1、FFmpeg 主要数据结构分层设计
1.1 IO抽象层
协议层与 I/O 抽象层 (Protocol & I/O Abstraction),这一层负责从最广泛的数据源读取或写入数据。
- 核心数据结构:AVIOContext
- 功能: 抽象了底层的 I/O 操作。通过它,FFmpeg 可以用统一的接口处理文件、网络流(HTTP, RTMP, TCP)、内存缓冲区等。
- 关键点: 它使得上层的格式层(解复用)无需关心数据是从哪里来的。这对于播放网络直播流或处理内存中的媒体数据至关重要。
1.2 容器层 / 格式层 (Container/Format Layer)
格式层处理多媒体容器(也叫封装格式),如 MP4、MKV、FLV、MP3 等。容器的作用是将不同的媒体流(视频、音频、字幕)打包在一起,并包含元数据。
- 核心数据结构:AVFormatContext
- 功能: 代表一个已打开的多媒体文件或流的上下文。它是格式处理的中枢,包含了容器的所有全局信息。
- 重要成员:
1pb (AVIOContext*): 指向底层的 I/O 上下文。 2streams (AVStream**): 一个数组,包含了容器中所有流的信息。 3nb_streams: 流的数量。 4duration: 容器总时长。 5bit_rate: 容器总比特率。 6metadata: 元数据(如标题、作者)。 7
1.3 编解码层 (Codec Layer)
音视频编码,即压缩和解压缩。例如,将 H.264 码流解码为原始的 YUV 图像,或将 PCM 音频编码为 AAC。
- 核心数据结构:AVCodecContext
- 功能: 为一个编解码操作提供完整的上下文。它设置了所有参数,并保持编解码过程的状态。
- 重要成员:
1codec (AVCodec*): 指向具体的编解码器实现。 2width, height: 视频的宽高。 3pix_fmt: 视频像素格式(如 YUV420P)。 4sample_rate: 音频采样率。 5channel_layout: 音频声道布局。 6sample_fmt: 音频采样格式。 7time_base: 该编解码上下文使用的时间基。 8
- 核心数据结构:AVCodec
- 功能: 描述一种编解码器的静态能力,它本身是无状态的。例如 “libx264” 编码器或 “aac” 解码器。
- 功能: 定义了编解码器的名称、类型、支持的 ID 等。
1.4 数据流转层 (Data Layer)
实际音视频数据的载体,分为压缩数据和原始数据。
- 核心数据结构:AVPacket
- 功能: 存储压缩的(已编码的)数据。
- 来源/去向: 从 AVFormatContext 读取,或向其写入。
- 重要成员:
1data: 指向压缩数据的指针。 2size: 数据大小。 3pts / dts: 显示时间戳 / 解码时间戳。 4stream_index: 它属于哪个流。 5pos: 在流中的字节位置。 6
- 核心数据结构:AVFrame
- 功能: 存储原始的(未压缩的)音频或视频数据。
- 来源/去向: 传递给解码器得到 AVFrame,或传递给编码器消耗 AVFrame。
- 重要成员(Video):
1data[]: 指针数组,指向图像平面(如 YUV 数据)。 2linesize[]: 每个图像平面的行字节数。 3width, height: 图像的宽高。 4format: 像素格式(对应 AVPixelFormat)。 5
- 重要成员(Audio):
1data[]: 指针数组,指向音频数据。 2nb_samples: 每个通道的采样数。 3sample_rate: 采样率。 4format: 采样格式(对应 AVSampleFormat)。 5channel_layout: 声道布局。 6
FFmpeg 对应结构体在各个层级显示如下所示:
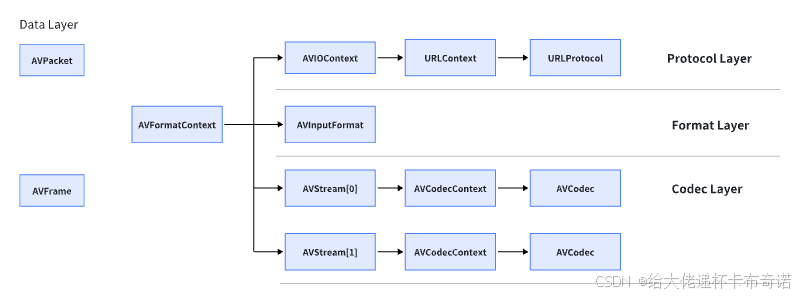
2、AVFormatConext 定义
AVFormatContext 是 FFmpeg 格式(Format)I/O 的抽象核心。你可以把它理解为一个多媒体容器文件的“句柄”或“控制器”。AVFormatContext是一个贯穿全局的数据结构,ffmpeg中对它的注视是 format I/O Context,此结果包含了一个视频流的格式内容,其中有AVInputFormat、AVOutputFormat、但是同一时间AVFormatContext只存在他们其中的一个,AVStream、AVPacket,这几个比较重要的数据结构,以及一些其他的信息,比如titile、author、copyright等,另外还有一些编码用到的信息duration、file_size、bit_size等。
AVFormatContext。
- 代表了你打开的一个媒体文件(或网络流)。
- 包含了该媒体文件的全局信息和所有元数据。
- 持有解复用器(Demuxer)或复用器(Muxer),并通过它们来读写数据。
AVF
《FFmpeg 基本数据结构 AVFormatConext 分析》 是转载文章,点击查看原文。

