目录
一、背景知识
1.1 概念
1.2 负载均衡类型选择
1.3 核心功能与工作原理
1.4 配置负载均衡的注意事项
二、传统型负载均衡CLB的使用示例
2.1 创建3个ECS实例
2.2 安装nginx
2.3 创建负载均衡CLB
2.4 负载均衡配置
2.5 负载均衡检验
一、背景知识
1.1 概念
阿里云负载均衡能将访问流量分发到后端多台云服务器上,提升应用系统的服务能力和高可用性。它主要包含以下三种产品:
| 特性维度 | CLB(传统型负载均衡) | ALB(应用型负载均衡) | NLB(网络型负载均衡) |
|---|---|---|---|
| 产品定位 | 基础的四层和七层负载均衡服务 | 专注于HTTP、HTTPS、QUIC等应用层场景,是阿里云官方云原生Ingress网关 | 面向万物互联时代的四层负载均衡,主打超高性能 |
| 协议支持 | TCP、UDP、HTTP、HTTPS | HTTP、HTTPS、QUIC、gRPC | TCP、UDP、TCPSSL |
| 关键性能 | 基础负载均衡能力 | 单实例最高100万 QPS | 单实例1亿并发连接,100 Gbps带宽 |
| 核心特性 | 健康检查、会话保持、域名转发(七层) | 基于内容的高级路由(路径、头域等)、重定向/重写、TLS 1.3 | 自动弹性伸缩、TCP SSL卸载、新建连接限速 |
| 典型场景 | 常规Web应用,基础协议转发 | 微服务、云原生应用、大型网站 | 物联网(IoT)、视频直播、高并发业务 |
1.2 负载均衡类型选择
- 需要处理HTTP/HTTPS高级路由:如果业务基于HTTP/HTTPS协议,且需要根据路径、域名、Cookie等复杂规则进行路由转发,或者业务是微服务架构,ALB是最佳选择。
- 追求极高的四层性能:如果业务是物联网、视频直播、游戏等需要超高性能的场景,需要处理海量TCP/UDP连接,NLB的单实例1亿并发连接能力能轻松应对。
- 通用或基础负载均衡需求:如果业务协议简单(如TCP、HTTP),不需要复杂路由,且对性能没有极端要求,CLB是一个经济可靠的选择。
1.3 核心功能与工作原理
- 高可用与容灾:负载均衡采用集群部署,支持多可用区容灾。当主可用区故障时,会自动切换到备可用区,保障服务连续性。结合全局流量管理,还可实现跨地域的异地容灾。
- 健康检查:负载均衡会定期检查后端服务器的运行状况。一旦发现异常,会停止向该服务器分发流量,确保请求只被转发到健康的服务器。
- 会话保持:通过会话保持功能,可以将来自同一客户端的请求在一段时间内始终转发到同一台后端服务器,这对于需要保持登录状态的应用至关重要。
- 流量路径:客户端请求首先到达负载均衡集群。对于四层协议,负载均衡集群会直接将请求转发给后端ECS;对于七层协议,请求会先被负载均衡集群转发到七层集群(如Tengine),再根据更精细的规则(如域名、URL)分发到后端ECS。
1.4 配置负载均衡的注意事项
- 地域选择:为确保低延迟,负载均衡实例必须与后端ECS服务器处于同一地域,且不支持跨地域部署。
- 类型规划:根据业务需求确定是创建公网实例(对外提供服务)还是私网实例(内部网络访问)。公网实例需要选择带宽计费方式。
- 后端服务器准备:建议将后端服务器部署在不同的可用区内,以实现跨可用区容灾。同时,确保服务器上已部署好应用程序。
二、传统型负载均衡CLB的使用示例
2.1 创建3个ECS实例
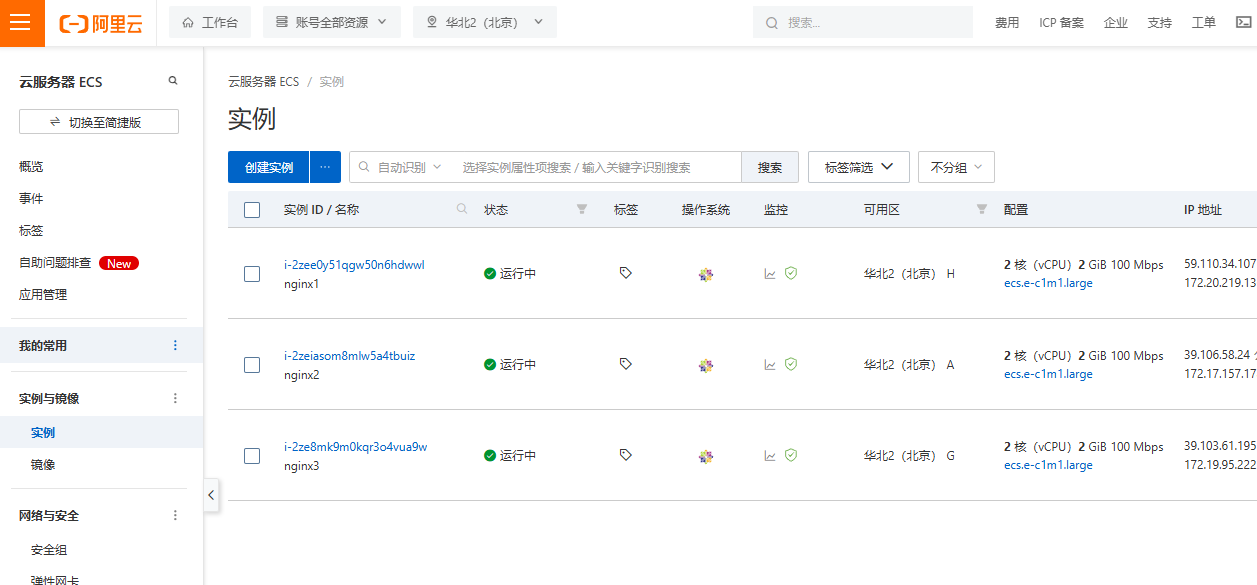
2.2 安装nginx
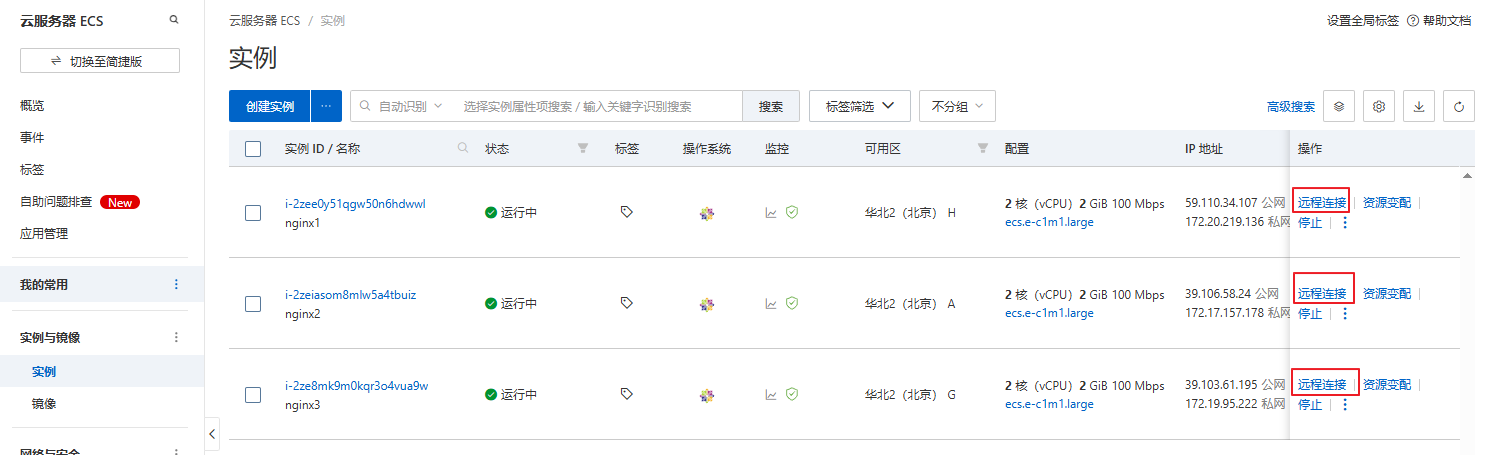
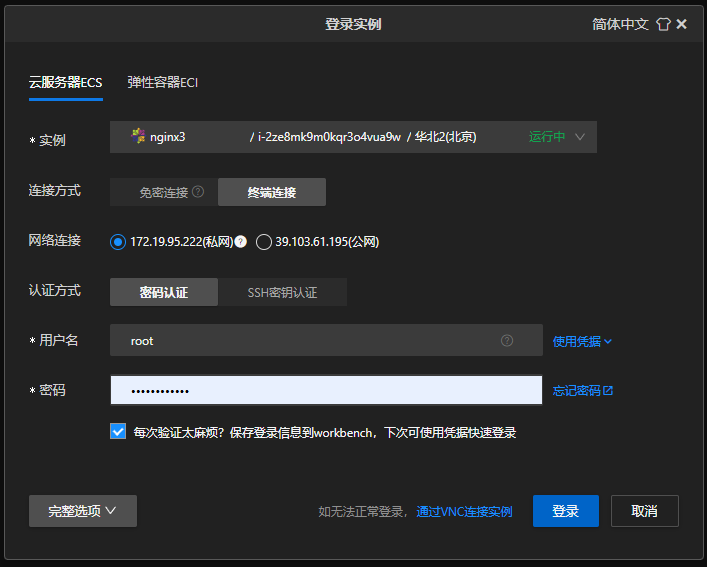
下载nginx:
启动nginx:
systemctl restart nginx
查看nginx是否启动:scd

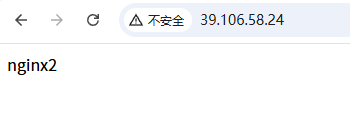
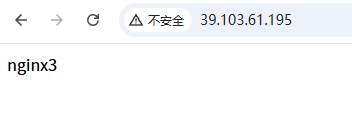
外网页面访问:
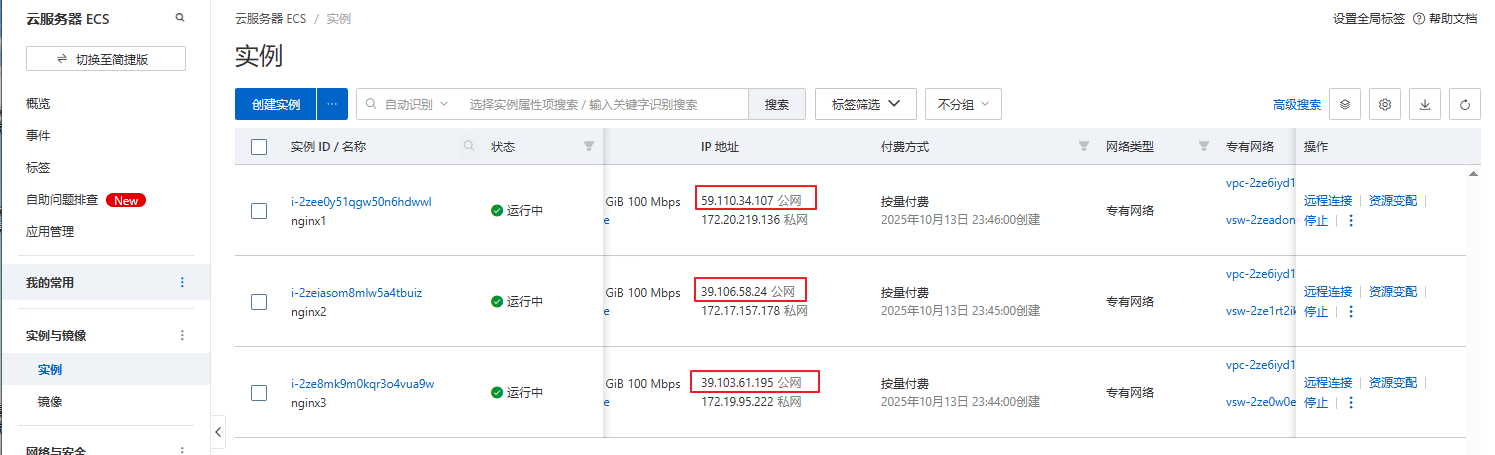
访问路径:http://39.106.58.24/
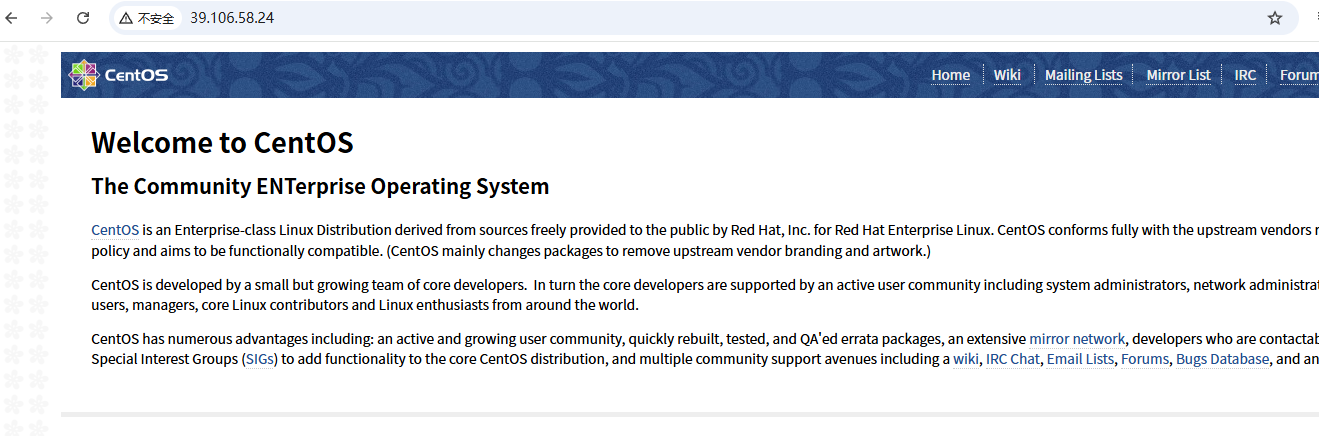
查看默认访问页面路径:
vim /etc/nginx/nginx.conf
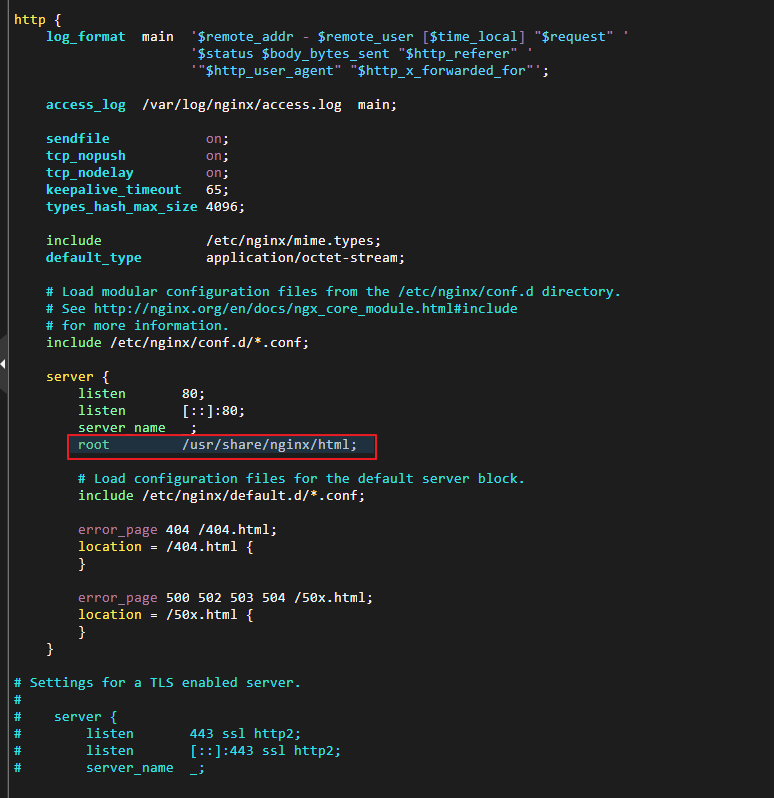
更改默认访问页面内容:nginx1、nginx2、nginx3
1cd /usr/share/nginx/html 2echo nginx1 > index.html
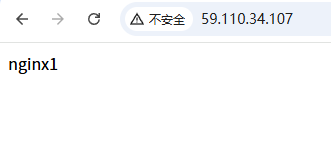
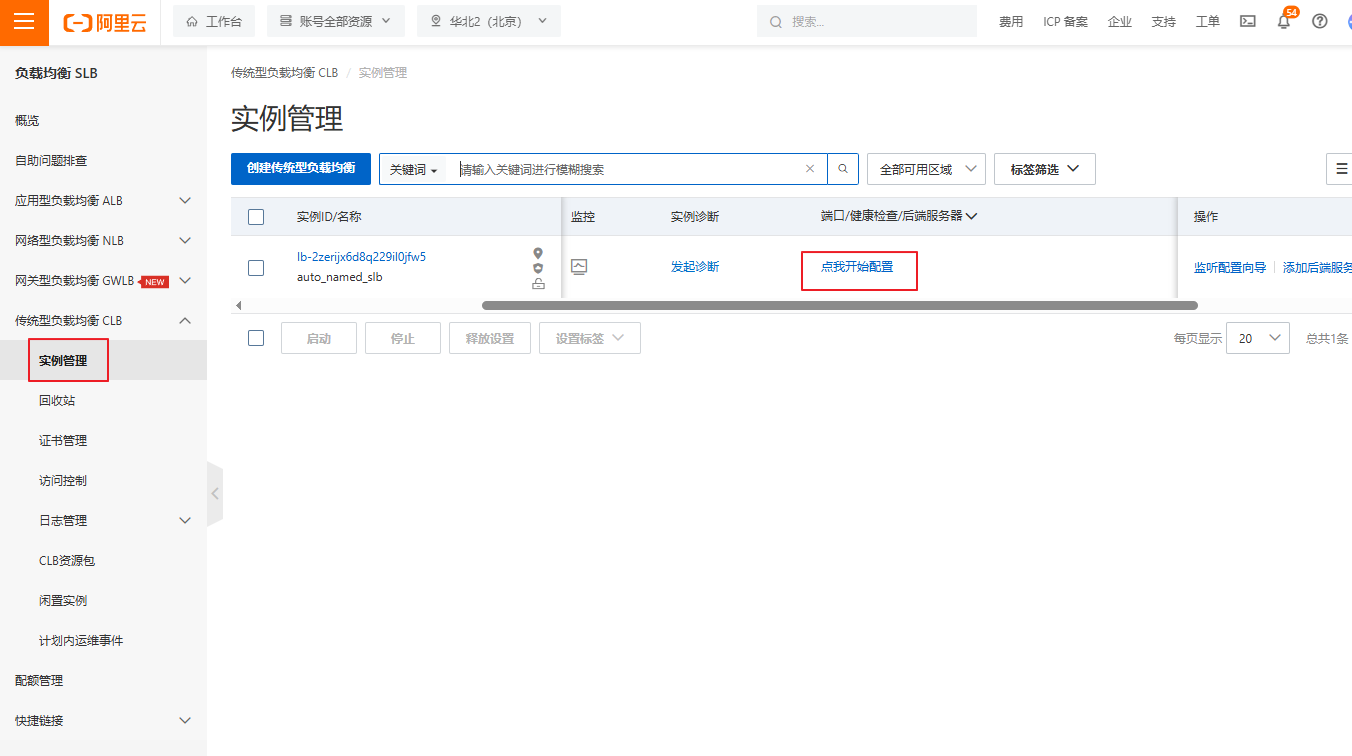
2.3 创建负载均衡CLB
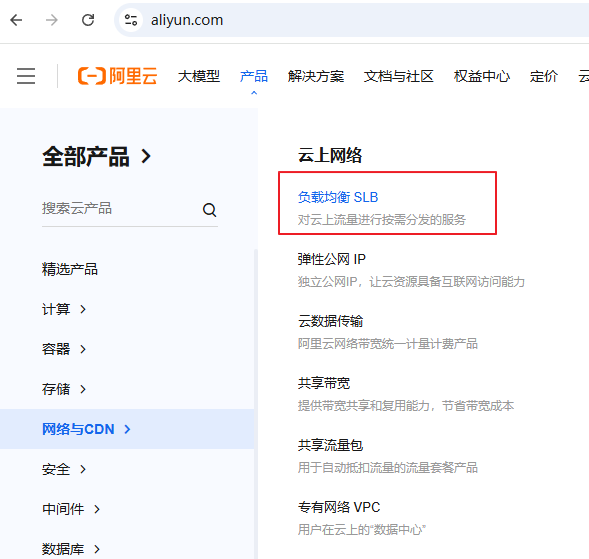
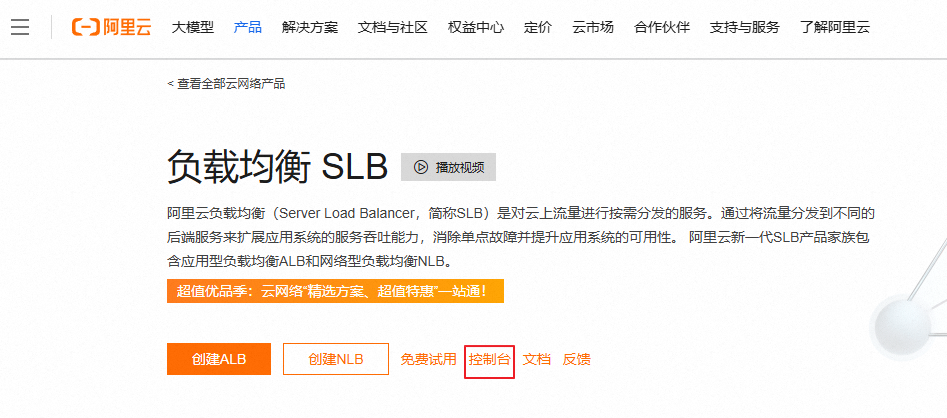
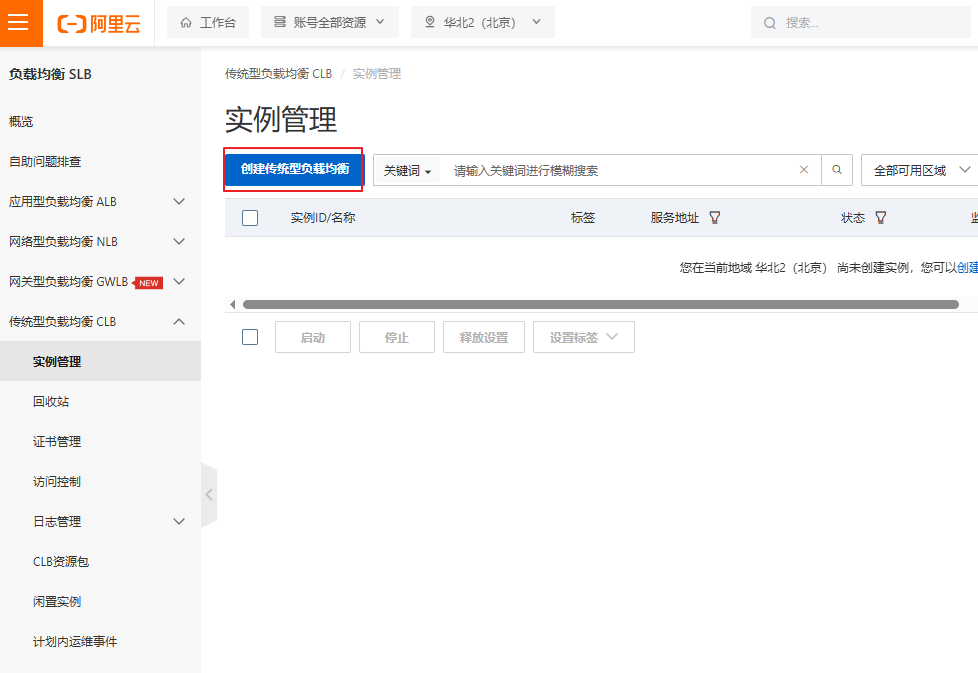
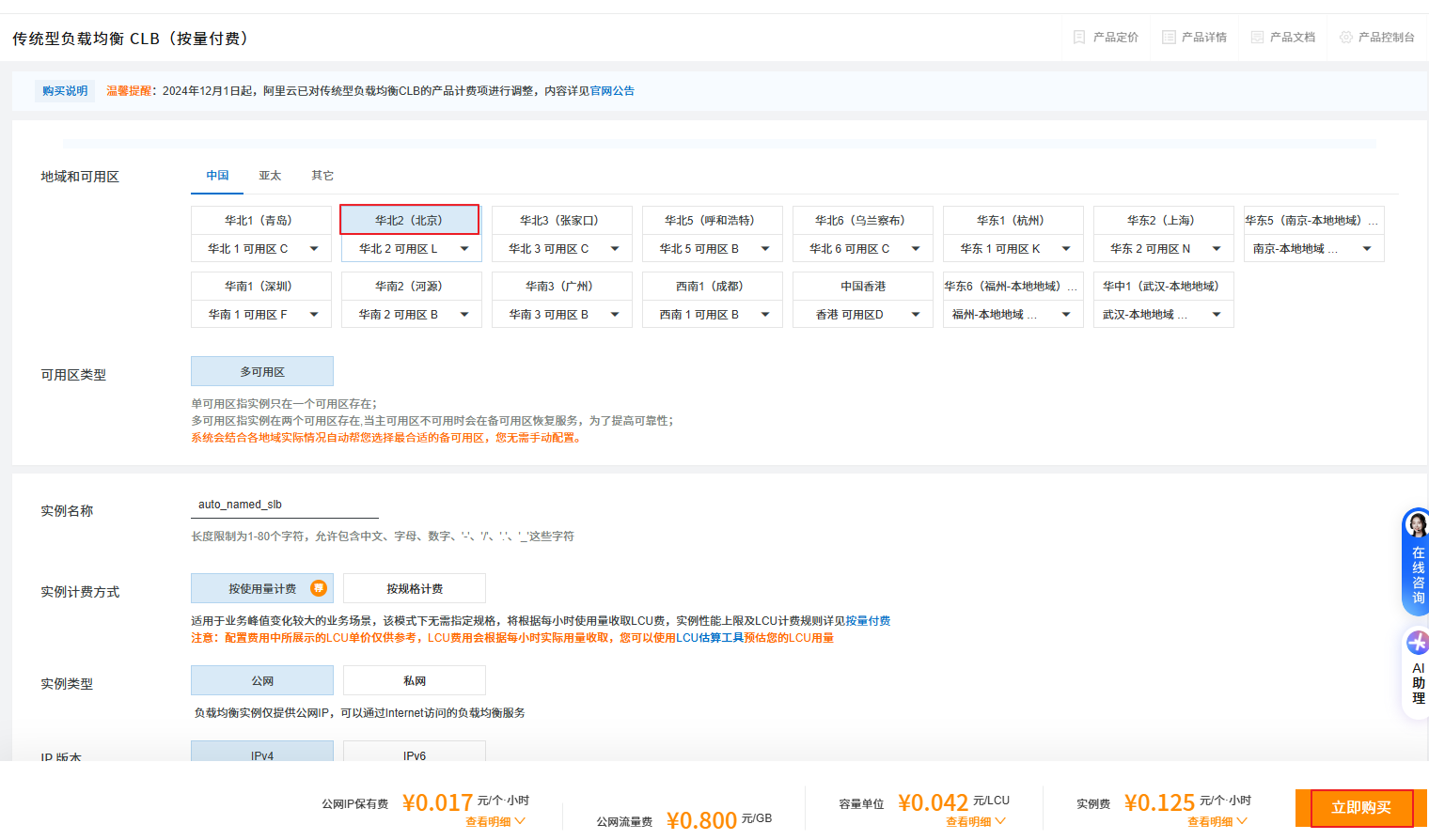
注意:这里的地域应该与ECS的地域相同
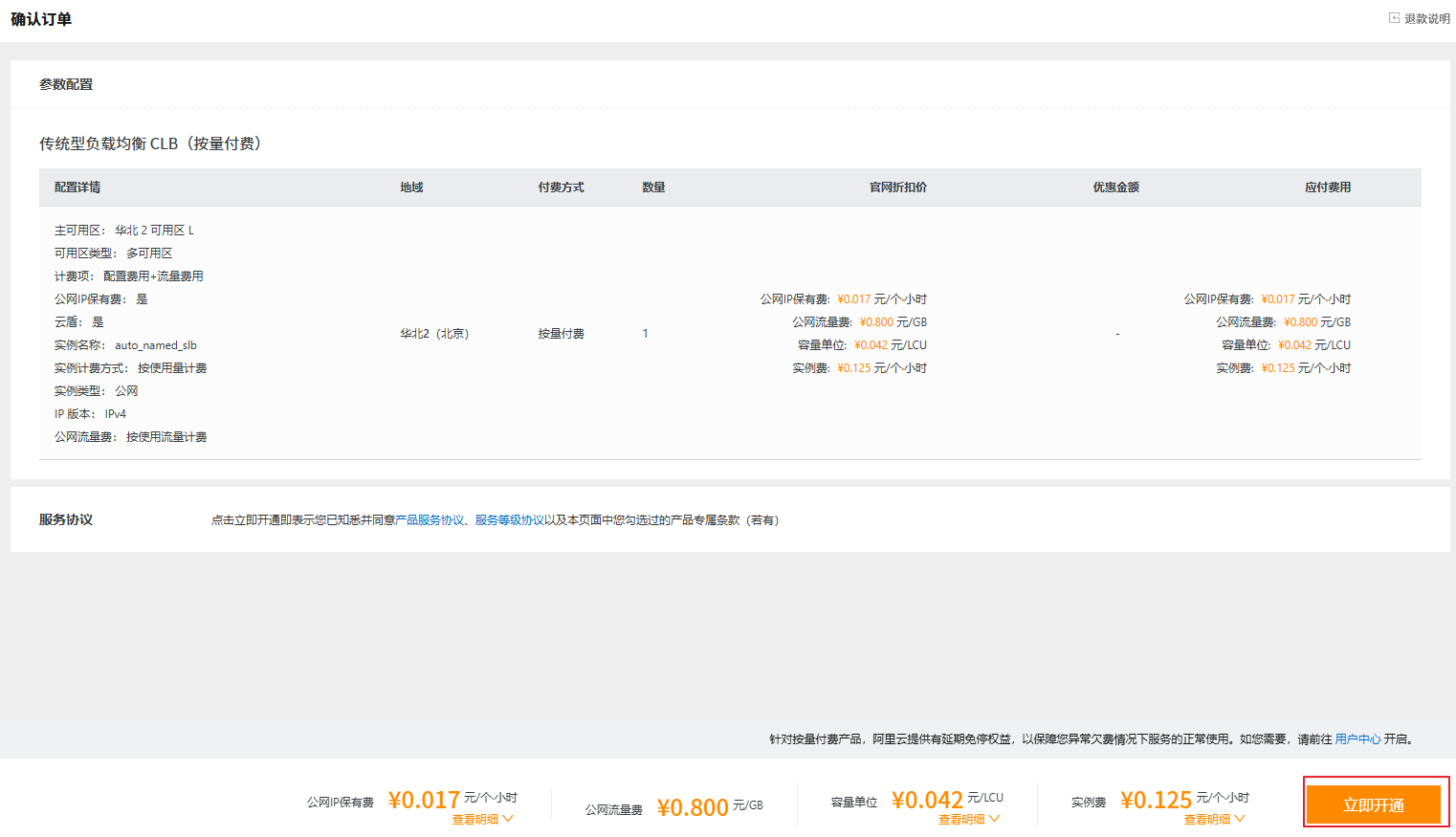
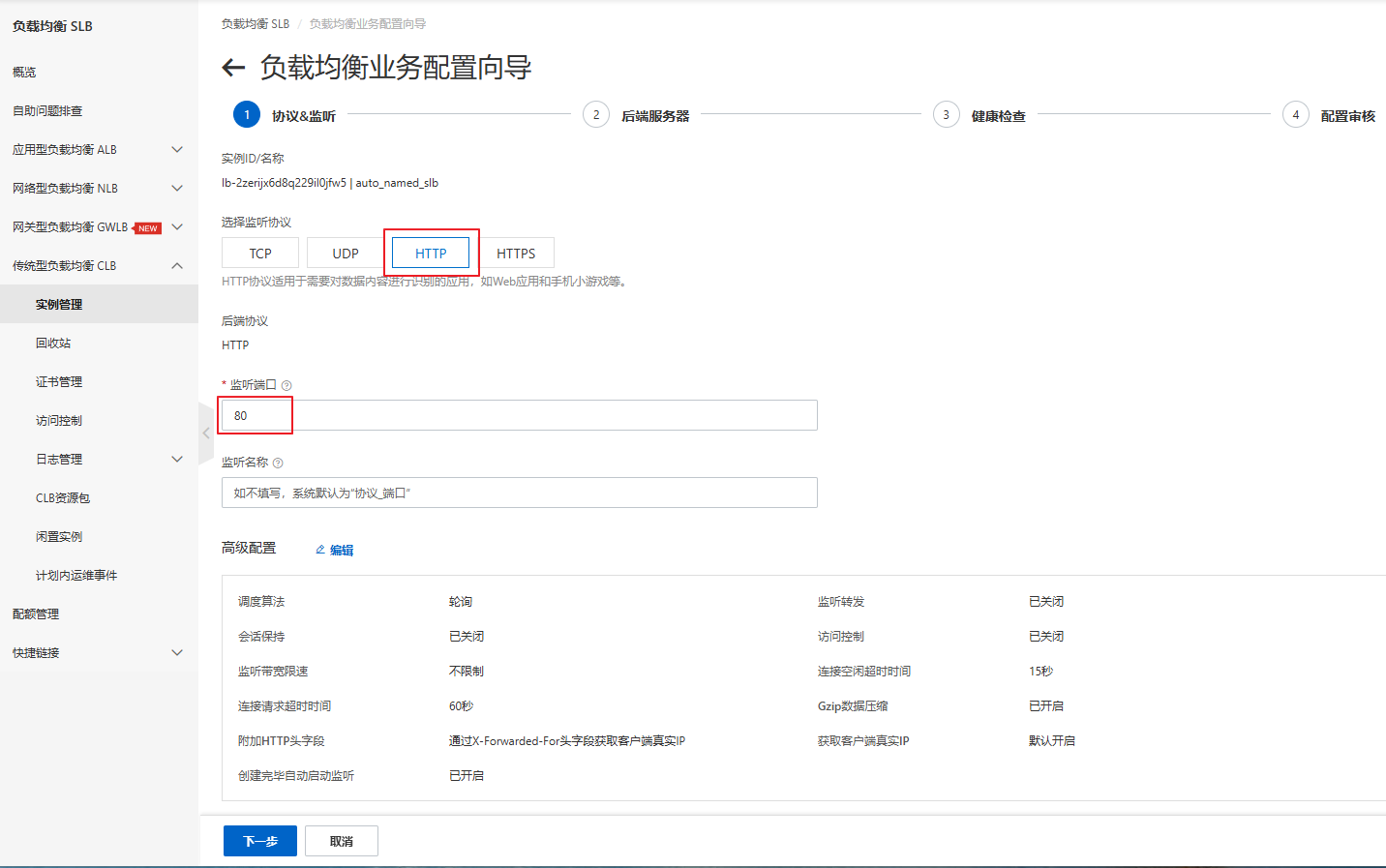
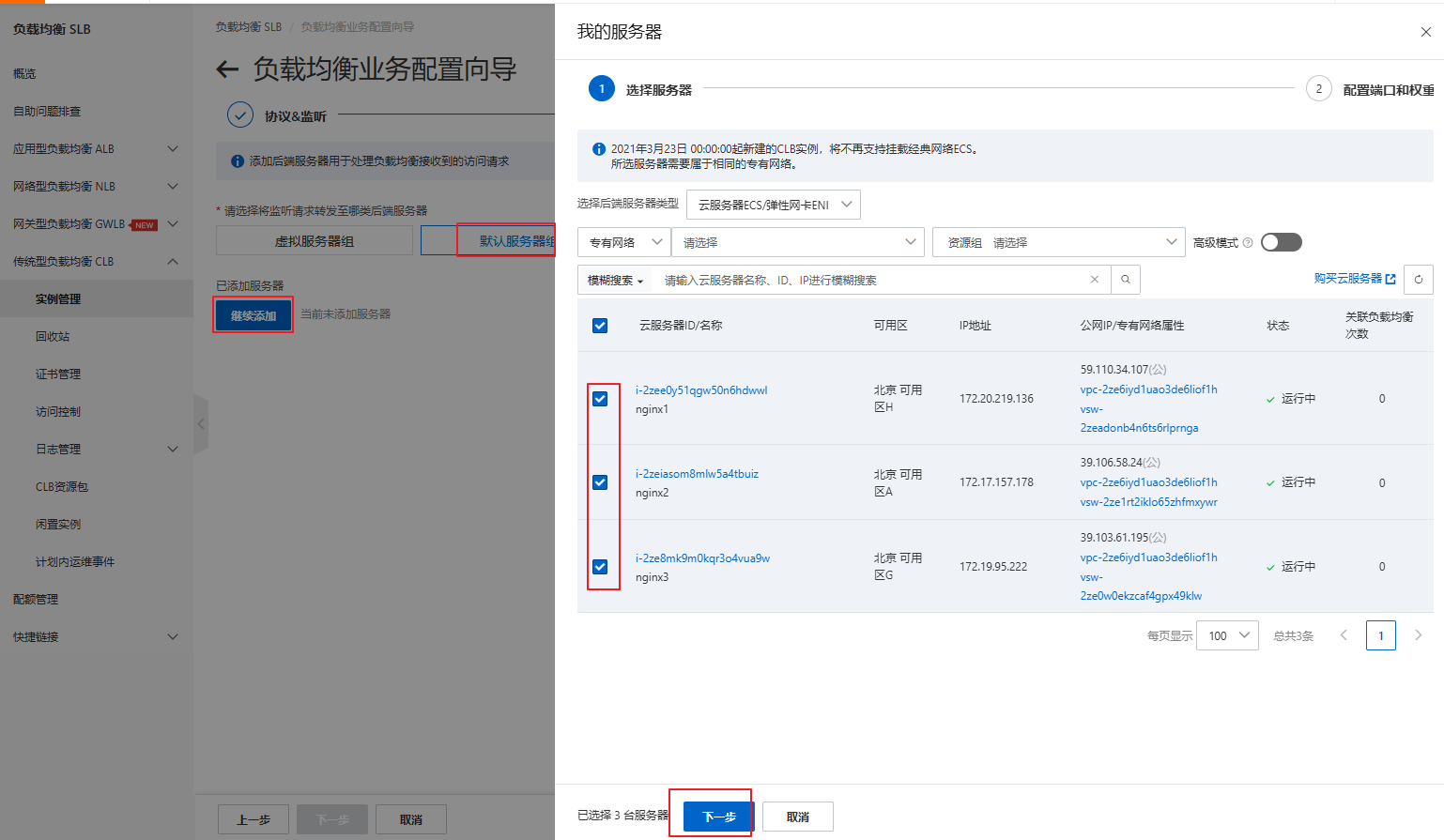
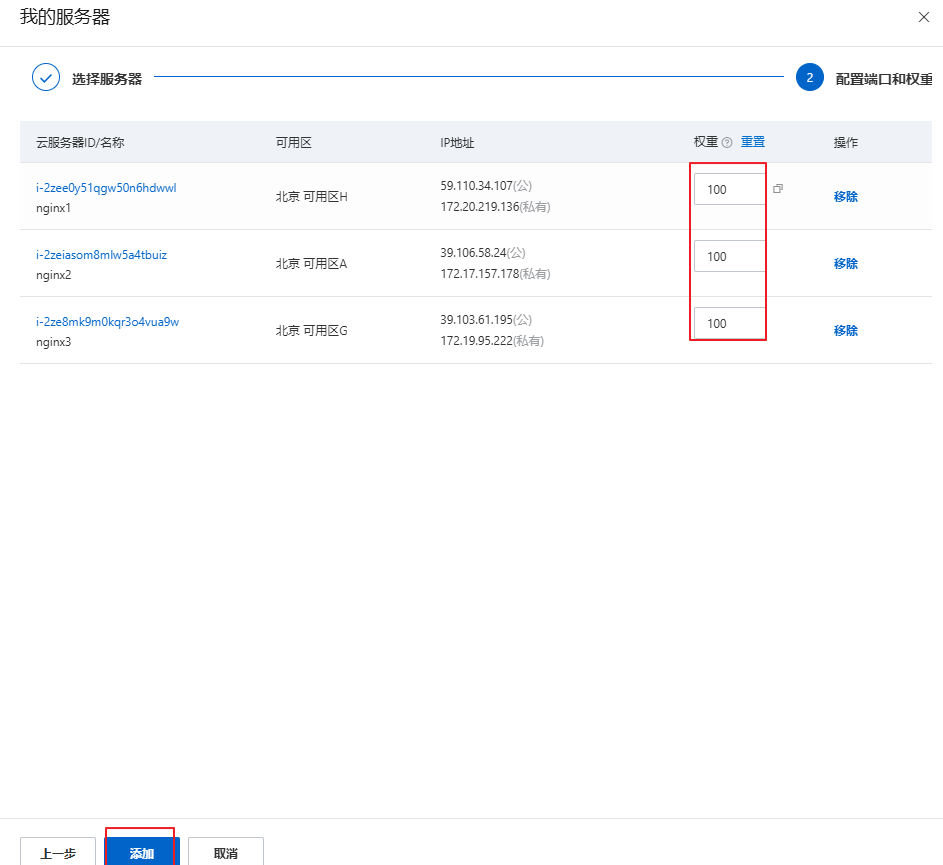
2.4 负载均衡配置
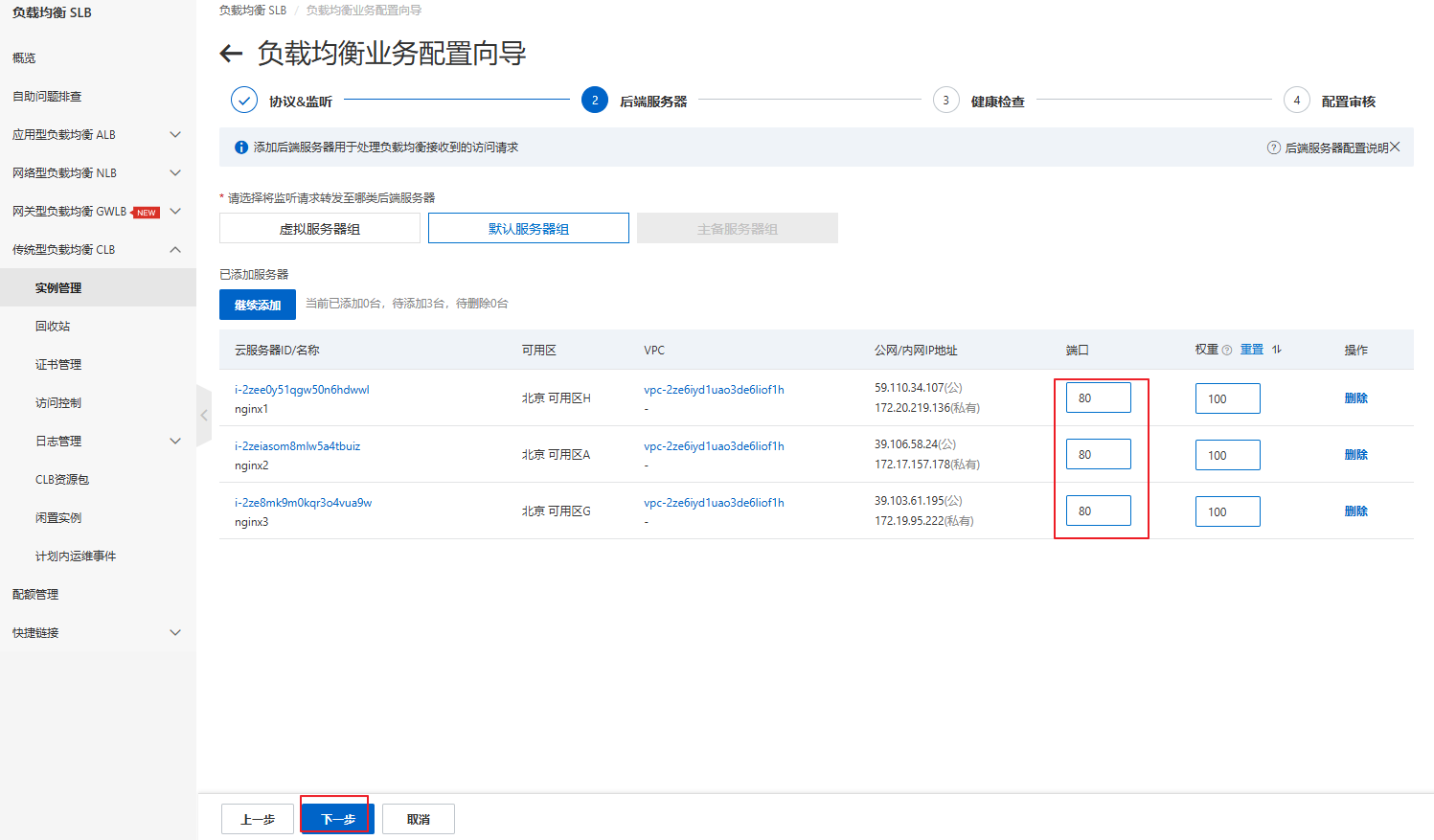
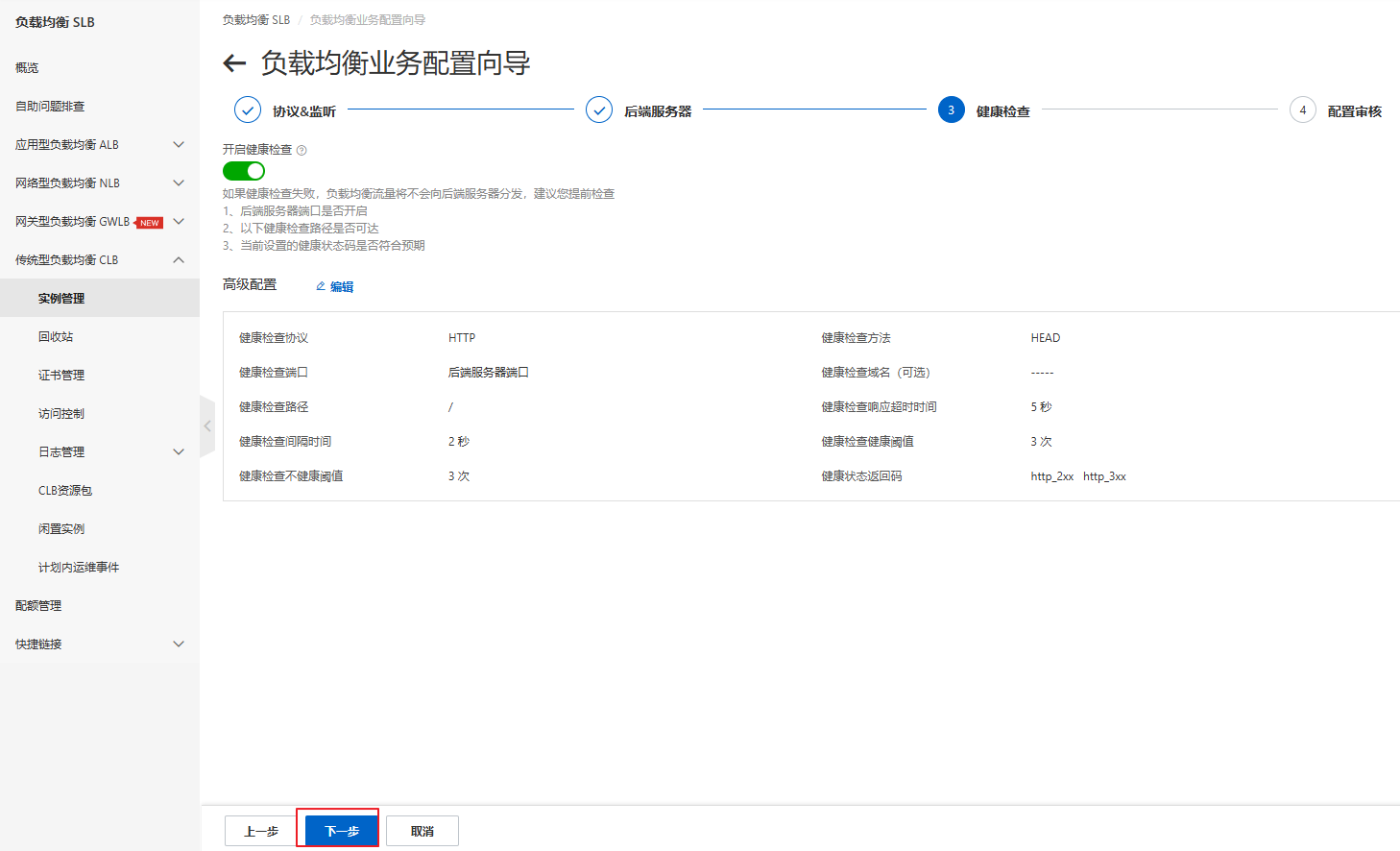
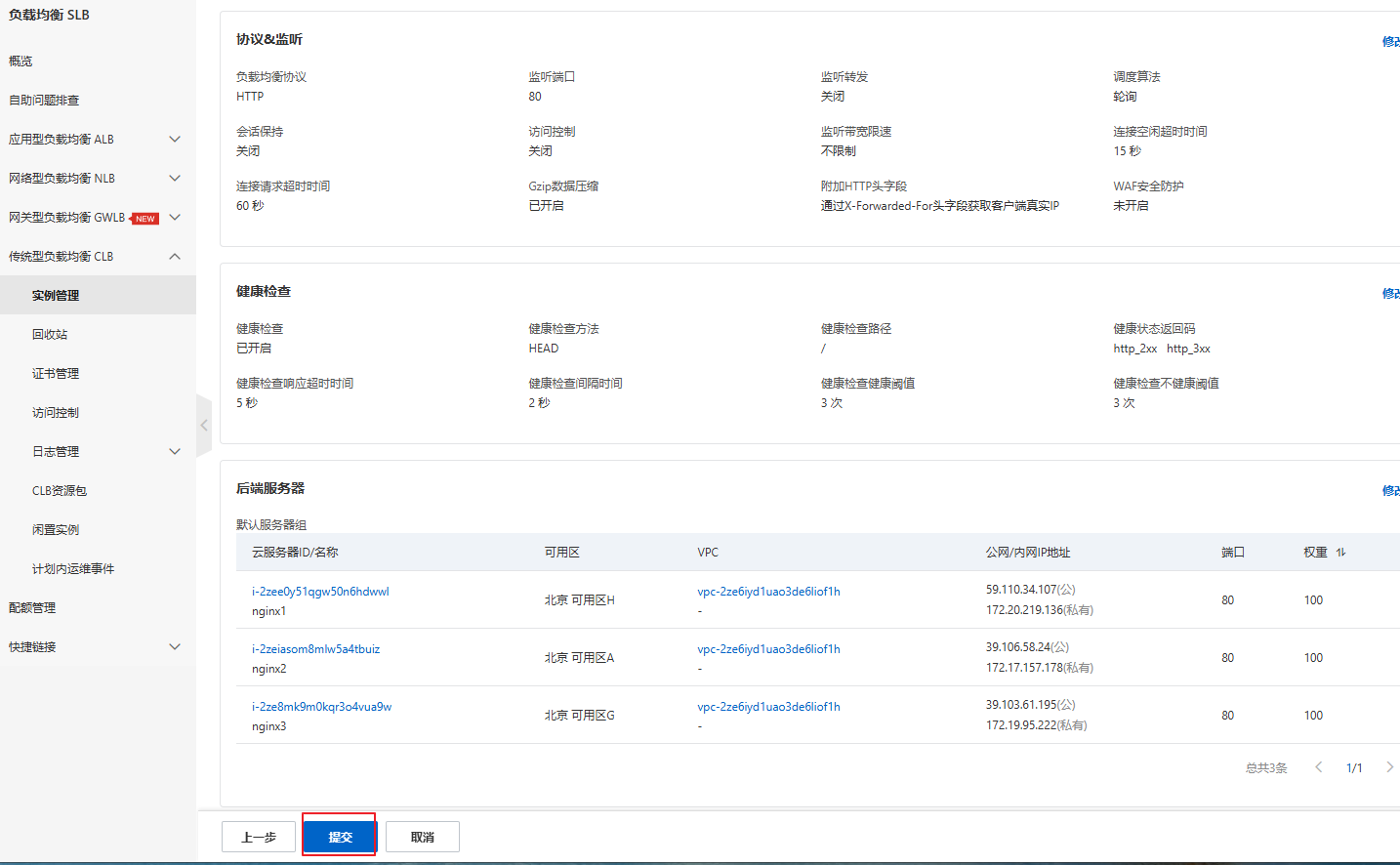
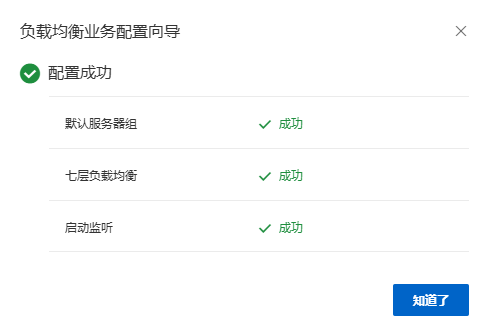
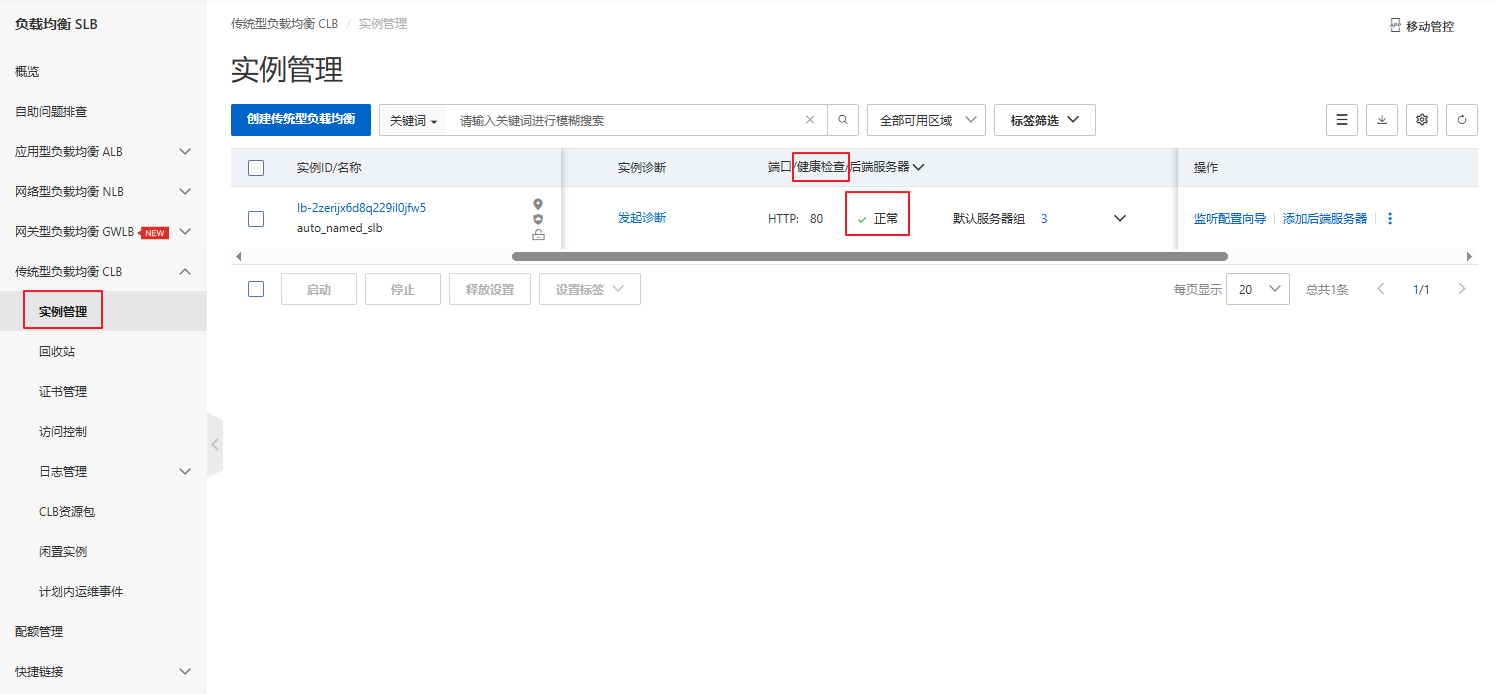
2.5 负载均衡检验
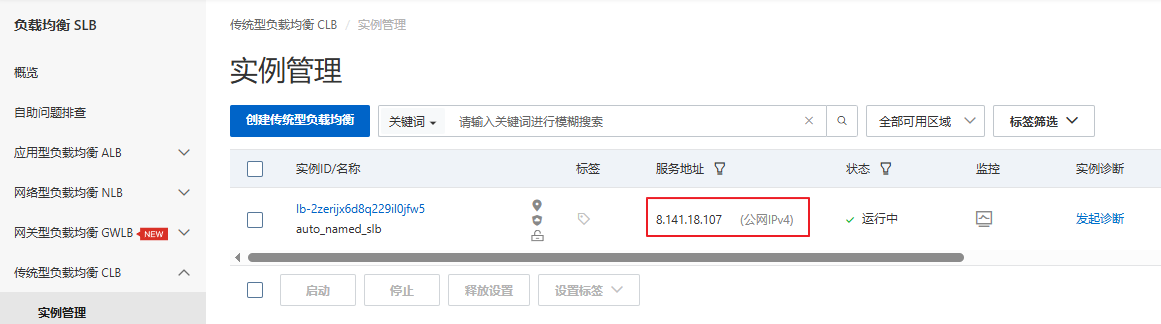
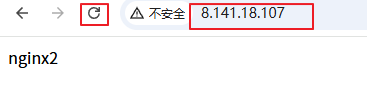
通过刷新,会发现页面在变。
《阿里云负载均衡SLB的使用参考:创建阿里云ECS实例操作》 是转载文章,点击查看原文。

