IO 次数来索引数据。
- 为什么非叶子节点只存储索引信息:B+ 树节点映射固定大小的磁盘数据,可包含更多索引信息,能快速锁定数据所在叶子节点位置。
- 为什么叶子节点依次相连:便于范围查询,避免中序遍历回溯查找下一个节点。
总之:索引信息和数据信息的分层管理,便于高效组织磁盘数据、快速实现单点和范围查询。
B+树通过“非叶子节点存索引、叶子节点存数据且依次相连、节点为16KB并映射连续磁盘页”的特征,结合多路结构降低树高以减少磁盘IO、非叶子节点只存索引以快速定位数据、叶子节点相连便于范围查询的设计,实现了索引与数据的分层管理,从而高效组织磁盘数据,快速支持单点查询与范围查询。
关于自增 ID
在 InnoDB 中,主键常用自增 ID(AUTO_INCREMENT)。
型通常为 BIGINT,范围是 ( − 2 63 , 2 63 − 1 ) (-2^{63}, 2^{63}-1)(−263,263−1)。即使每秒插入 1 亿条记录,也需要约 5849 年 才会耗尽。因此在绝大多数业务场景中完全够用。
四、索引类型
在 InnoDB 中,索引分为两种:聚集索引(Clustered Index) 和 辅助索引(Secondary Index)。
4.1 聚集索引
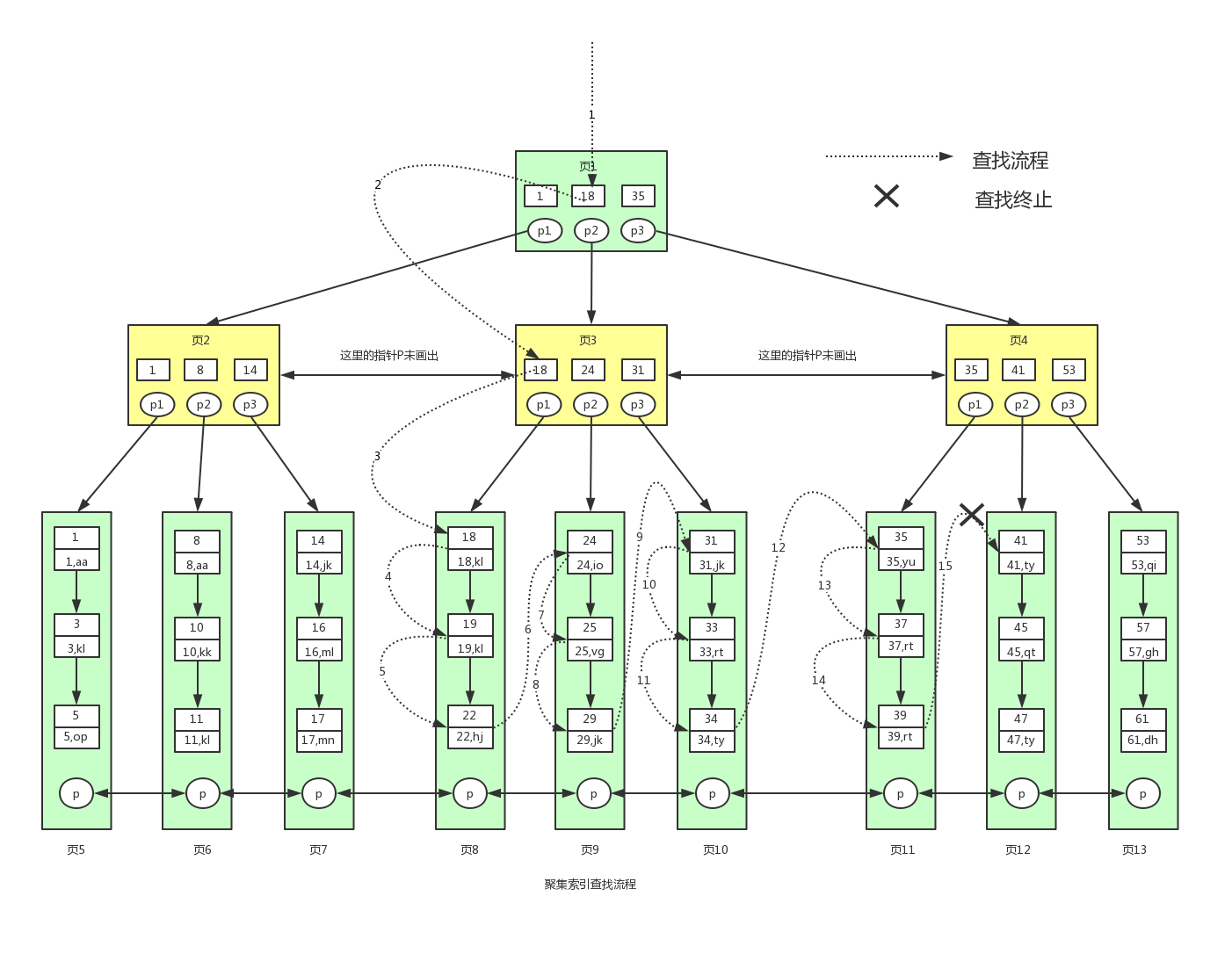
聚集索引是按主键构造的 B + 树,叶子节点直接存表数据页(整行数据),也就是说,索引即数据,查到索引项就相当于拿到了完整记录。
- 每张表只有一个聚集索引;
- 数据物理顺序与主键逻辑顺序一致;
- 范围查询效率极高。
1SELECT * FROM user WHERE id >= 18 AND id < 40; 2
查找流程:
1. 根节点定位 id=18~40 的索引项;
2. 指针指向叶子节点(数据页,如 “页 10、页 12”);
3. 直接读取叶子节点数据(无需回表)。
4.2 辅助索引
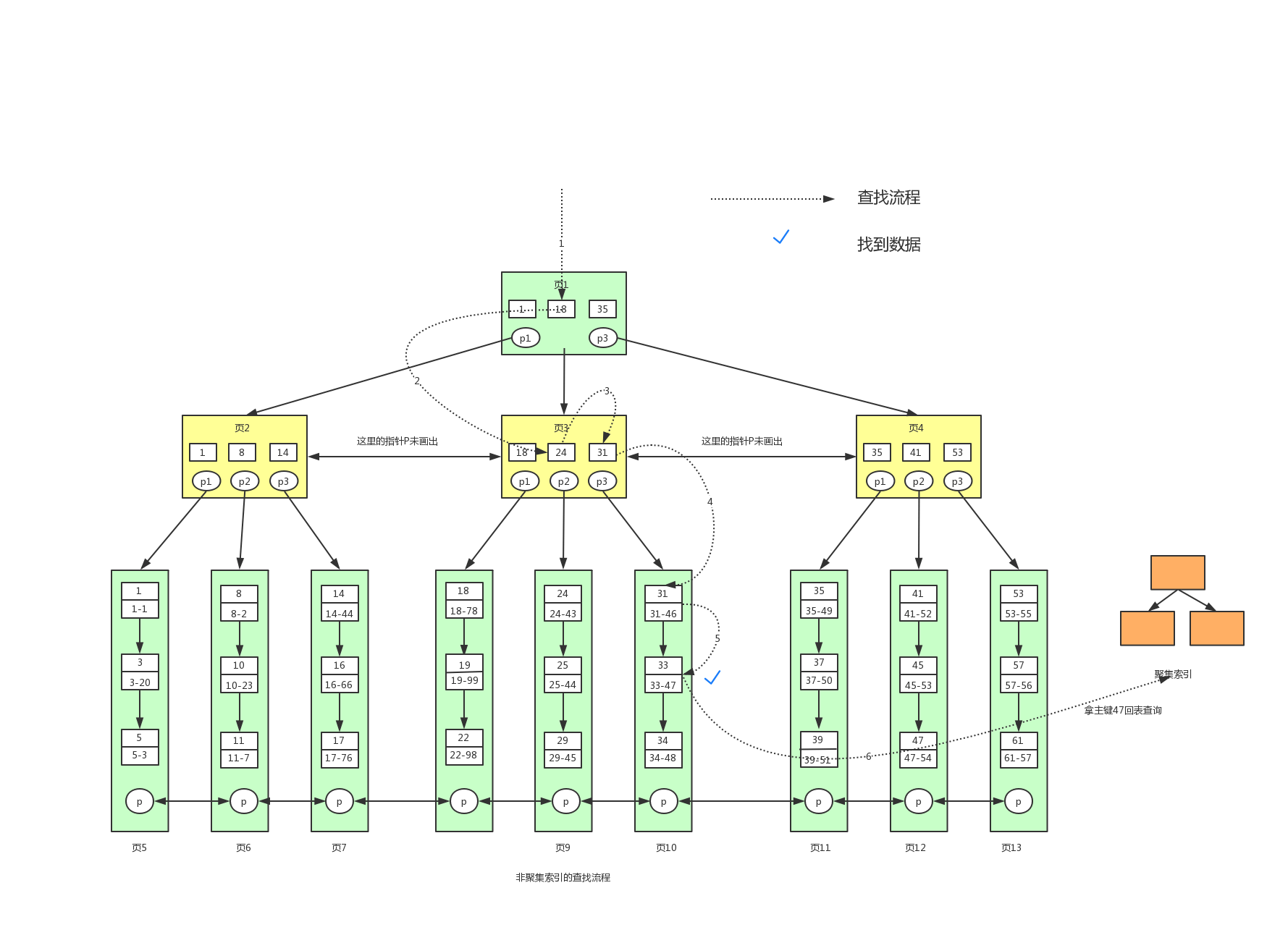
辅助索引的叶子节点不存放完整记录,只保存:
- 索引列值;
- 主键值(主键 id,称为“书签”或 Bookmark)。
查询时,需要先通过辅助索引定位主键,再通过主键去聚集索引中取出完整行数据,过程称为**回表。
1select * from user where lockyNum = 33; 2
表含id(主键)、name、lockyNum(辅助索引),索引定义KEY(lockyNum);
查找流程:
1. 遍历lockyNum辅助 B + 树,找到 lockyNum=33 的叶子节点;
2. 从 “书签” 获取主键 id;
3. 遍历聚集索引,通过 id 找到完整数据(需回表)。
辅助索引查询效率略低于主键索引,在只查询索引字段时可避免回表,尽量使用覆盖索引(即查询字段都在索引中),以减少磁盘访问。
《MySQL 索引原理》 是转载文章,点击查看原文。
